Friday, 26 April 2024
A fast fileserver with FreeBSD, NVMEs, ZFS and NFS
I have a small server running in my flat that serves files locally via NFS and remotely via Nextcloud. This post documents the slightly overpowered upgrade of the hardware and subsequent performance / efficiency optimisations.
TL;DR
- I can fully saturate a 10Gbit LAN connection, achieving more than 1100 MiB/s throughput.
- I can perform a
zpool scrubwith 11 GiB/s, completing a 6.8TiB scrub in 11min. - Idle power usage can be brought down to 34W.
Old setup and requirements
What the server does:
- Serve files via NFS to
- my workstation (high traffic)
- a couple of Laptops (low traffic)
- the TV running Kodi (medium traffic)
- Host a Nextcloud which provides file storage, PIM etc. for a handful of people
Not a lot of compute is necessary, and I have tried to keep power usage low. The old hardware served me well really long:
- AMD 630 CPU
- 16GiB RAM
- 2+1 * 4TiB spinning disk RAIDZ1 with SSD ZIL (“write-cache”)
The main pain point was slow disk access resulting in poor performance when large files were read by the Nextcloud. Browsing through my photo collection via NFS was also very slow, because thumbnail generation needed to pull all the images. Furthermore, low speed meant that I was not doing as much on the remote storage as I would have liked (e.g. storing games), resulting in my workstation’s storage always running out. And I was just reaching the limits of my ZFS pool anyway, so it was time for an upgrade!
New setup
To get better I/O, I thought about switching from HDD to SSD, but then realised that SSD performance is very low compared to NVME performance, although the price difference is not that much. Also, NFS+ZFS leads to quite a bit of I/O, typically requiring the use of faster caching devices, further complicating the setup. Consequently, I decided to go for a pure NVME setup. Of course, the new server would also need 10GBit networking, so that I can use all that speed in the LAN!

This is the new hardware! I will discuss the details below.
Mainboard, CPU and RAM
The main requirement for the mainboard is to offer connectivity for four NVME disks. And to be prepared for the future, I would actually like 1-2 extra NVME slots. There are two ways to attach NVMEs to a motherboard:
- directly (“natively”)
- via an extension card that is plugged into a PCIexpress slot
Initially, I had assumed no mainboard would offer sufficient native slots, so I did a lot of research on option 2. The summery: it is quite messy. If you want to use a single extension card that hosts multiple NVMEs (which is required in this case), you need so called “bifurcation support” on the mainboard. This lets you e.g. put a PCIe x8 card with two NVME 4x disks into a PCIe 8x slot on the mainboard. However, this feature is really poorly documented,1 and and varies between mainboard AND CPU whether they support no bifurcation, only 8x → 4x4x or also 16x → 4x4x4x4x. The different PCIe versions and speeds, and the difference between the actually supported speed and the electrical interface add further complications.
In the end, I decided to not do any experiments and look for a board that natively supports a high number of NVME slots. For some reasons, this feature is very rare on AMD mainboards, so I switched to Intel (although actually I am a bit of an AMD fanboy). I probably could have gone with a board that has 5 slots, but I use hardware for a long time and wanted to be safe, so I took board that has 6 NVME slots (2 free slots):

None of the available boards had a proper2 10GBit network adaptor, so having a usable PCIe slot for a dedicated card was also a requirement. It is important to check whether PCIe slots can still be used when all NVME slots are occupied; sometimes they internally share the bandwidth. But for the above board this is not the case.
Important: To be able to boot FreeBSD on this board, you need to add the following to /boot/device.hints:
hint.uart.0.disabled="1"
hint.uart.1.disabled="1"
For the CPU, I just went with something on the low TDP end of the current Intel CPU range, the Intel Core i3-12100T. Four cores + four threads was exactly what I was looking for, and 35W TDP sounded good. I paired that with some off-the-shelf 32GiB RAM kit.
Case, power supply & cooling
Strictly speaking a 2U case would have been sufficient, but I thought a 3U case might offer better air circulation. I ended up with the Gembird 19CC-3U-01. For unknown reasons, I chose a 2U horizontal CPU fan, instead of a 3U one. The latter would definitely have provided better airflow, but since the fan barely runs at all, it doesn’t make much of a difference.
I was unsuccessful in finding a good PSU that is super efficient in the average case of around 40W power usage but also covers spikes well above 100W, so I just chose the cheapest 300W one I could get :)

The case with everything in place.
The built in fans are very noisy. I chose to replace one of the intake fans with a spare one I had lying around and only connect one of the rear outtake fans. But I added an extra fan where the extension slots are to divert some airflow around the NIC—which otherwise gets quite warm. This should also blow some air over the NVME heatsinks! All fans can be regulated and fine-tuned from the BIOS of the mainboard which I totally recommend you do. At the current temperatures and average workloads the whole setup is almost silent.
Storage
Now, the fun begins. Since I needed more space than before, I clearly want a 3+1 x 4TiB RAIDZ1.
My goal was to be able to saturate a 10GBit connection (so get around 1GiB/s throughput) and still have the server be able to serve the Nextcloud without slowing down significantly. Currently the WAN upload is quite slow, but I hope to have fibre in the future. In any case, I thought that any modern NVME should be fast enough, because they all advertise speeds of multiple GiB/s.
Choice of disks
Anyway, I got two Crucial P3 Plus 4TB (which were on sale at Amazon for ~190€), as well as two Lexar NM790 4TB (which were also a lot cheaper than they are now). My assumption that that they were very comparable, was very wrong:
| Disk | IOPS rand-read | IOPS read | IOPS write | MB/s read | MB/s write | “cat speed” MB/s |
|---|---|---|---|---|---|---|
| Crucial | 53,500 | 794,000 | 455,000 | 2,600 | 4,983 | ~700 |
| Lexar | 53,700 | 796,000 | 456,000 | 4,578 | 5,737 | ~2,700 |
I used this fellow’s fio-script to
generate all columns except the last. The last column was generated by simply cat’ing a 10GiB file of random numbers to /dev/null which
roughly corresponds to the read portion of copying a 4k movie file.
Since I had two disks each, I actually took the time to test all of them in different mainboard slots, but the results
were very consistent: in real-life tasks, the Crucial disk underperformed significantly, while the Lexar disks were
super fast.
I decided to return the Crucial disks and get two more by Lexar 😎
Disk encryption
I always store my data encrypted at rest. FreeBSD offers GELI block-level encryption (similar to LUKS on Linux). But OpenZFS also provides a dataset/filesystem-level encryption since a while. I previously used GELI, but I wanted to switch to ZFS native encryption, because it provides some advantages:
- Flexibility: I can choose later which datasets to encrypt; I can encrypt different datasets with different keys.
- Zero-knowledge backups: I can send incremental backups off-site that are received and fully integrated into the target pool without that server ever getting the decryption keys.
- Forward-compatibility: I can upgrade to better encryption algorithms later.
- Linux-compatibility: I can import the existing pool in a Linux environment for debugging or benchmarking.
However, I had also heard that ZFS native encryption was slower, so I decided to do some benchmarks:
| Disk | IOPS rand-read | IOPS read | IOPS write | MB/s read | MB/s write | “cat speed” MB/s |
|---|---|---|---|---|---|---|
| no encryption | 54,700 | 809,000 | 453,000 | 4,796 | 5,868 | 2,732 |
| geli-aes-256-xts | 40,000 | 793,000 | 446,000 | 3,332 | 3,334 | 952 |
| zfs-enc-aes-256-gcm | 26,100 | 513,000 | 285,000 | 3,871 | 4,648 | 2,638 |
| zfs-enc-aes-128-gcm | 29,300 | 532,000 | 353,000 | 3,971 | 4,794 | 2,631 |
Interestingly, GELI3 performs much better on the IOPS, but much worse on throughput, especially on our real-life test case. Maybe some smart person knows the reason for this, but I took this benchmark as an assurance that going with native encryption was the right choice.4 One reason for the good performance of the native encryption seems to be that it makes use of the CPU’s avx2 extensions.
At this point, I feel like I do need to warn people about some ZFS encryption related issues that I learned about later. Please read this. I have had no problems to date, but make up your own mind.
RaidZ1
| recordsize | compr. | encrypt | IOPS rand-read | IOPS read | IOPS write | MB/s read | MB/s write | “cat speed” MB/s |
|---|---|---|---|---|---|---|---|---|
| 128 KiB | off | off | 50,000 | 869,000 | 418,000 | 3,964 | 5,745 | 2,019 |
| 128 KiB | on | off | 49,800 | 877,000 | 458,000 | 3,929 | 4,654 | 1,448 |
| 128 KiB | off | aes128 | 26,300 | 484,000 | 230,000 | 3,589 | 5,331 | 2,142 |
| 128 KiB | on | aes128 | 27,400 | 501,000 | 228,000 | 3,510 | 3,927 | 2,120 |
These are the numbers after creation of the RAIDZ1 based pool. They are quite similar to the numbers measured before.
The impact of encryption on IOPS is clearly visible, less so on sequential read/write throughput.
Compression seems to impact write throughput but not read throughput which is expected for zstd. It is unclear why
“cat speed” is lower here.
| recordsize | compr. | encrypt | IOPS rand-read | IOPS read | IOPS write | MB/s read | MB/s write | “cat speed” MB/s |
|---|---|---|---|---|---|---|---|---|
| 1 MiB | off | off | 7,235 | 730,000 | 404,000 | 3,686 | 3,548 | 2,142 |
| 1 MiB | on | off | 7,112 | 800,000 | 470,000 | 3,624 | 3,447 | 2,064 |
| 1 MiB | off | aes128 | 3,259 | 497,000 | 258,000 | 3,029 | 3,422 | 2,227 |
| 1 MiB | on | aes128 | 3,697 | 506,000 | 249,000 | 3,137 | 3,361 | 2,237 |
Many optimisation guides suggest setting the zfs recordsize to 1 MiB for most use-cases, especially storage of media
files.
But this seems to drastically penalise random read IOPS while providing little to no benefit in the sequential
read/write scenarios. This is actually a bit surprising and I will need to investigate this more.
Is it perhaps because NVMEs are good at parallel access and therefor suffer less from fragmentation anyway?
In any case, the main take away message is that overall read and write throughputs are over 3,000 MiB/s in the synthetic case and over 2,000 MiB/s in the manual case, which is great.
Other disk performance metrics
| Operation | Speed [MiB/s] |
|---|---|
| Copying 382 GiB between two datasets (both enc+comp) | 1,564 |
| Copying 505 GiB between two datasets (both enc+comp) | 800 |
zfs scrub of the full pool |
11,000 |
These numbers further illustrate some real world use-cases. It’s interesting to see the difference between the first two, but it’s also important to keep in mind that this is reading and writing at the same time. Maybe some internal caches are exhausted after a while? I didn’t debug these numbers further, but I think the speed is quite good after such a long read/write.
More interesting is the speed for scrubbing, and, yes, I have checked this a couple of times. A scrub of 6.84TiB happens in 10m - 11m, which is pretty amazing, I think, considering that it is reading the data and calculating checksums. I am assuming that sequential read is just very fast and that access to the different disks happens in parallel. The checksum implementation is apparently also avx2 optimised.
LAN
Network adapter
Based on recommendations, I decided to buy an Intel card. Cheaper 10GBit network cards are available from Marvell/Aquantia, but the driver support in FreeBSD is poor, and the performance is supposedly also not close to that of Intel.
Many people suggested I go for SFP+ (fibre) instead of 10GBase-T (copper), but I already have CAT7 cables in my flat. While I could have used fibre purely for connecting the server to the switch (and this would likely save some power), I would have had to buy a new switch and the options were just not economical—I already have a switch with two 10GBase-T ports which I had bought for exactly this setup.
The cheapest Intel 10GBase-T card out there is the X540 which is quite old and available on Amazon for around 80€. I bought two of those (one for the server and one for the workstation). More modern cards are supposedly more energy efficient, but also a lot more expensive.5
NFS Performance
On server and client, I set:
kern.ipc.maxsockbuf=4737024in/etc/sysctl.confmtu 9000 media 10gbase-tin the/etc/rc.conf(ifconfig)
Only on the server:
nfs_server_maxio="1048576"in/etc/rc.conf
Only on the client:
nfsv4,nconnect=8,readahead=8as the mount options for the nfs mount.vfs.maxbcachebuf=1048576in/boot/loader.conf(not sure any more if this makes a difference).
These settings allow larger buffers and increase the amount of readahead. This favours large sequential reads/writes over small random reads/writes.
The full options on the client end up being:
# nfsstat -m
X.Y.Z.W:/ on /mnt/server
nfsv4,minorversion=2,tcp,resvport,nconnect=8,hard,cto,sec=sys,acdirmin=3,acdirmax=60,acregmin=5,acregmax=60,nametimeo=60,negnametimeo=60,rsize=1048576,wsize=1048576,readdirsize=1048576,readahead=8,wcommitsize=16777216,timeout=120,retrans=2147483647
I use NFS4 for my workstation and NFS3 for everyone else. I have performed no benchmarks on NFS3, but I see no reason why it would be slower.
| IOPS rand-read | IOPS read | IOPS write | MB/s read | MB/s write | “cat speed” MB/s |
|---|---|---|---|---|---|
| 283 | 292,000 | 33,200 | 1,156 | 594 | 1,164 |
This benchmark was performed on a dataset with 1M recordsize, encryption, but no compression.
Random read IOPS are pretty bad, and I see a strong correlation here to the rsize (if I halve it, I double the IOPS; not shown in table).
It’s possible that every 4KiB read actually triggers a 1MiB read in NFS which would explain this.
On the other hand, the sequential read and write performance is pretty good with synthetic and real world read speeds
being very close to the theoretical maximum of the 10GBit connection.
One thing to keep in mind: The blocksize when reading has a very strong impact on the performance. This
can be seen when using dd with different bs arguments. Of course, 1MiB is optimal if that is also used by NFS, and
cat seems to do this. However, cp does not which results in a much slower performance than if using dd if=.. of=.. bs=1M.
I have done measurements with plain nc over the wire (also reaching 1,160 MiB/s) and iperf3 which achieves 1,233 MiB/s just below the 1,250 MiB/s equivalent of 10Gbit.
Power consumption and thermals
For a computer running 24/7 in my flat, power consumption is of course important. I bought a device to measure power consumption at the outlet to get an accurate picture.
idle
Because the computer is idle most of the time, optimising idle power usage is most important.
| Change | W/h |
|---|---|
| default | 50 |
*_cx_lowest="Cmax" |
45 |
| disable WiFi and BT | 42 |
media 10gbase-t |
45 |
machdep.hwpstate_pkg_ctrl=0 |
41 |
| turn on chassis fans | 42 |
| ASPM modes to L0s+L1 / enabled | 34 |
I assume that the same setup on Linux would be slightly more efficient, but 34W in idle is acceptable.
Clearly, the most impactful changes were:
- Activating ASPM for the PCIe devices in the BIOS.
- Adding
performance_cx_lowest="Cmax"andeconomy_cx_lowest="Cmax"to/etc/rc.conf. - Adding
machdep.hwpstate_pkg_ctrl=0to/boot/loader.conf.
You can find online resources on what these options do. You might need to update the BIOS to be able to disable
WiFi and Bluetooth devices completely. You can also use hints in the /boot/device.hints, but this doesn’t save
as much power.
Using 10GBase-T speed on the network device (instead of 1000Base-T) unfortunately increases power usage notably, but there is nothing I could find to mitigate this.
Things that are often recommended but that did not help me (at least not in idle):
- NVME power states (more on this below)
- lower values for
sysctl dev.hwpstate_intel.*.epp(more on this below) hw.pci.do_power_nodriver=3
| idle temperatures | °C |
|---|---|
| CPU | 37-40 |
| NVMEs | 52-55 |
The latter was particularly interesting, because I had heard that newer NVMEs, and especially those by Lexar get very warm. It should be noted though, that the mainboard comes with a large heatsink that covers all NVMEs.
under load
The only “load test” that I performed was a scrub of the pool. Since this puts stress on the NVMEs and also the CPUs, it should be at least indicative of how things are going.
during zpool scrub |
°C |
|---|---|
| CPU | 55-59 |
| NVMEs | 69-75 |
The power usage fluctuates between 85W and 98W. I think all of these values are acceptable.
| NVME power state hint | scrub speed GiB/s | W/h |
|---|---|---|
| 0 (default) | 11 | < 100 |
| 1 | 8 | < 93 |
| 2 | 4 | < 70 |
You can use nvmecontrol to tell the NVME disks to save energy. More information on this here
and here.
I was surprised that all of this works reliably on FreeBSD, but it does! The man-page is not great though. Simply
call nvmecontrol power -p X nvmeYns1 to set the hint to X on device Y, if desired. Note that this needs to be repeated after
every reboot.
dev.hwpstate_intel.*.epp |
scrub speed GiB/s | W/h |
|---|---|---|
| 50 (default) | 11.0 | < 100 |
| 100 | 3.3 | < 60 |
You can use the dev.hwpstate_intel.*.epp sysctls for you cores to tune the eagerness of that core to scale up with
higher number meaning less eagerness.
In the end, I decided not to apply any of these “under load optimisations”. It is just very difficult, because, as shown, all optimisations that reduce watts per time also increase time. I am not certain of any good ways to quantify this, but it feels like keeping the system at 70W for 30min instead of 100W for 10min, is not really worth it. And I kind of also want the system to be fast, that’s why I spent so much money on it 🙃
The CPU does have a cTDP mode that can be activated via the BIOS and which is “worth it”, according to some articles I have read. I might give this a try in the future.
Final remarks
What a ride! I spent a lot of time optimising and benchmarking this and I am quite happy with the outcome. I am able to exhaust the 10GBit LAN connection completely, and still have resources left on the server :)
Thanks to the people at www.bsdforen.de who had quite a few helpful suggestions.
If you see anything that I missed, or have suggestions on how to improve this setup, let me know in the comments!
Footnotes
-
With ASUS being the only exception. ↩︎
-
Proper in this context means well-supported by FreeBSD and with a good performance. Usually, that means an Intel NIC. Unfortunately all the modern boards come Marvell/Aquantia AQtion adaptors which are not well-supported by FreeBSD. ↩︎
-
The geli device was created with:
geli init -b -s4096 -l256↩︎ -
I wanted to perform all these tests with Linux as well, but I ran out of time 🙈 ↩︎
-
I did try a slightly more more modern adapter with Intel 82599EN chip. This is a SFP+ chip, but I found an adaptor with built-in 10GBase-T for around 150€. It ended up having some driver issues (you needed to plug and unplug the CAT cable for the device to go UP), and it used more energy than the X540, so I sent it back. ↩︎
Tuesday, 23 April 2024
Meta Horizon OS, Replicant and the GPL

Meta Horizon OS is a variant of Android, which includes GPLed parts, including the kernel Linux. Replicant is a fully free variant of Android that can run on smartphones and other kinds of devices. As the maintainer of libsurvive I have been working on a port to Android/Replicant which is known to work well with the Rockchip RK3399.
A few weeks ago, I asked for the source code for the Oclulus-Linux kernel, but until now the Meta Quest does not comply with the GPL. So I plan to make my own device running Replicant and maybe Guix codenamed the Replica Quest. The Replica Quest will include a user interface called LibreVR Mobile and on my POWER9 system I use LibreVR Desktop. Any part that Meta releases as free software can be integrated into Replicant. Non-free parts need to be replaced, that will be hard work.
Sunday, 21 April 2024
IWP9
Like last year, I attended the 10th International Workshop on Plan 9 remotely, presenting a talk about porting Inferno to various Cortex-M microcontrollers.
The presentation covers things that I mentioned in my previous post, so I won't go into details. My diary entry has links to the video and materials.
Categories: Inferno, Free Software
KDE Gear 24.05 branches created

Make sure you commit anything you want to end up in the KDE Gear 24.05
releases to them
Next Dates
- April 25 2024: 24.05 Freeze and Beta (24.04.80) tag & release
- May 9, 2024: 24.05 RC (24.04.90) Tagging and Release
- May 16, 2024: 24.05 Tagging
- May 23, 2024: 24.05 Release
https://community.kde.org/Schedules/KDE_Gear_24.05_Schedule
Saturday, 20 April 2024
Protokolo
On-and-off over the past few months I wrote a new tool called Protokolo. I wrote earlier about how I implemented internationalisation for this project. This blog post is a simple and short introduction to the tool.
Protokolo—Esperanto for ‘report’ or ‘minutes’—is a change log generator. It solves a very simple (albeit annoying) problem space at the intersection of change logs and version control systems:
- Different merge requests all edit the same area in CHANGELOG, inevitably resulting in merge conflicts.
- If a section for an unreleased version does not yet exist in the main branch’s CHANGELOG (typically shortly after release), feature branches must create this section. If multiple feature branches do this, you get more merge conflicts.
- Old merge requests, when merged, sometimes add their change log entry to the section of a release that is already published.
Protokolo gets rid of the above problems by having the user create a separate file for each change log fragment (think: one new file per merge request). Then, just before release, all the files get concatenated into a new section in CHANGELOG.
This idea is not exactly new. Towncrier does the same thing. Protokolo is only different in some of the implementation details.
The documentation of Protokolo is—I think—excellent and comprehensive. To prevent myself from repeating things in this blog post, I recommend reading the documentation for a usage guide.
Barring some improvements I want to do to Click and internationalisation, I think the project is finished, insofar as software projects are ever finished. And that’s pretty cool! I should finish software projects more often.
Sunday, 14 April 2024
How to set up Python internationalisation with Click, Poetry, Forgejo, and Weblate
TL;DR—look at Protokolo and do exactly what it does.
This is a short article because I am lazy but do want to be helpful. The sections are the steps you should take. All code presented in this article is licensed CC0-1.0.
Use gettext
As a first step, you should use
gettext. This effectively
means wrapping all string literals in _() calls. This article won’t waste a
lot of time on how to do this or how gettext works. Just make sure to get
plurals right, and make sure to provide translator comments where necessary.
I recommend using the class-based API. In your module, create the following file
i18n.py.
import gettext as _gettext_module
import os
_PACKAGE_PATH = os.path.dirname(__file__)
_LOCALE_DIR = os.path.join(_PACKAGE_PATH, "locale")
TRANSLATIONS = _gettext_module.translation(
"your-module", localedir=_LOCALE_DIR, fallback=True
)
_ = TRANSLATIONS.gettext
gettext = TRANSLATIONS.gettext
ngettext = TRANSLATIONS.ngettext
pgettext = TRANSLATIONS.pgettext
npgettext = TRANSLATIONS.npgettext
This assumes that your compiled .mo files will live in
your-module/locale/<lang>/LC_MESSAGES/your-module.mo. We’ll take care of that
later. Putting the compiled files there isn’t ideal (you want them in
/usr/share/locale), but it’s the best you can do with Python packaging.
In subsequent files, just do the following to translate strings:
from .i18n import _
# TRANSLATORS: translator comment goes here.
print(_("Hello, world!"))
However, the Click module doesn’t use our TRANSLATIONS object. To fix this, we
need to use the GNU gettext API. This is kind of dirty, because it messes with
the global state, so let’s do it in cli.py (the file which contains all your
Click groups and commands).
if gettext.find("your-module", localedir=_LOCALE_DIR):
gettext.bindtextdomain("your-module", _LOCALE_DIR)
gettext.textdomain("your-module")
Internationalise Click
When using Click, you have two challenges:
- You need to translate the help docstrings of your groups and commands.
- You need to translate the Click gettext strings.
Translating docstrings
Normally, you have some code like this:
@click.group(name="your-module")
def main():
"""Help text goes here."""
...
And when you run your-module --help, you get the following output:
$ your-module --help
Usage: your-module [OPTIONS] COMMAND [ARGS]...
Help text goes here.
Options:
--help Show this message and exit.
You cannot wrap the docstring in a _() call. So by necessity, we will need to
remove the docstring and do something like this:
_MAIN_HELP = _("Help text goes here.")
@click.group(name="your-module", help=_MAIN_HELP)
def main():
...
For multiple paragraphs, I translate each paragraph separately, which is easier for the translators:
_HELP_TEXT = (
_("Help text goes here.")
+ "\n\n"
+ _(
"Longer help paragraph goes here. We use implicit string concatenation"
" to avoid putting newlines in the translated text."
)
)
Translate the Click gettext strings
We will create a script generate_pot.sh that generates our .pot file,
including the Click translations. My script-fu isn’t very good, but it appears
to work.
#!/usr/bin/env sh
# Set VIRTUAL_ENV if one does not exist.
if [ -z "${VIRTUAL_ENV}" ]; then
VIRTUAL_ENV=$(poetry env info --path)
fi
# Get all the translation strings from the source.
xgettext --add-comments --from-code=utf-8 --output=po/your-module.pot src/**/*.py
xgettext --add-comments --output=po/click.pot "${VIRTUAL_ENV}"/lib/python*/*-packages/click/**.py
# Put everything in your-module.pot.
msgcat --output=po/your-module.pot po/your-module.pot po/click.pot
# Update the .po files. Ideally this should be done by Weblate, but it appears
# that it isn't.
for name in po/*.po
do
msgmerge --output="${name}" "${name}" po/your-module.pot;
done
After running this script, all strings that must be translated are in your
.pot and existing .po files.
You can use the above script for argparse as well, with minor modifications.
Generate .pot file automagically
You don’t want to manually run the generate_pot.sh script. Instead, you want
the CI (Forgejo Actions) to run it on your behalf whenever a gettext string is
changed or introduced.
Use the following .forgejo/workflows/gettext.yaml file.
name: Update .pot file
on:
push:
branches:
- main
# Only run this job when a Python source file is edited. Not strictly
# needed.
paths:
- "src/your-module/**.py"
jobs:
create-pot:
runs-on: docker
container: nikolaik/python-nodejs:python3.11-nodejs21
steps:
- uses: actions/checkout@v3
- name: Install gettext
run: |
apt-get update
apt-get install -y gettext
# We mostly install your-module to install the click dependency.
- name: Install your-module
run: poetry install --no-interaction --only main
- name: Install wlc
run: pip install wlc
- name: Lock Weblate
run: |
wlc --url https://hosted.weblate.org/api/ --key ${{secrets.WEBLATE_KEY }} lock your-project/your-module
- name: Push changes from Weblate to upstream repository
run: |
wlc --url https://hosted.weblate.org/api/ --key ${{secrets.WEBLATE_KEY }} push your-project/your-module
- name: Pull Weblate translations
run: git pull origin main
- name: Create .pot file
run: ./generate_pot.sh
# Normally, POT-Creation-Date changes in two locations. Check if the diff
# includes more than just those two lines.
- name: Check if sufficient lines were changed
id: diff
run:
echo "changed=$(git diff -U0 | grep '^[+|-][^+|-]' | grep -Ev
'^[+-]"POT-Creation-Date' | wc -l)" >> $GITHUB_OUTPUT
- name: Commit and push updated your-module.pot
if: ${{ steps.diff.outputs.changed != '0' }}
run: |
git config --global user.name "your-module-bot"
git config --global user.email "<>"
git add po/your-module.pot po/*.po
git commit -m "Update your-module.pot"
git push origin main
wlc --url https://hosted.weblate.org/api/ --key ${{ secrets.WEBLATE_KEY }} pull your-project/your-module
wlc --url https://hosted.weblate.org/api/ --key ${{ secrets.WEBLATE_KEY }} unlock your-project/your-module
The job is fairly self-explanatory. The wlc command talks with Weblate, which
we will set up soon. The job installs dependencies, gets the latest
translations from Weblate, generates the .pot, and then pushes the generated
.pot (and .po files) if there were changed strings.
See
reuse-tool
for a GitHub Actions job. It is currently missing the wlc locking.
Set up Weblate
Create your project in Weblate. In the VCS
settings, set version control system to ‘Git’. Set your source repository and
branch correctly. Set the push URL to
https://<your-token>@codeberg.org/your-name/your-module.git. You get the token
from https://codeberg.org/user/settings/applications. You will need to give
the token access to ‘repository’. There should be a more granular way of doing
this, but I am not aware of it.
Set the repository browser to
https://codeberg.org/your-name/your-module/src/branch/{{branch}}/{{filename}}#{{line}}.
Turn ‘Push on commit’ on, and set merge style to ‘rebase’. Also, always lock on
error.
In your project settings on Weblate, generate a project API token. Then in your
Forgejo Actions settings, create a secret named WEBLATE_KEY with the project
API token as value.
Publishing your translations with Poetry
Now that all the translation plumbing is working, you just need to make sure
that you generate your .mo files when building/publishing with Poetry.
We add a build step to Poetry using the undocumented build
script. Add the following to your pyproject.toml:
[tool.poetry.build]
generate-setup-file = false
script = "_build.py"
Do NOT name your file build.py. It will break Arch Linux
packaging.
Create the file _build.py. Here are the contents:
import glob
import logging
import os
import shutil
import subprocess
from pathlib import Path
_LOGGER = logging.getLogger(__name__)
ROOT_DIR = Path(os.path.dirname(__file__))
BUILD_DIR = ROOT_DIR / "build"
PO_DIR = ROOT_DIR / "po"
def mkdir_p(path):
"""Make directory and its parents."""
Path(path).mkdir(parents=True, exist_ok=True)
def rm_fr(path):
"""Force-remove directory."""
path = Path(path)
if path.exists():
shutil.rmtree(path)
def main():
"""Compile .mo files and move them into src directory."""
rm_fr(BUILD_DIR)
mkdir_p(BUILD_DIR)
msgfmt = None
for executable in ["msgfmt", "msgfmt.py", "msgfmt3.py"]:
msgfmt = shutil.which(executable)
if msgfmt:
break
if msgfmt:
po_files = glob.glob(f"{PO_DIR}/*.po")
mo_files = []
# Compile
for po_file in po_files:
_LOGGER.info(f"compiling {po_file}")
lang_dir = (
BUILD_DIR
/ "your-module/locale"
/ Path(po_file).stem
/ "LC_MESSAGES"
)
mkdir_p(lang_dir)
destination = Path(lang_dir) / "your-module.mo"
subprocess.run(
[
msgfmt,
"-o",
str(destination),
str(po_file),
],
check=True,
)
mo_files.append(destination)
# Move compiled files into src
rm_fr(ROOT_DIR / "src/your-module/locale")
for mo_file in mo_files:
relative = (
ROOT_DIR / Path("src") / os.path.relpath(mo_file, BUILD_DIR)
)
_LOGGER.info(f"copying {mo_file} to {relative}")
mkdir_p(relative.parent)
shutil.copyfile(mo_file, relative)
if __name__ == "__main__":
main()
It is probably a little over-engineered (building into build/ and then
consequently copying to src/your-module/locale is unnecessary), but it works.
Finally, make sure to actually include *.mo files in pyproject.toml:
include = [
{ path = "src/your-module/locale/**/*.mo", format="wheel" }
]
And that’s it! A rather dense and curt blog post, but it should contain helpful bits and pieces.
Sunday, 07 April 2024
Some More Slow Progress
A couple of months have elapsed since my last, brief progress report on L4Re development, so I suppose a few words are required to summarise what I have done since. Distractions, travel, and other commitments notwithstanding, I did manage to push my software framework along a little, encountering frustrations and the occasional sensation of satisfaction along the way.
Supporting Real Hardware
Previously, I had managed to create a simple shell-like environment running within L4Re that could inspect an ext2-compatible filesystem, launch programs, and have those programs communicate with the shell – or each other – using pipes. Since I had also been updating my hardware support framework for L4Re on MIPS-based devices, I thought that it was time to face up to implementing support for memory cards – specifically, SD and microSD cards – so that I could access filesystems residing on such cards.
Although I had designed my software framework with things like disks and memory devices in mind, I had been apprehensive about actually tackling driver development for such devices, as well as about whether my conceptual model would prove too simple, necessitating more framework development just to achieve the apparently simple task of reading files. It turned out that the act of reading data, even when almost magical mechanisms like direct memory access (DMA) are used, is as straightforward as one could reasonably expect. I haven’t tested writing data yet, mostly because I am not that brave, but it should be essentially as straightforward as reading.
What was annoying and rather overcomplicated, however, was the way that memory cards have to be coaxed into cooperation, with the SD-related standards featuring layer upon layer of commands added every time they enhanced the technologies. Plenty of time was spent (or wasted) trying to get these commands to behave and to allow me to gradually approach the step where data would actually be transferred. In contrast, setting up DMA transactions was comparatively easy, particularly using my interactive hardware experimentation environment.
There were some memorable traps encountered in the exercise. One involved making sure that the interrupts signalling completed DMA transactions were delivered to the right thread. In L4Re, hardware interrupts are delivered via IRQ (interrupt request) objects to specific threads, and it is obviously important to make sure that a thread waiting for notifications (including interrupts) expects these notifications. Otherwise, they may cause a degree of confusion, which is what happened when a thread serving “blocks” of data to the filesystem components was presented with DMA interrupt occurrences. Obviously, the solution was to be more careful and to “bind” the interrupts to the thread interacting with the hardware.
Another trap involved the follow-on task of running programs that had been read from the memory card. In principle, this should have yielded few surprises: my testing environment involves QEMU and raw filesystem data being accessed in memory, and program execution was already working fine there. However, various odd exceptions were occurring when programs were starting up, forcing me to exercise the useful kernel debugging tool provided with the Fiasco.OC (or L4Re) microkernel.
Of course, the completely foreseeable problem involved caching: data loaded from the memory card was not yet available in the processor’s instruction cache, and so the processor was running code (or potentially something that might not have been code) that had been present in the cache. The problem tended to arise after a jump or branch in the code, executing instructions that did undesirable things to the values of the registers until something severe enough caused an exception. The solution, of course, was to make sure that the instruction cache was synchronised with the data cache containing the newly read data using the l4_cache_coherent function.
Replacing the C Library
With that, I could replicate my shell environment on “real hardware” which was fairly gratifying. But this only led to the next challenge: that of integrating my filesystem framework into programs in a more natural way. Until now, accessing files involved a special “filesystem client” library that largely mimics the normal C library functions for such activities, but the intention has always been to wrap these with the actual C library functions so that portable programs can be run. Ideally, there would be a way of getting the L4Re C library – an adapted version of uClibc – to use these client library functions.
A remarkable five years have passed since I last considered such matters. Back then, my investigations indicated that getting the L4Re library to interface to the filesystem framework might be an involved and cumbersome exercise due to the way the “backend” functionality is implemented. It seemed that the L4Re mechanism for using different kinds of filesystems involved programs dynamically linking to libraries that would perform the access operations on the filesystem, but I could not find much documentation for this framework, and I had the feeling that the framework was somewhat underdeveloped, anyway.
My previous investigations had led me to consider deploying an alternative C library within L4Re, with programs linking to this library instead of uClibc. C libraries generally come across as rather messy and incoherent things, accumulating lots of historical baggage as files are incorporated from different sources to support long-forgotten systems and architectures. The challenge was to find a library that could be conveniently adapted to accommodate a non-Unix-like system, with the emphasis on convenience precluding having to make changes to hundreds of files. Eventually, I chose Newlib because the breadth of its dependencies on the underlying system is rather narrow: a relatively small number of fundamental calls. In contrast, other C libraries assume a Unix-like system with countless, specialised system calls that would need to be reinterpreted and reframed in terms of my own library’s operations.
My previous effort had rather superficially demonstrated a proof of concept: linking programs to Newlib and performing fairly undemanding operations. This time round, I knew that my own framework had become more complicated, employed C++ in various places, and would create a lot of work if I were to decouple it from various L4Re packages, as I had done in my earlier proof of concept. I briefly considered and then rejected undertaking such extra work, instead deciding that I would simply dust off my modified Newlib sources, build my old test programs, and see which symbols were missing. I would then seek to reintroduce these symbols and hope that the existing L4Re code would be happy with my substitutions.
Supporting Threads
For the very simplest of programs, I was able to “stub” a few functions and get them to run. However, part of the sophistication of my framework in its current state is its use of threading to support various activities. For example, monitoring data streams from pipes and files involves a notification mechanism employing threads, and thus a dependency on the pthread library is introduced. Unfortunately, although Newlib does provide a similar pthread library to that featured in L4Re, it is not really done in a coherent fashion, and there is other pthread support present in Newlib that just adds to the confusion.
Initially, then, I decided to create “stub” implementations for the different functions used by various libraries in L4Re, like the standard C++ library whose concurrency facilities I use in my own code. I made a simple implementation of pthread_create, along with some support for mutexes. Running programs did exercise these functions and produce broadly expected results. Continuing along this path seemed like it might entail a lot of work, however, and in studying the existing pthread library in L4Re, I had noticed that although it resides within the “uclibc” package, it is somewhat decoupled from the C library itself.
Favouring laziness, I decided to see if I couldn’t make a somewhat independent package that might then be interfaced to Newlib. For the most part, this exercise involved introducing missing functions and lots of debugging, watching the initialisation of programs fail due to things like conflicts with capability allocation, perhaps due to something I am doing wrong, or perhaps exposing conditions that are fortuitously avoided in L4Re’s existing uClibc arrangement. Ultimately, I managed to get a program relying on threading to start, leaving me with the exercise of making sure that it was producing the expected output. This involved some double-checking of previous measures to allow programs using different C libraries to communicate certain kinds of structures without them misinterpreting the contents of those structures.
Further Work
There is plenty still to do in this effort. First of all, I need to rewrite the remaining test programs to use C library functions instead of client library functions, having done this for only a couple of them. Then, it would be nice to expand C library coverage to deal with other operations, particularly process creation since I spent quite some time getting that to work.
I need to review the way Newlib handles concurrency and determine what else I need to do to make everything work as it should in that regard. I am still using code from an older version of Newlib, so an update to a newer version might be sensible. In this latest round of C library evaluation, I briefly considered Picolibc which is derived from Newlib and other sources, but I didn’t fancy having to deal with its build system or to repackage the sources to work with the L4Re build system. I did much of the same with Newlib previously and, having worked through such annoyances, was largely able to focus on the actual code as opposed to the tooling.
Currently, I have been statically linking programs to Newlib, but I eventually want to dynamically link them. This does exercise different paths in the C and pthread libraries, but I also want to explore dynamic linking more broadly in my own environment, having already postponed such investigations from my work on getting programs to run. Introducing dynamic linking and shared libraries helps to reduce memory usage and increase the performance of a system when multiple programs need the same libraries.
There are also some reasonable arguments for making the existing L4Re pthread implementation more adaptable, consolidating my own changes to the code, and also for considering making or adopting other pthread implementations. Convenient support for multiple C library implementations, and for combining these with other libraries, would be desirable, too.
Much of the above has been a distraction from what I have been wanting to focus on, however. Had it been more apparent how to usefully extend uClibc, I might not have bothered looking at Newlib or other C libraries, and then I probably wouldn’t have looked into threading support. Although I have accumulated some knowledge in the process, and although some of that knowledge will eventually have proven useful, I cannot help feeling that L4Re, being a fairly mature product at this point and a considerable achievement, could be more readily extensible and accessible than it currently is.
Friday, 05 April 2024
Migrate legacy openldap to a docker container.
Migrate legacy openldap to a docker container.
Prologue
I maintain a couple of legacy EOL CentOS 6.x SOHO servers to different locations. Stability on those systems is unparalleled and is -mainly- the reason of keeping them in production, as they run almost a decade without a major issue.
But I need to do a modernization of these legacy systems. So I must prepare a migration plan. Initial goal was to migrate everything to ansible roles. Although, I’ve walked down this path a few times in the past, the result is not something desirable. A plethora of configuration files and custom scripts. Not easily maintainable for future me.
Current goal is to setup a minimal setup for the underlying operating system, that I can easily upgrade through it’s LTS versions and separate the services from it. Keep the configuration on a git repository and deploy docker containers via docker-compose.
In this blog post, I will document the openldap service. I had some is issues against bitnami/openldap docker container so the post is also a kind of documentation.
Preparation
Two different cases, in one I have the initial ldif files (without the data) and on the second node I only have the data in ldifs but not the initial schema. So, I need to create for both locations a combined ldif that will contain the schema and data.
And that took me more time that it should! I could not get the service running correctly and I experimented with ldap exports till I found something that worked against bitnami/openldap notes and environment variables.
ldapsearch command
In /root/.ldap_conf I keep the environment variables as Base, Bind and Admin Password (only root user can read them).
cat /usr/local/bin/lds #!/bin/bash
source /root/.ldap_conf
/usr/bin/ldapsearch
-o ldif-wrap=no
-H ldap://$HOST
-D $BIND
-b $BASE
-LLL -x
-w $PASS $*
sudo lds > /root/openldap_export.ldif
Bitnami/openldap
GitHub page of bitnami/openldap has extensive documentation and a lot of environment variables you need to setup, to run an openldap service. Unfortunately, it took me quite a while, in order to find the proper configuration to import ldif from my current openldap service.
Through the years bitnami has made a few changes in libopenldap.sh which produced a frustrated period for me to review the shell script and understand what I need to do.
I would like to explain it in simplest terms here and hopefully someone will find it easier to migrate their openldap.
TL;DR
The correct way:
Create local directories
mkdir -pv {ldif,openldap}Place your openldap_export.ldif to the local ldif directory, and start openldap service with:
docker compose up---
services:
openldap:
image: bitnami/openldap:2.6
container_name: openldap
env_file:
- path: ./ldap.env
volumes:
- ./openldap:/bitnami/openldap
- ./ldifs:/ldifs
ports:
- 1389:1389
restart: always
volumes:
data:
driver: local
driver_opts:
device: /storage/docker
Your environmental configuration file, should look like:
cat ldap.env LDAP_ADMIN_USERNAME="admin"
LDAP_ADMIN_PASSWORD="testtest"
LDAP_ROOT="dc=example,dc=org"
LDAP_ADMIN_DN="cn=admin,$ LDAP_ROOT"
LDAP_SKIP_DEFAULT_TREE=yes
Below we are going to analyze and get into details of bitnami/openldap docker container and process.
OpenLDAP Version in docker container images.
Bitnami/openldap docker containers -at the time of writing- represent the below OpenLDAP versions:
bitnami/openldap:2 -> OpenLDAP: slapd 2.4.58
bitnami/openldap:2.5 -> OpenLDAP: slapd 2.5.17
bitnami/openldap:2.6 -> OpenLDAP: slapd 2.6.7list images
docker images -a
REPOSITORY TAG IMAGE ID CREATED SIZE
bitnami/openldap 2.6 bf93eace348a 30 hours ago 160MB
bitnami/openldap 2.5 9128471b9c2c 2 days ago 160MB
bitnami/openldap 2 3c1b9242f419 2 years ago 151MB
Initial run without skipping default tree
As mentioned above the problem was with LDAP environment variables and LDAP_SKIP_DEFAULT_TREE was in the middle of those.
cat ldap.env LDAP_ADMIN_USERNAME="admin"
LDAP_ADMIN_PASSWORD="testtest"
LDAP_ROOT="dc=example,dc=org"
LDAP_ADMIN_DN="cn=admin,$ LDAP_ROOT"
LDAP_SKIP_DEFAULT_TREE=no
for testing: always empty ./openldap/ directory
docker compose up -dBy running ldapsearch (see above) the results are similar to below data
ldsdn: dc=example,dc=org
objectClass: dcObject
objectClass: organization
dc: example
o: example
dn: ou=users,dc=example,dc=org
objectClass: organizationalUnit
ou: users
dn: cn=user01,ou=users,dc=example,dc=org
cn: User1
cn: user01
sn: Bar1
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: shadowAccount
userPassword:: Yml0bmFtaTE=
uid: user01
uidNumber: 1000
gidNumber: 1000
homeDirectory: /home/user01
dn: cn=user02,ou=users,dc=example,dc=org
cn: User2
cn: user02
sn: Bar2
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: shadowAccount
userPassword:: Yml0bmFtaTI=
uid: user02
uidNumber: 1001
gidNumber: 1001
homeDirectory: /home/user02
dn: cn=readers,ou=users,dc=example,dc=org
cn: readers
objectClass: groupOfNames
member: cn=user01,ou=users,dc=example,dc=org
member: cn=user02,ou=users,dc=example,dc=org
so as you can see, they create some default users and groups.
Initial run with skipping default tree
Now, let’s skip creating the default users/groups.
cat ldap.env LDAP_ADMIN_USERNAME="admin"
LDAP_ADMIN_PASSWORD="testtest"
LDAP_ROOT="dc=example,dc=org"
LDAP_ADMIN_DN="cn=admin,$ LDAP_ROOT"
LDAP_SKIP_DEFAULT_TREE=yes
(always empty ./openldap/ directory )
docker compose up -dldapsearch now returns:
No such object (32)That puzzled me … a lot !
Conclusion
It does NOT matter if you place your ldif schema file and data and populate the LDAP variables with bitnami/openldap. Or use ANY other LDAP variable from bitnami/openldap reference manual.
The correct method is to SKIP default tree and place your export ldif to the local ldif directory. Nothing else worked.
Took me almost 4 days to figure it out and I had to read the libopenldap.sh.
That’s it !
Wednesday, 06 March 2024
SymPy: a powerful math library
SymPy is a lightweight symbolic mathematics library for Python under the 3-clause BSD license that can be used either as a library or in an interactive environment. It features symbolic expressions, solving equations, plotting and much more!
Creating and using functions
Creating a function is as simple as using variables and putting them into a mathematical expression:
|
|
Line 1 imports the x and y
Symbols
from the abc collection of Symbols, line 3 creates the f function which is
$2x^2 + 3y + 10$, and line 4 evaluates f with values 3 and 5 for x and y,
respectively.
SymPy exports a large list of mathematical functions for more complex expressions such logarithm, exponential, etc., and is able to analyze the fucntion’s characteristics over arbitrary intervals:
|
|
Plotting
SymPy is able to easily plot functions on a given interval:
|
|
Line 1 imports the
plot()
function, line 3 creates the f Function object from the sigmoid
expression $\frac{1}{1+\exp^{-x}}$, line 4 plots f and its derivative between
-5 and 5, lines 5-6 set the legends labels and lines 7 shows the created plot:
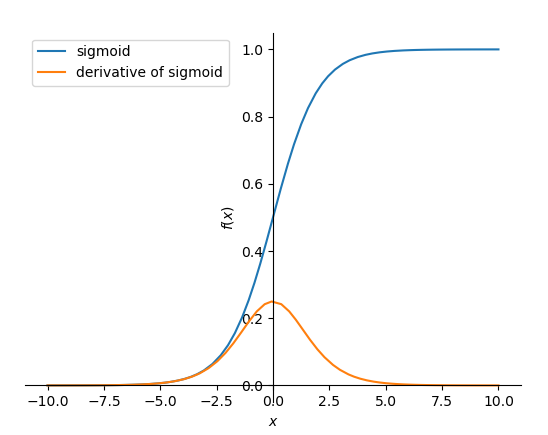
Sigmoid and its derivative.
In a few lines of code, the library allows one to create a mathematical function, do operations on it like computing its derivative and plot the result. Moreover, as SymPy uses Matplotlib under the hood by default, the plots are modifiable using the Matplotlib API.
SymPy also supports 3D plots with the
plot3d()
function which helps understanding the relationship between two variables and an
outcome. The following code computes the energy of the recoiling electron after
Compton scattering depending on the initial photon energy and the scattering
angle (in degrees) using the Compton scattering
formula : $$\beta = \arccos
\left(1 - \frac{Ee * 511}{E0 * (E0 - Ee)}\right) * \frac{180}{3.14159}$$
|
|
Line 1 imports the plot3d function, line 3 creates the E0 (the initial
photon energy) and theta custom variables1, line 4 defines the beta
function which depends on the E0 and Ee variables, line 6 does the
plotting and defines the axes intervals, line 7 sets the axes’ labels and line 8
displays the following figure:
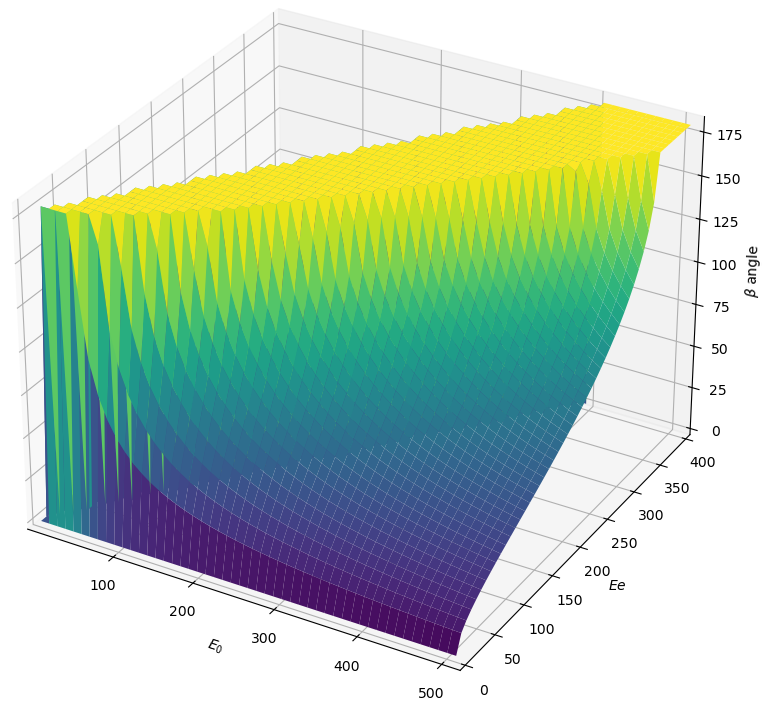
Compton angle depending on E0 and Ee.
Solving equations
SymPy also has an equation solver for algebraic equations and equations systems: SymPy considers the equations strings to be equal to zero for ease of use.
|
|
The equation solvers also works for boolean logic, where SymPy tells what should be the truth values of the variables to satisfy a boolean expression:
|
|
An unsatisfiable expression yields False.
Geometry
SymPy also features a geometry module allowing to perform geometric operations such as Points, Segments and Polygons. It’s
|
|
Line 1 imports classes from the geometry module, Line 2 import the SymPy plotting backends library, which contains additional plotting features needed to plot geometric objects, line 3 and 4 create a polygon and a segment, respectively, line 6 plots the figure and line 7 returns the intersection points of the polygon and the segment. Line 6 produces the following figure:
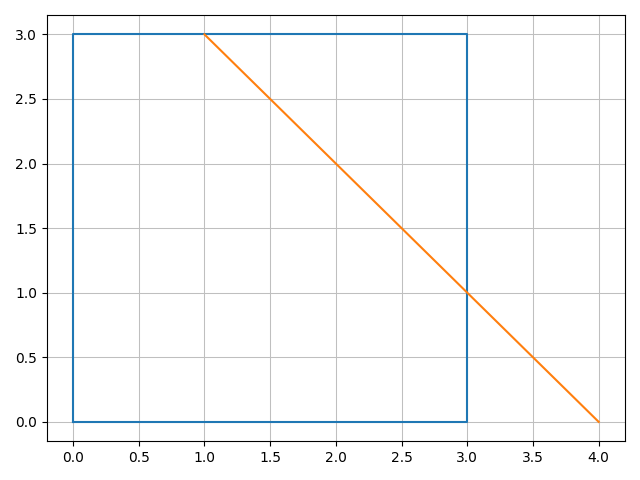
Compton angle depending on E0 and Ee.
The SymPy library is thus easy to use and suitable for various applications. Because it’s Free Software, anyone can use, share, study and improve it for whatever purpose, just like mathematics.
-
We could use the
xandyvariables here but having custom variables names makes reading the code easier. ↩︎
Monday, 04 March 2024
A Tall Tale of Denied Glory
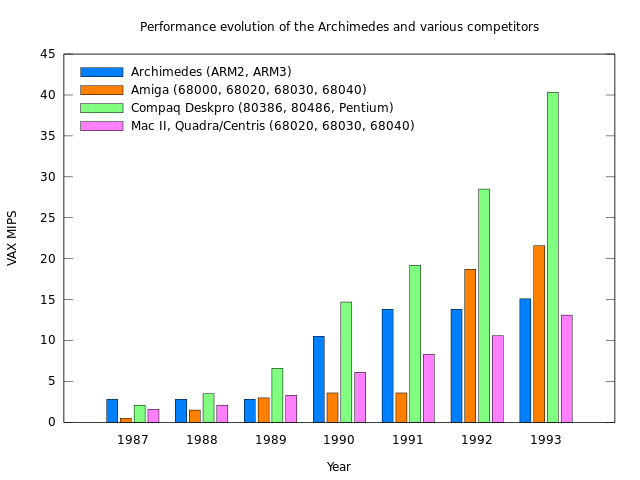
I seem to be spending too much time looking into obscure tales from computing history, but continuing an earlier tangent from a recent article, noting the performance of different computer systems at the end of the 1980s and the start of the 1990s, I found myself evaluating one of those Internet rumours that probably started to do the rounds about thirty years ago. We will get to that rumour – a tall tale, indeed – in a moment. But first, a chart that I posted in an earlier article:
Performance evolution of the Archimedes and various competitors
As this nice chart indicates, comparing processor performance in computers from Acorn, Apple, Commodore and Compaq, different processor families bestowed a competitive advantage on particular systems at various points in time. For a while, Acorn’s ARM2 processor gave Acorn’s Archimedes range the edge over much more expensive systems using the Intel 80386, showcased in Compaq’s top-of-the-line models, as well as offerings from Apple and Commodore, these relying on Motorola’s 68000 family. One can, in fact, claim that a comparison between ARM-based systems and 80386-based systems would have been unfair to Acorn: more similarly priced systems from PC-compatible vendors would have used the much slower 80286, making the impact of the ARM2 even more remarkable.
Something might be said about the evolution of these processor families, what happened after 1993, and the introduction of later products. Such topics are difficult to address adequately for a number of reasons, principally the absence of appropriate benchmark results and the evolution of benchmarking to more accurately reflect system performance. Acorn never published SPEC benchmark figures, nor did ARM (at the time, at least), and any given benchmark as an approximation to “real-world” computing activities inevitably drifts away from being an accurate approximation as computer system architecture evolves.
However, in another chart I made to cover Acorn’s Unix-based RISC iX workstations, we can consider another range of competitors and quite a different situation. (This chart also shows off the nice labelling support in gnuplot that wasn’t possible with the currently disabled MediaWiki graph extension.)
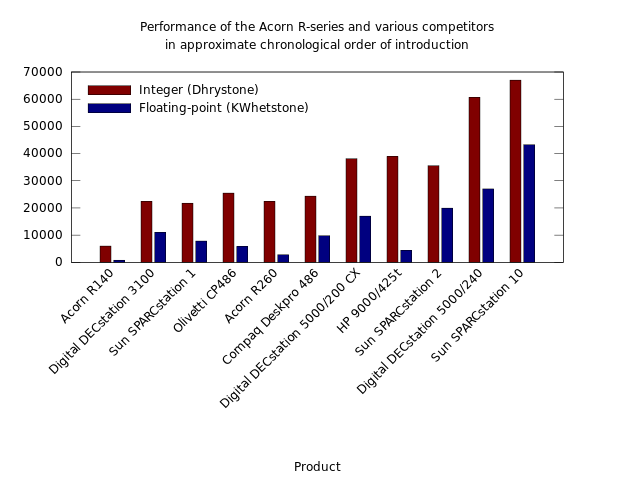
Performance of the Acorn R-series and various competitors in approximate chronological order of introduction: a chart produced by gnuplot and converted from SVG to PNG for Wikipedia usage.
Now, this chart only takes us from 1989 until 1992, which will not satisfy anyone wondering what happened next in the processor wars. But it shows the limits of Acorn’s ability to enter the lucrative Unix workstation market with a processor that was perceived to be rather fast in the world of personal computers. Acorn’s R140 used the same ARM2 processor introduced in the Archimedes range, but even at launch this workstation proved to be considerably slower than somewhat more expensive workstation models from Digital and Sun employing MIPS and SPARC processors respectively.
Fortunately for Acorn, adding a cache to the ARM2 (plus a few other things) to make the ARM3 unlocked a considerable boost in performance. Although the efficient utilisation of available memory bandwidth had apparently been a virtue for the ARM designers, coupling the processor to memory performance had put a severe limit on overall performance. Meanwhile, the designers of the MIPS and SPARC processor families had started out with a different perspective and had considered cache memory almost essential in the kind of computer architectures that would be using these processors.
Acorn didn’t make another Unix workstation after the R260, released in 1990, for reasons that could be explored in depth another time. One of them, however, was that ARM processor design had been spun out to a separate company, ARM Limited, and appeared to be stalling in terms of delivering performance improvements at the same rate as previously, or indeed at the same rate as other processor families. Acorn did introduce the ARM610 belatedly in 1994 in its Risc PC, which would have been more amenable to running Unix, but by then the company was arguably beginning the process of unravelling for another set of reasons to be explored another time.
So, That Tall Tale
It is against this backdrop of competitive considerations that I now bring you the tall tale to which I referred. Having been reminded of the Atari Transputer Workstation by a video about the Transputer – another fascinating topic and thus another rabbit hole to explore – I found myself investigating Atari’s other workstation product: a Unix workstation based on the Motorola 68030 known as the Atari TT030 or TT/X, augmenting the general Atari TT product with the Unix System V operating system.
On the chart above, a 68030-based system would sit at a similar performance level to Acorn’s R140, so ignoring aspirational sentiments about “high-end” performance and concentrating on a price of around $3000 (with a Unix licence probably adding to that figure), there were some hopes that Atari’s product would reach a broad audience:
As a UNIX platform, the affordable TT030 may leapfrog machines from IBM, Apple, NeXT, and Sun, as the best choice for mass installation of UNIX systems in these environments.
As it turned out, Atari released the TT without Unix in 1990 and only eventually shipped a Unix implementation in around 1992, discontinuing the endeavour not long afterwards. But the tall tale is not about Atari: it is about their rivals at Commodore and some bizarre claims that seem to have drifted around the Internet for thirty years.
Like Atari and Acorn, Commodore also had designs on the Unix workstation market. And like Atari, Commodore had a range of microcomputers, the Amiga series, based on the 68000 processor family. So, the natural progression for Commodore was to design a model of the Amiga to run Unix, eventually giving us the Amiga 3000UX, priced from around $5000, running an implementation of Unix System V Release 4 branded as “Amiga Unix”.
Reactions from the workstation market were initially enthusiastic but later somewhat tepid. Commodore’s product, although delivered in a much more timely fashion than Atari’s, will also have found itself sitting at a similar performance level to Acorn’s R140 but positioned chronologically amongst the group including Acorn’s much faster R260 and the 80486-based models. It goes without saying that Atari’s eventual product would have been surrounded by performance giants by the time customers could run Unix on it, demonstrating the need to bring products to market on time.
So what is this tall tale, then? Well, it revolves around this not entirely coherent remark, entered by some random person twenty-one years ago on the emerging resource known as Wikipedia:
The Amiga A3000UX model even got the attention of Sun Microsystems, but unfortunately Commodore did not jump at the A3000UX.
If you search the Web for this, including the Internet Archive, the most you will learn is that Sun Microsystems were supposedly interested in adopting the Amiga 3000UX as a low-cost workstation. But the basis of every report of this supposed interest always seems to involve “talk” about a “deal” and possibly “interest” from unspecified “people” at Sun Microsystems. And, of course, the lack of any eventual deal is often blamed on Commodore’s management and perennial villain of the Amiga scene…
There were talks of Sun Microsystems selling Amiga Unix machines (the prototype Amiga 3500) as a low-end Unix workstations under their brand, making Commodore their OEM manufacturer. This deal was let down by Commodore’s Mehdi Ali, not once but twice and finally Sun gave up their interest.
Of course, back in 2003, anything went on Wikipedia. People thought “I know this!” or “I heard something about this!”, clicked the edit link, and scrawled away, leaving people to tidy up the mess two decades later. So, I assume that this tall tale is just the usual enthusiast community phenomenon of believing that a favourite product could really have been a contender, that legitimacy could have been bestowed on their platform, and that their favourite company could have regained some of its faded glory. Similar things happened as Acorn went into decline, too.
Picking It All Apart
When such tales appeal to both intuition and even-handed consideration, they tend to retain a veneer of credibility: of being plausible and therefore possibly true. I cannot really say whether the tale is actually true, only that there is no credible evidence of it being true. However, it is still worth evaluating the details within such tales on their merits and determine whether the substance really sounds particularly likely at all.
So, why would Sun Microsystems be interested in a Commodore workstation product? Here, it helps to review Sun’s own product range during the 1980s, to note that Sun had based its original workstation on the Motorola 68000 and had eventually worked up the 68000 family to the 68030 in its Sun-3 products. Indeed, the final Sun-3 products were launched in 1989, not too long before the Amiga 3000UX came to market. But the crucial word in the previous sentence is “final”: Sun had adopted the SPARC processor family and had started introducing SPARC-based models two years previously. Like other workstation vendors, Sun had started to abandon Motorola’s processors, seeking better performance elsewhere.
A June 1989 review in Personal Workstation magazine is informative, featuring the 68030-based Sun 3/80 workstation alongside Sun’s SPARCstation 1. For diskless machines, the Sun 3/80 came in at around $6000 whereas the SPARCstation 1 came in at around $9000. For that extra $3000, the buyer was probably getting around four times the performance, and it was quite an incentive for Sun’s customers and developers to migrate to SPARC on that basis alone. But even for customers holding on to their older machines and wanting to augment their collection with some newer models, Sun was offering something not far off the “low-cost” price of an Amiga 3000UX with hardware that was probably more optimised for the role.
Sun will have supported customers using these Sun-3 models for as long as support for SunOS was available, eventually introducing Solaris which dropped support for the 68000 family architecture entirely. Just like other Unix hardware vendors, once a transition to various RISC architectures had been embarked upon, there was little enthusiasm for going back and retooling to support the Motorola architecture again. And, after years resisting, even Motorola was embracing RISC with its 88000 architecture, tempting companies like NeXT and Apple to consider trading up from the 68000 family: an adventure that deserves its own treatment, too.
So, under what circumstances would Sun have seriously considered adopting Commodore’s product? On the face of it, the potential compatibility sounds enticing, and Commodore will have undoubtedly asserted that they had experience at producing low-cost machines in volume, appealing to Sun’s estimate, expressed in the Personal Workstation review, that the customer base for a low-cost workstation would double for every $1000 drop in price. And surely Sun would have been eager to close the doors on manufacturing a product line that was going to be phased out sooner or later, so why not let Commodore keep making low-cost models to satisfy existing customers?
First of all, we might well doubt any claims to be able to produce workstations significantly cheaper than those already available. The Amiga 3000UX was, as noted, only $1000 or so cheaper than the Sun 3/80. Admittedly, it had a hard drive as standard, making the comparison slightly unfair, but then the Sun 3/80 was around already in 1989, meaning that to be fair to that product, we would need to see how far its pricing will have fallen by the time the Amiga 3000UX became available. Commodore certainly had experience in shipping large volumes of relatively inexpensive computers like the Amiga 500, but they were not shipping workstation-class machines in large quantities, and the eventual price of the Amiga 3000UX indicates that such arguments about volume do not automatically confer low cost onto more expensive products.
Even if we imagine that the Amiga 3000UX had been successfully cost-reduced and made more competitive, we then need to ask what benefits there would have been for the customer, for developers, and for Sun in selling such a product. It seems plausible to imagine customers with substantial investments in software that only ran on Sun’s older machines, who might have needed newer, compatible hardware to keep that software running. Perhaps, in such cases, the suppliers of such software were not interested or capable of porting the software to the SPARC processor family. Those customers might have kept buying machines to replace old ones or to increase the number of “seats” in their environment.
But then again, we could imagine that such customers, having multiple machines and presumably having them networked together, could have benefited from augmenting their old Motorola machines with new SPARC ones, potentially allowing the SPARC machines to run a suitable desktop environment and to use the old applications over the network. In such a scenario, the faster SPARC machines would have been far preferable as workstations, and with the emergence of the X Window System, a still lower-cost alternative would have been to acquire X terminals instead.
We might also question how many software developers would have been willing to abandon their users on an old architecture when it had been clear for some time that Sun would be transitioning to SPARC. Indeed, by producing versions of the same operating system for both architectures, one can argue that Sun was making it relatively straightforward for software vendors to prepare for future products and the eventual deprecation of their old products. Moreover, given the performance benefits of Sun’s newer hardware, developers might well have been eager to complete their own transition to SPARC and to entice customers to follow rapidly, if such enticement was even necessary.
Consequently, if there were customers stuck on Sun’s older hardware running applications that had been effectively abandoned, one could be left wondering what the scale of the commercial opportunity was in selling those customers more of the same. From a purely cynical perspective, given the idiosyncracies of Sun’s software platform from time to time, it is quite possible that such customers would have struggled to migrate to another 68000 family Unix platform. And even without such portability issues and with the chance of running binaries on a competing Unix, the departure of many workstation vendors to other architectures may have left relatively few appealing options. The most palatable outcome might have been to migrate to other applications instead and to then look at the hardware situation with fresh eyes.
And we keep needing to return to that matter of performance. A 68030-based machine was arguably unappealing, like 80386-based systems, clearing the bar for workstation computing but not by much. If the cost of such a machine could have been reduced to an absurdly low price point then one could have argued that it might have provided an accessible entry point for users into a vendor’s “ecosystem”. Indeed, I think that companies like Commodore and Acorn should have put Unix-like technology in their low-end products, harmonising them with higher-end products actually running Unix, and having their customers gradually migrate as more powerful computers became cheaper.
But for workstations running what one commentator called “wedding-cake configurations” of the X Window System, graphical user interface toolkits, and applications, processors like the 68030, 80386 and ARM2 were going to provide a disappointing experience whatever the price. Meanwhile, Sun’s existing workstations were a mature product with established peripherals and accessories. Any cost-reduced workstation would have been something distinct from those existing products, impaired in performance terms and yet unable to make use of things like graphics accelerators which might have made the experience tolerable.
That then raises the question of the availability of the 68040. Could Commodore have boosted the Amiga 3000UX with that processor, bringing it up to speed with the likes of the ARM3-based R260 and 80486-based products, along with the venerable MIPS R2000 and early SPARC processors? Here, we can certainly answer in the affirmative, but then we must ask what this would have done to the price. The 68040 was a new product, arriving during 1990, and although competitively priced relative to the SPARC and 80486, it was still quoted at around $800 per unit, featuring in Apple’s Macintosh range in models that initially, in 1991, cost over $5000. Such a cost increase would have made it hard to drive down the system price.
In the chart above, the HP 9000/425t represents possibly the peak of 68040 workstation performance – “a formidable entry-level system” – costing upwards of $9000. But as workstation performance progressed, represented by new generations of DECstations and SPARCstations, the 68040 stalled, unable to be clocked significantly faster or otherwise see its performance scaled up. Prominent users such as Apple jumped ship and adopted PowerPC along with Motorola themselves! Motorola returned to the architecture after abandoning further development of the 88000 architecture, delivering the 68060 before finally consigning the architecture to the embedded realm.
In the end, even if a competitively priced and competitively performing workstation had been deliverable by Commodore, would it have been in Sun’s interests to sell it? Compatibility with older software might have demanded the continued development of SunOS and the extension of support for older software technologies. SunOS might have needed porting to Commodore’s hardware, or if Sun were content to allow Commodore to add any necessary provision to its own Unix implementation, then porting of those special Sun technologies would have been required. One can question whether the customer experience would have been satisfactory in either case. And for Sun, the burden of prolonging the lifespan of products that were no longer the focus of the company might have made the exercise rather unattractive.
Companies can always choose for themselves how much support they might extend to their different ranges of products. Hewlett-Packard maintained several lines of workstation products and continued to maintain a line of 68030 and 68040 workstations even after introducing their own PA-RISC processor architecture. After acquiring Apollo Computer, who had also begun to transition to their own RISC architecture from the 68000 family, HP arguably had an obligation to Apollo’s customers and thus renewed their commitment to the Motorola architecture, particularly since Apollo’s own RISC architecture, PRISM, was shelved by HP in favour of PA-RISC.
It is perhaps in the adoption of Sun technology that we might establish the essence of this tale. Amiga Unix was provided with Sun’s OPEN LOOK graphical user interface, and this might have given people reason to believe that there was some kind of deeper alliance. In fact, the alliance was really between Sun and AT&T, attempting to define Unix standards and enlisting the support of Unix suppliers. In seeking to adhere most closely to what could be regarded as traditional Unix – that defined by its originator, AT&T – Commodore may well have been picking technologies that also happened to be developed by Sun.
This tale rests on the assumption that Sun was not able to drive down the prices of its own workstations and that Commodore was needed to lead the way. Yet workstation prices were already being driven down by competition. Already by May 1990, Sun had announced the diskless SPARCstation SPC at the magic $5000 price point, although its lowest-cost colour workstation was reportedly the SPARCstation IPC at a much more substantial $10000. Nevertheless, its competitors were quite able to demonstrate colour workstations at reasonable prices, and eventually Sun followed their lead. Meanwhile, the Amiga 3000UX cost almost $8000 when coupled with a colour monitor.
With such talk of commodity hardware, it must not be forgotten that Sun was not without other options. For example, the company had already delivered SunOS on the Sun386i workstation in 1988. Although rather expensive, costing $10000, and not exactly a generic PC clone, it did support PC architecture standards. This arguably showed the way if the company were to target a genuine commodity hardware platform, and eventually Sun followed this path when making its Solaris operating system available for the Intel x86 architecture. But had Sun had a desperate urge to target commodity hardware back in 1990, partnering with a PC clone manufacturer would have been a more viable option than repurposing an Amiga model. That clone manufacturer could have been Commodore, too, but other choices would have been more convincing.
Conclusions and Reflections
What can we make of all of this? An idle assertion with a veneer of plausibility and a hint of glory denied through the notoriously poor business practices of the usual suspects. Well, we can obviously see that nothing is ever as simple as it might seem, particularly if we indulge every last argument and pursue every last avenue of consideration. And yet, the matter of Commodore making a Unix workstation and Sun Microsystems being “interested in rebadging the A3000UX” might be as simple as imagining a rather short meeting where Commodore representatives present this opportunity and Sun’s representatives firmly but politely respond that the door has been closed on a product range not long for retirement. Thanks but no thanks. The industry has moved on. Did you not get that memo?
Given that there is the essence of a good story in all of this, I consulted what might be the first port of call for Commodore stories: David Pleasance’s book, “Commodore The Inside Story”. Sadly, I can find no trace of any such interaction, with Unix references relating to a much earlier era and Commodore’s Z8000-based Unix machine, the unreleased Commodore 900. Yet, had such a bungled deal occurred, I am fairly sure that this book would lay out the fiasco in plenty of detail. Even Dave Haynie’s chapter, which covers development of the Amiga 3000 and subsequent projects, fails to mention any such dealings. Perhaps the catalogue of mishaps at Commodore is so extensive that a lucrative agreement with one of the most prominent corporations in 1990s computing does not merit a mention.
Interestingly, the idea of a low-cost but relatively low-performance 68030-based workstation from a major Unix workstation vendor did arrive in 1989 in the form of the Apollo DN2500, costing $4000, from Hewlett-Packard. Later on, Commodore would apparently collaborate with HP on chipset development, with this being curtailed by Commodore’s bankruptcy. Commodore were finally moving off the 68000 family architecture themselves, all rather too late to turn their fortunes around. Did Sun need a competitive 68040-based workstation? Although HP’s 9000/425 range was amongst the top sellers, Sun was doing nicely enough with its SPARC-based products, shipping over twice as many workstations as HP.
While I consider this tall tale to be nothing more than folklore, like the reminiscences of football supporters whose team always had a shot at promotion to the bigger league every season, “not once but twice” has a specificity that either suggests a kernel of truth or is a clever embellishment to sustain a group’s collective belief in something that never was. Should anyone know the real story, please point us to the documentation. Or, if there never was any paper trail but you happened to be there, please write it up and let us all know. But please don’t just go onto Wikipedia and scrawl it in the tradition of “I know this!”
For the record, I did look around to see if anyone recorded such corporate interactions on Sun’s side. That yielded no evidence, but I did find something else that was rather intriguing: hints that Sun may have been advised to try and acquire Acorn or ARM. Nothing came from that, of course, but at least this is documentation of an interaction in the corporate world. Of stories about something that never happened, it might also be a more interesting one than the Commodore workstation that Sun never got to rebadge.
Update: I did find a mention of Sun Microsystems and Unix International featuring the Amiga 3000UX on their exhibition stands at the Uniforum conference in early 1991. As noted above, Sun had an interest in promoting adoption of OPEN LOOK, and Unix International – the Sun/AT&T initiative to define Unix standards – had an interest in promoting System V Release 4 and, to an extent, OPEN LOOK. So, while the model may have “even got the attention of Sun Microsystems”, it was probably just a nice way of demonstrating vendor endorsement of Sun’s technology from a vendor who admitted that what it could offer was not “competitive with Sun” and what it had to offer.
Monday, 19 February 2024
Lots of love from out of Hack42
“I Love Free Software Day” is a nice and positive campaign of FSFE to thank the people that enable Free Software on Valentines day. With many gatherings it is also a good opportunity to get together. In the Netherlands there was a workshop in The Hague and we had a meeting in Arnhem at hackerspace Hack42.
The meeting started with a tour for those that haven’t visisted the hackerspace before. Especially because Hack42 only recently moved to this location. Then we could start for real. First an introduction round while enjoying slices of pizza. Everybody told about their personal experiences with Free Software and about the software and people that deserve a thank you.

In this way we learned about different software: web browsers Waterfox and Firefox, browser addon Vimium, desktop environment KDE, music program Audacity, text editor Vim (in memoriam Bram Moolenaar), photo importer Rapid Photo Downloader, smartphone operating systems CalyxOS and UBports, smartphone installer OpenAndroidInstaller, catalog software Omeka, compiler Free Pascal, personal cloud environment Nextcloud, document editor LibreOffice and home automation software Home Assistant. This was an inspiring and insightful round. Remarkable was that for almost everybody Firefox was one of the first Free Software applications.
Writing of thank you’s started mostly with email and chat because most projects and developers lack a postal address. But after some research more and more handwritten I Love Free Software Day postcards ended up on the table, ready to send. It was great to see the collaboration by supporting each others cards with a signature. While were at it we also noticed some thank you’s online on social media. The animated harts by Fedora really stood out.

It was a great evening that really brought the community together. I’m proud of the enthousiasm and kind words. Hopefully the sent thank you’s have a great impact.
I’m already looking forward to a love-filled meeting next year.
Thursday, 15 February 2024
How to deal with Wikipedia’s broken graphs and charts by avoiding Web technology escalation
Almost a year ago, a huge number of graphs and charts on Wikipedia became unviewable because a security issue had been identified in the underlying JavaScript libraries employed by the MediaWiki Graph extension, necessitating this extension’s deactivation. Since then, much effort has been expended formulating a strategy to deal with the problem, although it does not appear to have brought about any kind of workaround, let alone a solution.
The Graph extension provided a convenient way of embedding data into a MediaWiki page that would then be presented as, say, a bar chart. Since it is currently disabled on Wikipedia, the documentation fails to show what these charts looked like, but they were fairly basic, clean and not unattractive. Fortunately, the Internet Archive has a record of older Wikipedia articles, such as one relevant to this topic, and it is able to show such charts from the period before the big switch-off:
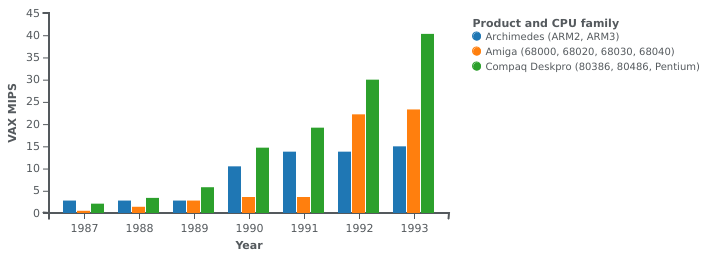
Performance evolution of the Archimedes and various competitors: a chart produced by the Graph extension
The syntax for describing a chart suffered somewhat from following the style that these kinds of extensions tend to have, but it was largely tolerable. Here is an example:
{{Image frame
| caption=Performance evolution of the Archimedes and various competitors
| content = {{Graph:Chart
| width=400
| xAxisTitle=Year
| yAxisTitle=VAX MIPS
| legend=Product and CPU family
| type=rect
| x=1987,1988,1989,1990,1991,1992,1993
| y1=2.8,2.8,2.8,10.5,13.8,13.8,15.0
| y2=0.5,1.4,2.8,3.6,3.6,22.2,23.3
| y3=2.1,3.4,6.6,14.7,19.2,30,40.3
| y4=1.6,2.1,3.3,6.1,8.3,10.6,13.1
| y1Title=Archimedes (ARM2, ARM3)
| y2Title=Amiga (68000, 68020, 68030, 68040)
| y3Title=Compaq Deskpro (80386, 80486, Pentium)
| y4Title=Macintosh II, Quadra/Centris (68020, 68030, 68040)
}}
}}
Unfortunately, rendering this data as a collection of bars on two axes relied on a library doing all kinds of potentially amazing but largely superfluous things. And, of course, this introduced the aforementioned security issue that saw the whole facility get switched off.
After a couple of months, I decided that I wasn’t going to see my own contributions diminished by a lack of any kind of remedy, and so I did the sensible thing: use an established tool to generate charts, and upload the charts plus source data and script to Wikimedia Commons, linking the chart from the affected articles. The established tool of choice for this exercise was gnuplot.
Migrating the data was straightforward and simply involved putting the data into a simpler format. Here is an excerpt of the data file needed by gnuplot, with some items updated from the version shown above:
# Performance evolution of the Archimedes and various competitors (VAX MIPS by year) # Year "Archimedes (ARM2, ARM3)" "Amiga (68000, 68020, 68030, 68040)" "Compaq Deskpro (80386, 80486, Pentium)" "Mac II, Quadra/Centris (68020, 68030, 68040)" 1987 2.8 0.5 2.1 1.6 1988 2.8 1.5 3.5 2.1 1989 2.8 3.0 6.6 3.3 1990 10.5 3.6 14.7 6.1 1991 13.8 3.6 19.2 8.3 1992 13.8 18.7 28.5 10.6 1993 15.1 21.6 40.3 13.1
Since gnuplot is more flexible and more capable in parsing data files, we get the opportunity to tabulate the data in a more readable way, also adding some commentary without it becoming messy. I have left out the copious comments in the actual source data file to avoid cluttering this article.
And gnuplot needs a script, requiring a little familiarisation with its script syntax. We can see that various options are required, along with axis information and some tweaks to the eventual appearance:
set terminal svg enhanced size 1280 960 font "DejaVu Sans,24" set output 'Archimedes_performance.svg' set title "Performance evolution of the Archimedes and various competitors" set xlabel "Year" set ylabel "VAX MIPS" set yrange [0:*] set style data histogram set style histogram cluster gap 1 set style fill solid border -1 set key top left reverse Left set boxwidth 0.8 set xtics scale 0 plot 'Archimedes_performance.dat' using 2:xtic(1) ti col linecolor rgb "#0080FF", '' u 3 ti col linecolor rgb "#FF8000", '' u 4 ti col linecolor rgb "#80FF80", '' u 5 ti col linecolor rgb "#FF80FF"
The result is a nice SVG file that, when uploaded to Wikimedia Commons, will be converted to other formats for inclusion in Wikipedia articles. The file can then be augmented with the data and the script in a manner that is not entirely elegant, but the result allows people to inspect the inputs and to reproduce the chart themselves. Here is the PNG file that the automation produces for embedding in Wikipedia articles:
{kind=link}
Performance evolution of the Archimedes and various competitors: a chart produced by gnuplot and converted from SVG to PNG for Wikipedia usage.
Embedding the chart in a Wikipedia article is as simple as embedding the SVG file, specifying formatting properties appropriate to the context within the article:
[[File:Archimedes performance.svg|thumb|upright=2|Performance evolution of the Archimedes and various competitors]]
The control that gnuplot provides over the appearance is far superior to that of the Graph extension, meaning that the legend in the above figure could be positioned more conveniently, for instance, and there is a helpful gallery of examples that make familiarisation and experimentation with gnuplot more accessible. So I felt rather happy and also vindicated in migrating my charts to gnuplot despite the need to invest a bit of time in the effort.
While there may be people who need the fancy JavaScript-enabled features of the currently deactivated Graph extension in their graphs and charts on Wikipedia, I suspect that many people do not. For that audience, I highly recommend migrating to gnuplot and thereby eliminating dependencies on technologies that are simply unnecessary for the application.
It would be absurd to suggest riding in a spaceship every time we wished to go to the corner shop, knowing full well that more mundane mobility techniques would suffice. Maybe we should adopt similar, proportionate measures of technology adoption and usage in other areas, if only to avoid the inconvenience of seeing solutions being withdrawn for prolonged periods without any form of relief. Perhaps, in many cases, it would be best to leave the spaceship in its hangar after all.
Wednesday, 14 February 2024
Talking more about Freedom not Less
I don’t like the term “Open Source”, because it does not refer to freedom. When a computer program is labeled as “Free” (or “Free to Play” in the case of games) we have
the same problem that “Free” often means a price of zero. By contrast games such “Tanks of Freedom” and “Freedom Saber” really respect users freedom. So I try to avoid using free
as an adjective, and use the term “Freedom” instead: Instead of saying that something is “Free Software”, I say it respects the users freedom.
I Love Free Software Day 2024
I recently did my first FOSDEM talk, about a Free Software project that I contribute to: Using the ECP5 for Libre-SOC prototyping. On the day before I met some of the GNU Guix developers. With this short blogpost I want to say a simple “Thank you” to those people I met at FOSDEM, and those who have started projects such as Libre-SOC, SlimeVR, CrazyFlie and Godot Engine.
Because I Love Free Software, I’ll started my own Free Software project called LibreVR. The FSFE’s sister organisations in North America, has a “Respects Your Freedom” certification program, and I recently have begun working on my hardware design for a wireless VR headset and will soon do regular live streams that document my work on Free Software VR games and hardware.
Monday, 12 February 2024
How does the saying go, again?
If you find yourself in a hole, stop digging? It wasn’t hard to be reminded of that when reading an assertion that a “competitive” Web browser engine needs funding to the tune of at least $100 million a year, presumably on development costs, and “really” $200-300 million.
Web browsers have come a long way since their inception. But they now feature absurdly complicated layout engines, all so that the elements on the screen can be re-jigged at a moment’s notice to adapt to arbitrary changes in the content, and yet they still fail to provide the kind of vanity publishing visuals that many Web designers seem to strive for, ceding that territory to things like PDFs (which, of course, generally provide static content). All along, the means of specifying layout either involves the supposedly elegant but hideously overcomplicated CSS, or to have scripts galore doing all the work, presumably all pounding the CPU as they do so.
So, we might legitimately wonder whether the “modern Web” is another example of technology for technology’s sake: an effort fuelled by Valley optimism and dubiously earned money that not only undermines interoperability and choice by driving out implementers who are not backed by obscene wealth, but also promotes wastefulness in needing ever more powerful systems to host ever more complicated browsers. Meanwhile, the user experience is constantly degraded: now you, the user, get to indicate whether hundreds of data surveillance companies should be allowed to track your activities under the laughable pretense of “legitimate interest”.
It is entirely justified to ask whether the constant technological churn is giving users any significant benefits or whether they could be using less sophisticated software to achieve the same results. In recent times, I have had to use the UK Government’s Web portal to initiate various processes, and one might be surprised to learn that it provides a clear, clean and generally coherent user experience. Naturally, it could be claimed that such nicely presented pages make good use of the facilities that CSS and the Web platform have to offer, but I think that it provides us with a glimpse into a parallel reality where “less” actually does deliver “more”, because reduced technological complication allows society to focus on matters of more pressing concern.
Having potentially hundreds or thousands of developers beavering away on raising the barrier to entry for delivering online applications is surely another example of how our societies’ priorities can be led astray by self-serving economic interests. We should be able to interact with online services using far simpler technology running on far more frugal devices than multi-core systems with multiple gigabytes of RAM. People used things like Minitel for a lot of the things people are doing today, for heaven’s sake. If you had told systems developers forty years ago that, in the future, instead of just connecting to a service and interacting with it, you would end up connecting to dozens of different services (Google, Facebook, random “adtech” platforms running on dark money) to let them record your habits, siphon off data, and sell you things you don’t want, they would probably have laughed in your face. We were supposed to be living on the Moon by now, were we not?
The modern Web apologist would, of course, insist that the modern browser offers so much more: video, for instance. I was reminded of this a few years ago when visiting the Oslo Airport Express Web site which, at that time, had a pointless video of the train rolling into the station behind the user interface controls, making my browser run rather slowly indeed. As an undergraduate, our group project was to design and implement a railway timetable querying system. On one occasion, our group meeting focusing on the user interface slid, as usual, into unfocused banter where one participant helpfully suggested that behind the primary user interface controls there would have to be “dancing ladies”. To which our only female group member objected, insisting that “dancing men” would also have to be an option. The discussion developed, acknowledging that a choice of dancers would first need to be offered, along with other considerations of the user demographic, even before asking the user anything about their rail journey.
Well, is that not where we are now? But instead of being asked personal questions, a bunch of voyeurs have been watching your every move online and have already deduced the answers to those questions and others. Then, a useless video and random developer excess drains away your computer’s interactivity as you type into treacle, trying to get a sensible result from a potentially unhelpful and otherwise underdeveloped service. How is that hole coming along, again?
Saturday, 10 February 2024
Plucker/Palm support removed from Okular for 24.05
We recently remove the Plucker/Palm support in Okular, because it was unmaintained and we didn't even find [m]any suitable file to test it.
If you are using it, you have a few months to step up and bring it back, if not, let's have it rest.
Monday, 29 January 2024
Self-hosted media center

This is a typical documentation post on how to set up a stack of open source tools to create a media center at home. That involves not just the frontend, that you can use on your TV or other devices, but also the tools needed for monitoring the release of certain movies and tv shows.
By the time you reach the end of the post and look at the code you will be wondering "is it worth the time?". I had the same reservations when I started looking to all these tools and it's definitely something to consider. But they do simplify a lot of the tasks that you probably do manually now. And in the end, you get an interface that has a similar user experience as many commercial streaming services do.
To minimize the effort of installing all this software and reducing future maintenance, you can use docker containers. The linuxserver.io project has done some amazing work on this area, providing pre-built container images. They definitely worth your support if you can afford donating.
Stack
- Movies: Radarr
- TV Shows: Sonarr
- Torrents: Transmission. This is probably the only part of the whole stack that you have the flexibility to choose between various options.
- Indexer: Jackett. That works as a proxy that translates queries from all the other apps into torrent trackers http queries, parses the html or json response, and then sends results back to the requesting software (Transmission in this case).
- Subtitles: Bazarr
- Media Center: Jellyfin
Docker Compose
Below I include a docker compose file that will make everything work together. Some prerequisites that you need to take care of:
- Create a new user that would be the one running these docker containers.
- Depending on your Linux distribution, you many need to add this user to the
dockergroup. - Switch to that use and run
id. Use the numeric values fromuidandguidto replace the values forPUIDandPGIDrespectively in the compose file below. - All containers need to share a volume for all the media (see the
volumesconfiguration at the bottom of the file). Hardlinks are being used then to avoid duplicating files or doing unnecessary file transfers. For a more detailed explanation see Radarr's documentation. - If you live in a country that censors Torrent trackers, you need to override DNS settings at least for the Jackett service. The example below is using RadicalDNS for that purpose.
- Adjust the volume paths to your preference. The example is using
/datafor configuration directories per app and/data/publicfor the actual media. - Save this file as
docker-compose.yml.
version: "3.7"
services:
transmission:
image: lscr.io/linuxserver/transmission:latest
container_name: transmission
environment:
- PUID=1000
- PGID=1000
- TZ=Etc/UTC
- UMASK=002
- USER= #optional
- PASS= #optional
volumes:
- /data/transmission:/config
- data:/data
ports:
- 9091:9091
- 51413:51413
- 51413:51413/udp
restart: unless-stopped
sonarr:
image: lscr.io/linuxserver/sonarr:latest
container_name: sonarr
environment:
- PUID=1000
- PGID=1000
- TZ=Etc/UTC
- UMASK=002
volumes:
- /data/sonarr:/config
- data:/data
ports:
- 8989:8989
restart: unless-stopped
radarr:
image: lscr.io/linuxserver/radarr:latest
container_name: radarr
environment:
- PUID=1000
- PGID=1000
- TZ=Etc/UTC
- UMASK=002
volumes:
- /data/radarr:/config
- data:/data
ports:
- 7878:7878
restart: unless-stopped
jackett:
image: lscr.io/linuxserver/jackett:latest
container_name: jackett
environment:
- PUID=1000
- PGID=1000
- TZ=Etc/UTC
- UMASK=022
dns:
- 88.198.92.222
volumes:
- /data/jackett:/config
- data:/data
ports:
- 9117:9117
restart: unless-stopped
bazarr:
image: lscr.io/linuxserver/bazarr:latest
container_name: bazarr
environment:
- PUID=1000
- PGID=1000
- TZ=Etc/UTC
- UMASK=022
volumes:
- /data/bazarr:/config
- data:/data
ports:
- 6767:6767
restart: unless-stopped
jellyfin:
image: lscr.io/linuxserver/jellyfin:latest
container_name: jellyfin
environment:
- PUID=1000
- PGID=1000
- TZ=Etc/UTC
- UMASK=022
- JELLYFIN_PublishedServerUrl= #optional
volumes:
- /data/jellyfin:/config
- data:/data
ports:
- 8096:8096
restart: unless-stopped
volumes:
data:
driver: local
driver_opts:
type: none
device: /data/public
o: bind
Nginx
To make it easier accessing all those services Nginx can be used to map ports exposed by docker under the same domain. You can of course just use your server's IP address, but having a domain name can also make it easier for other people who are not as good as you in memorizing IP addresses (I know right?).
Although it may not considered a good practice to point an external domain to an internal IP, it be very convenient in this use case since it allows you to issue a valid and free SSL certificate using Let's Encrypt.
Below is a simple Nginx configuration that can work together with the docker compose setup described above.
upstream transmission {
server 127.0.0.1:9091;
keepalive 4;
}
upstream sonarr {
server 127.0.0.1:8989;
keepalive 4;
}
upstream radarr {
server 127.0.0.1:7878;
keepalive 4;
}
upstream jackett {
server 127.0.0.1:9117;
keepalive 4;
}
upstream bazarr {
server 127.0.0.1:6767;
keepalive 4;
}
upstream jellyfin {
server 127.0.0.1:8096;
keepalive 4;
}
server {
listen 80;
listen [::]:80;
server_name media.example.com;
return 301 https://$server_name$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name media.example.com;
ssl_certificate "/etc/certs/acme/fullchain.cer";
ssl_certificate_key "/etc/certs/acme/media.example.com.key";
location /radarr {
include /etc/nginx/snippets/proxy_pass.conf;
proxy_pass http://radarr;
}
location /sonarr {
include /etc/nginx/snippets/proxy_pass.conf;
proxy_pass http://sonarr;
}
location /jackett {
include /etc/nginx/snippets/proxy_pass.conf;
proxy_pass http://jackett;
}
location /bazarr {
include /etc/nginx/snippets/proxy_pass.conf;
proxy_pass http://bazarr;
}
location /transmission {
include /etc/nginx/snippets/proxy_pass.conf;
proxy_pass_header X-Transmission-Session-Id;
proxy_pass http://transmission;
}
location / {
include /etc/nginx/snippets/proxy_pass.conf;
proxy_pass http://jellyfin;
}
}
Some things to take care of:
- Replace the
media.example.comserver name with yours. - With the exception of Jellyfin, all other services are served from a path. You may need to adjust the application settings after first run to make this work. As an example, Radarr will need a
<UrlBase>/radarr</UrlBase>at itsconfig.xml. - Since
proxy_passoptions are the same for all services, there is an include directive pointing to the snippet below.
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $http_connection;
Certificates
Since the subdomain will be pointing to an internal IP it can be difficult to use the http challenge to get a certificate. Instead, you can use acme.sh that supports many DNS providers and can automate the DNS challenge verification.
Here is an example command for issuing a certificate for the first time, using Cloudflare DNS:
acme.sh --debug --issue --dns dns_cf -d media.example.com --dnssleep 300
You will need to make that Nginx configuration points to the certificates created by acme.sh.
Run it!
All you have to do is bring docker containers up. Switch to the user you created for that purpose and
go to the directory you saved docker-compose.yml:
docker-compose up -d
As root you should also start Nginx:
systemctl enable --now nginx.service
And that's it!
Configuration
Some post-installation configuration to make everything work together:
- As mentioned above, make sure to adjust "URL base" and use the location path configured in Nginx (eg.
/sonarrfor Sonarr) in all the applications. - Whatever torrent client you choose, make sure to configure it for both Radarr and Sonarr as a Download Client under their Settings options.
- On Transmission, you can choose "Require Encryption" in Preferences > Peers > Encryption mode. You will probably lose some peers, but you'll prevent your ISP from knowing what content you are downloading.
- After you add some torrent trackers to Jackett, you would also need to configure Indexers under Settings options in both Sonarr and Radarr. You should copy the Torznab feed from Jackett and its API key to make it work.
- For subtitles, you need first to add some Providers in Bazarr Settings options. And then create at least one Language Profile under Languages, so that Bazarr knows what languages to look for.
- Both Sonarr and Radarr support importing existing media files and they provide some on-screen instructions on how to structure your files in a way they understand.
Future maintainance
Upgrading the whole stack is just two commands:
docker-compose pull
docker-compose restart
You can also make a systemd service to run the docker containers on boot.
It also helps if you want to check logs and you are familiar with journald.
Here is a simple service file:
[Unit]
Description=Media Center
[Service]
RemainAfterExit=yes
User=username
Group=group
WorkingDirectory=/home/username/
ExecStart=docker-compose up -d
ExecReload=docker-compose restart
ExecStop=docker-compose stop
Restart=always
- Make sure to replace
usernameandgroupwith your settings. - Create this file inside
/etc/systemd/system/
Reload systemd to view the new service file and run and activate the service:
systemctl daemon-reload
systemctl enable --now mediacenter.service
Enjoy!
Friday, 26 January 2024
Slow but Gradual L4Re Progress
It seems a bit self-indulgent to write up some of the things I have been doing lately, but I suppose it helps to keep track of progress since the start of the year. Having taken some time off, it took a while to get back into the routine, familiarise myself with my L4Re efforts, and to actually achieve something.
The Dry, Low-Level Review of Mistakes Made
Two things conspired to obstruct progress for a while, both related to the way I handle interprocess communication (IPC) in L4Re. As I may have mentioned before, I don’t use the L4Re framework’s own IPC libraries because I find them either opaque or cumbersome. However, that puts the burden on me to get my own libraries and tools right, which I failed to do. The offending area of functionality was that of message items which are used to communicate object capabilities and to map memory between tasks.
One obstacle involved memory mapping. Since I had evolved my own libraries gradually as my own understanding evolved, I had decided to allocate a capability for every item received in a message. Unfortunately, when I introduced my own program execution mechanism, when one of the components (the region mapper) would be making its own requests for memory, I had overlooked that it would be receiving flexpages – an abstraction for mapped memory – and would not need to allocate a capability for each such item received. So, very quickly, the number of capabilities became exhausted for that component. The fix for this was fairly straightforward: just don’t allocate new capabilities in cases where flexpages are to be received.
The other obstacle involved the assignment of received message items. When a thread receives items, it should have declared how they should be assigned to capabilities by putting capability indexes into what are known as buffer registers (although they are really just an array in memory, in practice). A message transmitting items will cause the kernel to associate those items with the declared capability indexes, and then the receiving thread will itself record the capability indexes for its own purposes. What I had overlooked was that if, say, two items might be expected but if the first of these is “void” or effectively not transmitting a capability, the kernel does not skip the index in the buffer register that might be associated with that expected capability. Instead, it assigns that index to the next valid or non-void capability in the message.
Since my code had assumed that the kernel would associate declared capability indexes with items based on their positions in messages, I was discovering that my programs’ view of the capability assignments differed from that of the kernel, and so operations on the capabilities they believed to be valid were failing. The fix for this was also fairly straightforward: consume declared capability indexes in order, not skipping any of them, regardless of which items in the message eventually get associated with them.
Some Slightly More Tangible Results
After fixing things up, I started to make a bit more progress. I had wanted to take advantage of a bit more interactivity when testing the software, learning from experiences developing low-level software for various single-board computers. I also wanted to get programs to communicate via pipes. Previously, I had managed to get them to use an output pipe instead of just outputting to the console via the “log” capability, but now I also wanted to be able to present those pipes to other programs as those programs’ input pipes.
Getting programs to use pipes would allow them to be used to process, inspect and validate the output of other programs, hopefully helping with testing and validation of program behaviour. I already had a test program that was able to execute operations on the filesystem, and so it seemed like a reasonable idea to extend this to allow it to be able to run programs from the filesystem, too. Once I solved some of the problems I had previously created for myself, this test program started to behave a bit more like a shell.
The following potentially confusing transcript shows a program being launched to show the contents of a text file. Here, I have borrowed a command name from VMS – an operating system I probably used only a handful of times in the early 1990s – although “spawn” is a pretty generic term, widely used in a similar sense throughout modern computing. The output of the program is piped to another program whose role is to “clip” a collection of lines from a file or, as is the case here, an input stream and to send those lines to its output pipe. Waiting for this program to complete yields the extracted lines.
> spawn bin/cat home/paulb/LICENCE.txt [0]+ bin/cat [!] > pipe + bin/clip - 5 5 > jobs [0] bin/cat [1]+ bin/clip [!] > wait 1 Completed with signal 0 value 0 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed. Preamble Completed with signal 0 value 0 > jobs >
Obviously, this is very rudimentary, but it should be somewhat useful for testing. I don’t want to get into writing an actual shell because this would be a huge task in itself, apparent when considering the operation of the commands illustrated above. The aim will be to port a shell once the underlying library functionality is mature enough. Still, I think it would be an amusing and a tantalising prospect to define one’s own shell environment.
Sunday, 21 January 2024
Keeping the Flame Alive
Like my previous entry, it looks like I'm starting this year by noting that I looked at microcontrollers in 2023 but with not much activity visible on this site. Almost all the public activity was in my Inferno diary, though I also produced a submission for the 9th International Workshop on Plan 9 which I was unfortunately unable to attend in person.
The rant
One reason for being physically absent from IWP9 was work commitments, involving the ordeal of having to prepare for travel to a work event. This involved far too much preparation for very little return, including a booster vaccination that maybe I needed, but which my “employer” was characteristically vague about. In the end, the work event was a pointless exercise in the sort of performative corporate busyworking that even Nokia never managed to slip into during the years I was an employee there. Yes, an actual employee, not a self-employed contractor for a remote-first, try-to-appear-big, overgrown start-up pretending to be a proper corporation.
At least I met a few interesting colleagues in person before the end of my unproductive work experience four months later. Another section to slap on my CV that requires explaining to future employers.
The better things
More productive and interesting things also happened in 2023. As well as virtually attending and presenting at IWP9, I managed to port Inferno to more MicroMod boards, including the SAMD51, Artemis (Apollo3) and Teensy.
Nearer the end of the year, I started to automate builds of these ports, and others, with the results published here. I'm now looking at documenting the way these ports work in this repository. Hopefully, this will make Inferno porting easier for others to approach.
Categories: Inferno, Free Software
Thursday, 11 January 2024
KDE Gear 24.02 branches created
Make sure you commit anything you want to end up in the KDE Gear 24.02 releases to them
Next Dates:
- January 31: 24.02 RC 2 (24.01.95) Tagging and Release
- February 21: 24.02 Tagging
- February 28: 24.02 Release
https://community.kde.org/Schedules/February_2024_MegaRelease
Friday, 05 January 2024
37c3 notes

It’s been a few years since the last Chaos Computer Congress. Same as many other people I highly enjoyed being there. Meeting with people, participating in discussions and a bit of hacking. Most of the things taking place in a congress are quite difficult to describe them in writing and most of happening outside of the presentation rooms. But stil, I thought I should share at least some sessions I enjoyed.
💡 If you use Kodi, install the relevant add-on to watch these in comfort (or any other of the apps)
Talks
-
Predator Files: How European spyware threatens civil society around the world
A technical deep dive into Amnesty International investigation about the spyware alliance Intellexa, which is used by governments to infect the devices and infrastructure we all depend on. -
Tech(no)fixes beware!
Spotting (digital) tech fictions as replacement for social and political change. As the climate catastrophe is imminent and global injustice is rising, a lot of new tech is supposed to help the transition to a sustainable society. Although some of them can actually help with parts of the transition, they are usually discussed not as tools to assist the broader societal change but as replacement for the broader societal change. -
A Libyan Militia and the EU - A Love Story?
An open source investigation by Sea-Watch and other organizations, on how EU (either directly or through Frontex) is collaborating with Tariq Ben Zeyad Brigade (TBZ), a notorious East Libyan land-based militia. TBZ were deeply involved in the failed passage of the boat that sank near Pylos, in which up to 500 people drowned. -
Tractors, Rockets and the Internet in Belarus
How belarusian authoritarian regime is using technologies to repress it's population. With dropping costs of surveillance smaller authoritarian regimes are gaining easier access to different "out of the box" security solutions used mainly to further oppress people. -
Please Identify Yourself!
Focused mostly on EU's eIDAS and India's Aadhaar, and highlighting how Digital Identity Systems proliferate worldwide without any regard for their human rights impact or privacy concerns. Driven by governments and the crony capitalist solutionism peddled by the private sector, these identification systems are a frontal attack on anonymity in the online world and might lead to completely new forms of tracking and discrimination. -
On Digitalisation, Sustainability & Climate Justice
A critical talk about sustainability, technology, society, growth and ways ahead. Which digital tools make sense, which do not and how can we achieve global social emancipation from self-destructive structures and towards ecological sustainability and a and a just world? -
Energy Consumption of Datacenters
The increase of datacenter energy consumption has already been exponential for years. With the AI hype, this demand for energy, cooling and water has increased dramatically. -
Software Licensing For A Circular Economy
How Open Source Software connects to sustainability, based on the KDE Eco initiative. Concrete examples on Free & Open Source Software license can disrupt the produce-use-dispose linear model of hardware consumption and enable the shift to a reduce-reuse-recycle circular model.
Self-organized sessions
Anyone who has paricipated in a Congress knows that there is a wide variety of workshops and self-organized sessions outside of the official curated talks. Most of them not recorded, but still I thought I should share some highlights and thoughts in case people want to dig a bit deeper into these topics.
-
Running a NGO on FreeSoftware
Fascillitated by FSFE to showcase what kind software is being used for day to day operations. Many other tech people from other NGOs participated in the discussion. -
Greg Egan's „Orthogonal“: A universe without timelike dimensions
If you are into hard sci-fi, you may have read a Greg Egan book already. My personal favorite being Permutation City. This session was focusing on the physics behind the Orthogonal trilogy. -
Can you imagine a world beyond capitalism? Exploring economic history with David Graeber's Debt
This was a nice session (and discussion) inspired by David Graeber's book: Debt, The First 5,000 Years. -
Technologies for Disaster
A workshop for people in tech running OpSec trainings (eg. Cryptoparties) for non-tech people in danger. A big portion of the discussion was around threat modeling. -
Decolonize runet! Decolonize network measurements! A provocative take on the Russian sovereign internet project
Not very familiar with Runet before this talk, a russian "sovereign internet" project. -
I pack my ICT-bag for Gaza and I take with me...
This was organized by Cadus, an emergency response organization. As they prepare on going to Gaza, the session was mostly about the challenges of preparing a humanitarian response to a conflict zone. But the discussion was also focused around the situation of communication networks in Gaza and how to workaround current limitations imposed by the Israel state.
Projects
Some quick links on projects captured in my notes based on discussions during the Congress.
- Mastodon has now an automatic translation functionality.
- Waydroid: a container-based approach to boot a full Android system on Linux.
- Snowflake importance was highlighted again by the Tor project people.
- I knew (and have used) Mobile Verification Toolkit before, but it was a good reminder to check its status and talk with journalists that can be potential Predator targets.
- Libre Graphics Meeting is back after 3 years.
Friday, 15 December 2023
Ada & Zangemann in French, Support by Minister of Education and Fan Art

As you might have seen, the French version "Ada & Zangemann - Un conte sur les logiciels, le skateboard et la glace à la framboise" is now available from C & F éditions. On their website, you can also get access to the e-book, which thanks to the "French Department of Digital for Education" is available free of charge. Many things happened around the French version.
On 4 December 2023, the French Minister of Education, Gabriel Attal, presented the book "Ada & #Zangemann" to the APFA parliamentarians meeting in the old Bonn parliament. Afterwards he gifted the book to Anke Rehlinger, Minister President of the Saarland (Germany). Below you see the French video (thanks Erik da Silva and Dario Presutti with several subtitles).
The book was covered in a radio interview by "Radio France", in several articles, including Le Monde, ZDnet, or blogs, as well as TV coverage at Sqool TV with Alexis Kauffmann, from the French Ministry of Education and the person who started with the idea of the French translation.
I was honoured that David Revoy painted this great version of Ada, published under Creative Commons by share alike as well (high resolution and source files also available).

David is doing really great illustration; with his comic Pepper & Carrot as well as with other great work for example for the French organisation Framasoft to promote software freedom. He also publishes his work under the Creative Commons by share alike license.
Furthermore, if you are interested how to create artwork with Free Software, with tools like Krita, also check out his website as he is publishing a lot of tutorials and tools. Below you see his recording of the progress of the Ada illustration which he published on the fediverse.
Rayan (Alès), Matteo (Besançon), Rozenn (Guingamp), Louna (Paris)... more than a hundred students, aged 13 to 19, from four different schools in France, translated this book from German into French over the course of the 2022-2023 school year, sharing the work and coordinating it using online tools.
On 7 December, Sandra Brandstätter, the illustrator, and I were invited to participate in an online meeting organised by the French Ministry of Education, with several of the pupils attending, who translated the book. It was amazing to hear that they have spent several weeks on the project; including writing their own story when they have just seen the illustrations of the book, discussing the characters Ada and Zangemann, the connection of the story to real world development, and of course the translation itself. It was great to have the chance to be there with them and thank some of them personally.
I would like to thank all the people who help to promote the book. Especially, thank you to Alexis Kauffmann from the French Ministry of Education and founder of Framasoft for initialising this project, C & F éditions for publishing it, ADEAF (Association pour le développement de l'enseignement de l'allemand en France) for coordinating the project, the teachers for spending so much time and energy into the project, and most importantly all the pupils who did such a great work!
Thursday, 14 December 2023
Revisiting L4Re System Development Efforts
I had been meaning to return to my investigations into L4Re, running programs in a configurable environment, and trying to evolve some kind of minimal computing environment, but other efforts and obligations intervened and rather delayed such plans. Some of those other efforts had been informative in their own way, though, giving me a bit more confidence that I might one day get to where I want to be with all of this.
For example, experimenting with various hardware devices had involved writing an interactive program that allows inspection of the low-level hardware configuration. Booting straight after U-Boot, which itself provides a level of interactive support for inspecting the state of the hardware, this program (unlike a weighty Linux payload) facilitates a fairly rapid, iterative process of developing and testing device driver routines. I had believed that such interactivity via the text console was more limited in L4Re, and so this opens up some useful possibilities.
But as for my previous work paging in filesystem content and running programs from the filesystem, it had been deferred to a later point in time with fewer distractions and potentially a bit more motivation on my part, particularly since it can take a while to be fully reacquainted with a piece of work with lots of little details that are easily forgotten. Fortuitously, this later moment in time arrived in conjunction with an e-mail I received asking about some of the mechanisms in L4Re involved with precisely the kinds of activities I had been investigating.
Now, I personally do not regard myself as any kind of expert on L4Re and its peculiarities: after a few years of tinkering, I still feel like I am discovering new aspects of the software and its design, encountering its limitations in forms that may be understandable, excusable, both, or neither of these things. So, I doubt that I am any kind of expert, particularly as I feel like I am muddling along trying to implement something sensible myself.
However, I do appreciate that I am possibly the only person publicly describing work of this nature involving L4Re, which is quite unfortunate from a technology adoption perspective. It may not matter one bit to those writing code for and around L4Re professionally whether anyone talks about the technology publicly, and there may be plenty of money to be made conducting business as usual for such matters to be of any concern whatsoever, but history suggests that technologies have better chances of success (and even survival) if they are grounded in a broader public awareness.
So, I took a bit of time trying to make sense out of what I already did, this work being conducted most intensively earlier in the year, and tried to summarise it in a coherent fashion. Hopefully, there were a few things of relevance in that summary that benefited my correspondent and their own activities. In any case, I welcome any opportunity to constructively discuss my work, because it often gives me a certain impetus to return to it and an element of motivation in knowing that it might have some value to others.
I am grateful to my correspondent for initiating this exercise as it required me to familiarise myself with many of the different aspects of my past efforts, helping me to largely pick up where I had left off. In that respect, I had pretty much reached a point of demonstrating the launching of new programs, and at the time I had wanted to declare some kind of success before parking the work for a later time. However, I knew that some tidying up would be required in some areas, and there were some features that I had wanted to introduce, but I had felt that more time and energy needed to be accumulated before facing down the implementation of those features.
The first feature I had in mind was that of plumbing programs or processes together using pipes. Since I want to improve testing of this software, and since this might be done effectively by combining programs, having some programs do work and others assess the output produced in doing this work, connecting programs using pipes in the Unix tradition seems like a reasonable approach. In L4Re, programs tend to write their output to a “log” capability which can be consumed by other programs or directed towards the console output facility, but the functionality seems quite minimal and does not seem to lend itself readily to integration with my filesystem framework.
Previously, I had implemented a pipe mechanism using shared memory to transfer data through pipes, this being to support things like directory listings yielding the contents of filesystem directories. Consequently, I had the functionality available to be able to conveniently create pipes and to pass their endpoints to other tasks and threads. It therefore seemed possible that I might create a pipe when creating a new process, passing one endpoint to the new process for it to use as its output stream, retaining the other endpoint to consume that output.
Having reviewed my process creation mechanisms, I determined that I would need to modify them so that the component involved – a process server – would accept an output capability, supplying it to a new process in its environment and “mapping” the capability into the task created for the process. Then, the program to be run in the process would need to extract the capability from its environment and use it as an output stream instead of the conventional L4Re output functionality, this being provided by L4Re’s native C library. Meanwhile, any process creating another would need to monitor its own endpoint for any data emitted by the new process, also potentially checking for a signal from the new process in the event of it terminating.
Much of this was fairly straightforward work, but there was some frustration in dealing with the lifecycles of various components and capabilities. For example, it is desirable to be able to have the creating process just perform a blocking read over and over again on the reading endpoint of the pipe, only stopping when the endpoint is closed, with this closure occurring when the created process terminates.
But there were some problems with getting the writing endpoint of the pipe to be discarded by the created process, even if I made the program being run explicitly discard or “unmap” the endpoint capability. It turned out that L4Re’s capability allocator is not entirely useful when dealing with capabilities acquired from the environment, and the task API is needed to do the unmapping job. Eventually, some success was eventually experienced: a test program could now launch another and consume the output produced, echoing it to the console.
The next step, of course, is to support input streams to created processes and to potentially consider the provision of an arbitary number of streams, as opposed to prescribing a fixed number of “standard” streams. Beyond that, I need to return to introducing a C library that supports my framework. I did this once for an earlier incarnation of this effort, putting Newlib on top of my own libraries and mechanisms. On this occasion, it might make sense to introduce Newlib initially only for programs that are launched within my own framework, letting them use C library functions that employ these input and output streams instead of calling lower-level functions.
One significant motivation for getting program launching working in the first place was to finally make Newlib usable in a broad sense, completing coverage of the system calls underpinning the library (as noted in its documentation) not merely by supporting low-level file operations like open, close, read and write, but also by supporting process-related operations such as execve, fork and wait. Whether fork and the semantics of execve are worth supporting is another matter, however, these being POSIX-related functions, and perhaps something like the system function (in stdlib.h, part of the portable C process control functions) would be adequate for portable programs.
In any case, the work will continue, hopefully at a slightly quicker pace as the functionality accumulates, with existing features hopefully making new features easier to formulate and to add. And hopefully, I will be able to dedicate a bit more time and attention to it in the coming year, too.
Sunday, 10 December 2023
🌓 Commandline dark-mode switching for Qt, GTK and websites 🌓
This post documents how to toggle your entire desktop between light and dark themes, including your apps and the websites in your browser.
Motivation
Like many other people, I use my computer(s) with varying degrees of ambient light. When there is lots of light, I want a bright theme, but in the evenings, I prefer a dark theme. Switching this for Firefox and several toolkits manually almost drove me crazy, so I will document here how I automated the entire process.
I use the Sway window manager which makes things a bit more difficult, because neither the UI unification mechanisms of GNOME nor KDE automatically kick in. I use Firefox as a browser, and I also want the websites to switch themes. And of course, I want the theme switch to be applied immediately and not just on restartet apps.
Demo
This is what it looks like when it’s done. Dolphin (KDE5), Firefox, the website inside Firefox, and GEdit (GTK) all switch together.
Primary script
#!/bin/sh
current=$(gsettings get org.gnome.desktop.interface color-scheme)
if [ "${current}" != "'prefer-dark'" ]; then #default
echo "Switching to dark."
gsettings set org.gnome.desktop.interface color-scheme prefer-dark
gsettings set org.gnome.desktop.interface gtk-theme Adwaita-dark
gsettings set org.gnome.desktop.interface icon-theme breeze-dark
else # already dark
echo "Switching to light."
gsettings set org.gnome.desktop.interface color-scheme default
gsettings set org.gnome.desktop.interface gtk-theme Adwaita
gsettings set org.gnome.desktop.interface icon-theme breeze
fi
This is the primary script. It works by manipulating the gsettings, so we will have to make everything else follow these settings. The script operates in a toggle-mode, i.e. running it repeatedly switches between light and dark. I had hoped that the color-scheme preference would be the only thing needing change, but the gtk-theme needs to also be switched explicitly. I am not aware of any theme other than Adwaita that works on all toolkits.
Switching the icon-theme is not necessary, but recommended. To get a list of installed icon themes,
ls /usr/share/icons.
Packages
This is the list of packages I installed on Ubuntu 23.10. Note that if you miss certain packages, things will not work
without telling you why. I started this install with a Kubuntu ISO, so depending on your setup, you might need
to install more packages, e.g. libglib2.0-bin provides the gsettings binary.
Package list:
libadwaita # GTK3 theme (auto-installed)
adwaita-qt # Qt5 theme
adwaita-qt6 # Qt6 theme
gnome-themes-extra # GTK2 theme
gnome-themes-extra-data # GTK2 theme and GTK3 dark theme support
qgnomeplatform-qt5 # Needed to tell Qt5 and KDE to use gsettings
#qgnomeplatform-qt6 # If your distro has it
I am not exactly sure where the GTK4 theme comes from, and I have no app to test that. If you want to use the breeze
icon theme, also install breeze-icon-theme.
Configuration
GTK apps
You should already be able to switch GTK apps by running the script. Give it a try!
Firefox app
Firefox should also switch its own theme after invoking the script. If it does not, check the following:
- Your XDG session is treated by Firefox as being GNOME or something similiar.1
- Go to
about:addons, then “Themes” and make sure you have selected “System-Theme (automatic)”. 2 - Go to
about:supportand look for “Windows Protocol”. It should listwayland. If it does not, restart your Firefox withMOZ_ENABLE_WAYLAND=1set in the environment. - Go to
about:supportand look for “Operating System theme”. It should listAdwaita / Adwaita. If it does not, you are likely missing some crucial packages. - Double-check the
gnome-themes-extraor similar packages on your distro. I didn’t have these initially and it prevented Firefox from picking up the theme.
I haven’t tried any of this with Chromium, but I might at some point in the future.
Firefox (websites)
Next are the websites inside Firefox. Make sure your Firefox propagates its own theme settings to its websites:

Websites like https://google.com should now respect your system’s theme. However, running our script will not affect open tabs; you need to reload the tab or open a new tabe to see the effects.
Many other sites do not have a dark theme, though, or do not apply it automatically. To change these sites, install the great dark reader firefox plugin!

Configure the plugin for automatic bahaviour based on the system colours (as shown above). Now is the time to test the script again! Websites controlled by Dark Reader should update immediately without a refresh. This is one reason to prefer Dark Reader’s handling over native switching (like that of https://google.com ).3 If this is the behaviour you want, make sure that websites are not disabled-by-default in Dark Reader (configurable through the small ⚙ under the website URL in the plugin-popup); this is the case for e.g. https://mastodon.social.
An option you might want to play with is found under “more → Change Browser Theme”. This makes the plugin control the Firefox application theme. This is a bit of a logic loop (script changes Firefox theme → triggers Plugin → triggers update of theme), but it often works well and usually gives a slightly different “dark theme look” for the application.
Qt and KDE apps
There are multiple ways to make Qt5 and KDE apps look like GTK apps:
- Select the Adwaita / Adwaita-Dark theme as the native Qt theme (
QT_QPA_PLATFORMTHEME=Adwaita/QT_QPA_PLATFORMTHEME=Adwaita-dark) - Select “gtk2” as the native Qt theme (
QT_QPA_PLATFORMTHEME=gtk2) - Select “gnome” as the native Qt theme (
QT_QPA_PLATFORMTHEME=gnome)
All of these work to a certain degree, and I would have liked to use first option. But for neither 1. nor 2., I was able to achieve “live switching” of already open applications upon invocation of the script.
In theory, one should also be able to use KDE’s lookandfeeltool to switch between the native Adwaita and Adwaita-dark themes (or any other pair of themes), but I was not able to make this work reliably.3
Note that for Qt6 applications to switch theme with the rest, qgnomeplatform-qt6 needs to be installed, which is not available on Ubuntu. Other platforms (like Arch’s AUR) seemed to have it, though.
Note also that in Sway you need to make sure that QT_QPA_PLATFORMTHEME is defined in the context where your applications are started. This is typically not the case within the sway config, so I do the following:
bindsym $mod+space exec /home/hannes/bin/preload_profile krunner
Where preload_profile executes all arguments given to it, but imports ~/.profile before.
Possible extensions
Screen brightness
Before I managed to setup theme-switching correctly, I used a script to control brightness. Now that theme switching works, I don’t do this anymore, but in case you want this additionally:
- You can use
brightnessctlto adjust the brightness of the built-in screen of your Laptop. - You can use
ddcutilto adjust the brightness of an external monitor (this affects actual display brightness not Gamma).
Automation
If desired, you could automate theme switching with cron or map hotkeys to the script.
Closing remarks
I am really happy I got this far; the only thing that does not update live is the icon theme in KDE applications. If anyone has advice on that, I would be grateful!
I have used the method of having everything behave like being on GNOME here. In theory, it should also be possible to set XDG portal to kde and use lookandfeeltool instead of gsettings, but I did not yet manage to make that work.If you have, please let me know!
-
I have verified that an XDG desktop portal of
wlrorgtkworks, and also that a value ofkdedoes not work; so this won’t work within a KDE session. ↩︎ -
If you get spurious flashes of white between website loading or tab-switches, you can later switch this to the “Dark” theme and it should still turn bright when in global bright mode. ↩︎
-
Native dark themes may or may not look better than whatever Dark Reader is doing. I often prefer Dark Reader, because it allows backgrounds that are not fully black. ↩︎ ↩︎
Friday, 08 December 2023
Avoiding nonfree DRM’d Games on GNU/Linux – International Day Against DRM
As a proud user of an FSF-certified Talos II Mainboard and some Rockchip SBCs, I find that is has become easier to avoid using Stream, Valve’s platform for distibution of nonfree computer games with Digital Restrictions Management.
Since I cannot (and don’t want to) play any of the non-free games from Steam, I have begun developing my own games that bring freedom to the users. Some of those games are “clones” of popular nonfree VR games such as Beat Saber and VRChat.
I’m also going to sell copies of those games and hardware that I am currently working on. The games are copylefted Free Software and the hardware is designed with the Respects Your Freedom Certification in mind.
For me there is an ethical imperative to make the game art and hardware designs free too. I don’t think that those things have to be copylefted, as most GNU software is. The distribution service/site must also be ethical, which means that it is not SaaSS and does not send any non-free JavaScript.
I also plan to provide Windows binaries, cross compiled using MinGW and tested on Proton on my Opteron system. My goal here is giving users of Windows a taste of freedom.
I replaced Windows with GNU/Linux long time ago and want to encourage gamers to do the same. The first free game that I had on a Windows 3.1 as a child was GNU Chess. At that time I never heard about Linux and did not know what GNU is. But I started learning to program and wanted to make use of freedom 1.
Today I use GNU Guix which can run on any GNU/Linux distro and even Android. No nonfree software is needed to run libsurvive and spreadgine, so both can be included in Guix. Instead of Steam, I now use Guix for gaming.
When games included in Guix respect Freedom, this does not mean that users do not have to pay to play the games. Guix has substitutes for local builds, and users could either pay for those substitutes or build the game locally. Even when the artwork is non-free, downloading the artwork could be done without running any non-free javascript or other proprietary malware. The FSF* could run Crowdfunding campaings for freedom respecting games and host game servers on hardware that has been RYF certified.
People often think it is not feasible in the current situation to develop a free replacement for some of the most popular nonfree VR games including “VRChat”. But projects such as V-SekaiV-Sekai have proven that this is not the case, free games can be developed and users who value freedom will only play those free games and reject the nonfree games.
Since I want to promote the cause of freedom in gaming, I am settung up a website which lists only libre games that can run on GNU/Linux and/or liberated
consoles. The page includes integration for GNU Taler so that users can donate or buy games and/or RYFed gaming hardware, including a future Guix Deck.
Firefox and Monospaced Fonts
This has been going on for years, but a recent upgrade brought it to my attention and it rather says everything about what is wrong with the way technology is supposedly improved. If you define a style for your Web pages using a monospaced font like Courier, Firefox still decides to convert letter pairs like “fi” and “fl” to ligatures. In other words, it squashes the two letters together into a single character.
Now, I suppose that it does this in such a way that the resulting ligature only occupies the space of a single character, thereby not introducing proportional spacing that would disrupt the alignment of characters across lines, but it does manage to disrupt the distribution of characters and potentially the correspondence of characters between lines. Worst of all, though, this enforced conversion is just ugly.
Here is what WordPress seems to format without suffering from this problem, by explicitly using the “monospace” font-style identifier:
long client_flush(file_t *file);
And here is what happens when Courier is chosen as the font:
long client_flush(file_t *file);
In case theming, browser behaviour, and other factors obscure the effect I am attempting to illustrate, here it is with the ligatures deliberately introduced:
long client_flush(file_t *file);
In fact, the automatic ligatures do remain as two distinct letters crammed into a single space whereas I had to go and find the actual ligatures in LibreOffice’s “special character” dialogue to paste into the example above. One might argue that by keeping the letters distinct, it preserves the original text so that it can be copied and pasted back into a suitable environment, like a program source file or an interactive prompt or shell. But still, when the effect being sought is not entirely obtained, why is anyone actually bothering to do this?
It seems to me that this is yet another example of “design” indoctrination courtesy of the products of companies like Apple and Adobe, combined with the aesthetics-is-everything mentality that values style over substance. How awful it is that someone may put the letter “f” next to the letter “i” or “l” without pulling them closer together and using stylish typographic constructs!
Naturally, someone may jump to the defence of the practice being described here, claiming that what is really happening is kerning, as if someone like me might not have heard of it. Unfortunately for them, I spent quite a bit of time in the early 1990s – quite possibly before some of today’s “design” gurus were born – learning about desktop publishing and typography (for a system that had a coherent outline font system before platforms like the Macintosh and Windows did). Generally, you don’t tend to apply kerning to monospaced fonts like Courier: the big hint is the “monospaced” bit.
Apparently, the reason for this behaviour is something to do with the font library being used and it will apparently be fixed in future Firefox releases, or at least ones later than the one I happen to be using in Debian. Workarounds using configuration files reminiscent of the early 2000s Linux desktop experience apparently exist, although I don’t think they really work.
But anyway, well done to everyone responsible for this mess, whether it was someone’s great typographic “design” vision being imposed on everyone else, or whether it was just that yet more technologies were thrown into the big cauldron and stirred around without any consideration of the consequences. I am sure yet more ingredients will be thrown in to mask the unpleasant taste, also conspiring to make all our computers run more slowly.
Sometimes I think that “modern Web” platform architects have it as their overriding goal to reproduce the publishing solutions of twenty to thirty years ago using hardware hundreds or even thousands of times more powerful, yet delivering something that runs even slower and still producing comparatively mediocre results. As if the aim is to deliver something akin to a turn-of-the-century Condé Nast publication on the Web with gigabytes of JavaScript.
But maybe, at least for the annoyance described here, the lesson is that if something is barely worth doing, largely because it is probably only addressing someone’s offended sense of aesthetics, maybe just don’t bother doing it. There are, after all, plenty of other things in the realm of technology and beyond that more legitimately demand humanity’s attention.
Saturday, 18 November 2023
Experiments with a Screen
Not much to report, really. Plenty of ongoing effort to overhaul my L4Re-based software support for the MIPS-based Ingenic SoC products, plus the slow resumption of some kind of focus on my more general framework to provide a demand-paged system on top of L4Re. And then various distractions and obligations on top of that.
Anyway, here is a picture of some kind of result:

The MIPS Creator CI20 driving the Pirate Audio Mini Speaker board’s screen.
It shows the MIPS Creator CI20 using a Raspberry Pi “hat”, driving the screen using the SPI peripheral built into the CI20’s JZ4780 SoC. Although the original Raspberry Pi had a 26-pin expansion header that the CI20 adopted for compatibility, the Pi range then adopted a 40-pin header instead. Hopefully, there weren’t too many unhappy vendors of accessories as a result of this change.
What it means for the CI20 is that its primary expansion header cannot satisfy the requirements of the expansion connector provided by this “hat” or board in its entirety. Instead, 14 pins of the board’s connector are left unconnected, with the board hanging over the side of the CI20 if mounted directly. Another issue is that the pinout of the board employs a pin as a data/command pin instead of as its designated function as a SPI data input pin. Whether the Raspberry Pi can configure itself to utilise this pin efficiently in this way might help to explain the configuration, but it isn’t compatible with the way such pins are assigned on the CI20.
Fortunately, the CI20’s designers exposed a SPI peripheral via a secondary header, including a dedicated data/command pin, meaning that a few jumper wires can connect the relevant pins to the appropriate connector pins. After some tedious device driver implementation and accompanying frustration, the screen could be persuaded to show an image. With the SPI peripheral being used instead of “bit banging”, or driving the data transfer to the screen controller directly in software, it became possible to use DMA to have the screen image repeatedly sent. And with that, the screen can be used to continuously reflect the contents of a generic framebuffer, becoming like a tiny monitor.
The board also has a speaker that can be driven using I2S communication. The CI20 doesn’t expose I2S signals via the header pins, instead routing I2S audio via the HDMI connector, analogue audio via the headphone socket, and PCM audio via the Wi-Fi/Bluetooth chip, presumably supporting Bluetooth audio. Fortunately, I have another means of testing the speaker, so I didn’t waste half of my money buying this board!
Thursday, 26 October 2023
FSFE information stall on Veganmania Rathausplatz 2023


To celebrate the 25th anniversary of the Veganmania summer festivals this year a third instance of the festival took place between October 6th and 8th. It was the biggest ever. And once more volunteers of the local FSFE supporters manned an information stall about free software and the relevance of independence on our computing devices.
It is somewhat odd that over the years it has became somewhat daunting to describe the tested ingredients for a very successful information desk again and again. But we once more could use this opportunity to talk to many interested passers by and to tell them about the advantages free software grants its users and how important this is in a society that increasingly interacts using electronic devices. Therefore, it shouldn’t still surprise how well the comparably big and thick Public Money, Public Code
brochures are received. I would never have guessed that such a large and rather technical take away would find so many people appreciating it enough to carry it around with them for hours. The newest delivery of materials ordered for this event were exhausted before the street festival concluded. Even if I have long switched to making specifically large orders because the usual information desk packages the FSFE office suggests wouldn’t even last for two hours on the events we take part in. Luckily we could at least re-stock our most important orange leaflet listing ten of the most widely used GNU distributions combined with a few words explaining the differences mid-way through the event because a print shop had open on the weekend and we could print it out early in the morning before people showed up for the street festival.
Despite taking place in Autumn the weather was mostly very mild. Unfortunately, on the last day rain still caught up with us by slowly growing stronger from a very light spree to proper rain. Therefore, it was hard to decide when we should actually pack-up our information material in order to protect it from getting destroyed by the rain. Especially because the people on the festival didn’t seem to mind and carried on visiting our desk. But at some point stapling the leaflets under our umbrella wasn’t good enough any longer and we needed to remove the top soaked through materials and finally pack-up. So we quit an hour early but probably didn’t sacrifice very much potential. At least this way we ourselves had the chance to actually grab some delicious food from the plentiful offerings at the Veganmania.
Our posters have become rather worn out over the years and don’t look very well any longer. We need to replace them. Probably made out of more resilient material than paper. Then the constant putting them up with sellotape and removing it after our information desks are done shouldn’t have an irreversible effect on them any longer.
But the end of the event wasn’t all that came from: This time a manager of a volunteer-led local museum was quick to follow-up on our recommendation to not throw away older laptops that couldn’t run the pre-installed proprietary operating system any longer. And it wouldn’t be a good idea either because there wouldn’t be any further security updates either. So, a few days after the event we installed GNU systems with a lightweight desktop on four laptops and she also asked for a talk in the museum where we could explain the value of free software. And she even suggested that she could make a lottery among the attendees to win two of the revived devices. It is planned to happen at some point next year. We are looking forward to that.
Promote Digital Maturity by reading books to others
In July this year I participated at Digitalcourage's "Aktivcongress", a yearly meeting for activists in Germany. Digitalcourage has been campaigning for a world worth living in the digital age since 1987. I participated in sessions about Free Software, had a lightning talk about the "I love Free Software day", and I did two readings of the book "Ada & Zangemann - A Tale of Software, Skateboards, and Raspberry Ice Cream" to inspire participants from other organisations how they could use the book to better accomplish their goals.

The feedback about the book was great, especially the fact that all the materials to read aloud yourself, presentation slides with the illustrations, and the texts with markers to change slides are available in our git repository (thanks to the many contributors who made it possible that the book is meanwhile available in Arabic, Danish, English, French, German, Italian, Ukrainian, and Valencian, and there are more translation efforts going on).
Furthermore I had many interesting conversations with Jessica Wawrzyniak and Leena Simon, who wrote books about digital topics in German-- so we thought we team up and raise awareness about the books, and the ways how you can use them to foster digital rights.
-
Jessica Wawrzyniak's book is the children's and young people's encyclopedia "#Kids #digital #genial - Protect yourself and your data!" (in German), which in more than 150 short entries explain terms from the media world and opens up political, economic and social contexts, and her book "Screen Teens - How we accompany young people into digital responsibility" (in German)
-
Leena Simon's "Digital Literacy - How we save the world with a new attitude" (in German) in which she shows ways in which people can self-determined work for freedom and democracy in a digital world.
One occasion to make use of those books is now Friday, 17 November, which is the nationwide Read Aloud Day in Germany, when everyone is encouraged to read to children in a kindergarten, school, library or other social institution. Together with Digitalcourage e.V. the FSFE support this nice tradition and we are promoting the reading of available books that highlight important aspects of digital rights on this day.
As Jessica Wawrzyniak, media educator at Digitalcourage wrote "Topics relating to digitization, media use and data protection are not yet sufficiently addressed in daycare centers, schools and social institutions, but they can be addressed in a child-friendly way."

In recent months, I read the book to over 1000 children. It was always a great fulfilment to discuss the book with the participants, and see how they are afterwards motivated to tinker, be creative, while they still also think about topics like equality, inclusion, democracy and activism.
Children and young people should be encouraged to stand up for their basic rights, including the right to informational self-determination, and to shape the information technology world in a self-determined and responsible way -- which includes Free Software.
So we encourage you to grab one of those books, or others you enjoy which are suitable for reading to children and young adults, read it to others, and have discussions with them.
If you live in Germany, you can use the 17 November. But do not feel limited by that. Reading books to others and discussing topics, you feel are important for society, should not be limited to one day.
Planet FSFE (en):  RSS 2.0 | Atom |
RSS 2.0 | Atom |  FOAF |
FOAF | 
Albrechts Blog
Alessandro's blog
Andrea Scarpino's blog
André Ockers on Free Software
Bela's Internship Blog
Bernhard's Blog
Bits from the Basement
Blog of Martin Husovec
Bobulate
Brian Gough’s Notes
Chris Woolfrey — FSFE UK Team Member
Ciarán’s free software notes
Colors of Noise - Entries tagged planetfsfe
Communicating freely
Daniel Martí's blog
David Boddie - Updates (Full Articles)
ENOWITTYNAME
English Planet – Dreierlei
English – Alessandro at FSFE
English – Alina Mierlus – Building the Freedom
English – Being Fellow #952 of FSFE
English – Blog
English – FSFE supporters Vienna
English – Free Software for Privacy and Education
English – Free speech is better than free beer
English – Jelle Hermsen
English – Nicolas Jean's FSFE blog
English – Paul Boddie's Free Software-related blog
English – The Girl Who Wasn't There
English – Thinking out loud
English – Viktor's notes
English – With/in the FSFE
English – gollo's blog
English – mkesper's blog
English – nico.rikken’s blog
Escape to freedom
Evaggelos Balaskas - System Engineer
FSFE interviews its Fellows
FSFE – Frederik Gladhorn (fregl)
FSFE – Matej's blog
Fellowship News
Free Software & Digital Rights Noosphere
Free Software with a Female touch
Free Software –
Free Software – hesa's Weblog
Free as LIBRE
Free software - Carmen Bianca BAKKER
Free, Easy and Others
FreeSoftware – egnun's blog
From Out There
Giacomo Poderi
Green Eggs and Ham
Handhelds, Linux and Heroes
HennR’s FSFE blog
Henri Bergius
In English — mina86.com
Inductive Bias
Karsten on Free Software
Losca
MHO
Mario Fux
Matthias Kirschner's Web log - fsfe
Max Mehl (English)
Michael Clemens
Myriam's blog
Mäh?
Nice blog
Nikos Roussos - opensource
Posts on Hannes Hauswedell
Pressreview
Rekado
Riccardo (ruphy) Iaconelli – blog
Saint’s Log
TSDgeos' blog
Tarin Gamberini
Technology – Intuitionistically Uncertain
The trunk
Thomas Løcke Being Incoherent
Told to blog - Entries tagged fsfe
Tonnerre Lombard
Vincent Lequertier's blog
Vitaly Repin. Software engineer's blog
Weblog
Weblog
Weblog
Weblog
Weblog
Weblog
a fellowship ahead
agger's Free Software blog
anna.morris's blog
ayers's blog
bb's blog
blog
en – Florian Snows Blog
en – PB's blog
en – rieper|blog
english on Björn Schießle - I came for the code but stayed for the freedom
english – Davide Giunchi
english – Torsten's FSFE blog
foss – vanitasvitae's blog
free software blog
freedom bits
freesoftware – drdanzs blog
fsfe – Thib's Fellowship Blog
julia.e.klein’s blog
marc0s on Free Software
pichel’s blog
planet-en – /var/log/fsfe/flx
polina's blog
softmetz' anglophone Free Software blog
stargrave's blog
tobias_platen's blog
tolld's blog
wkossen’s blog
yahuxo’s blog