 RSS 2.0
RSS 2.0 FOAF
FOAF
Thursday, 21 November 2013
MutterWare #2: aller (encore) plus loin dans son utilisation du mail

[Note : Je vais cesser d’écrire en français sur ce blog. Désormais, ce que j’écris en français est publié sur mon blog personnel, y compris lorsque cela est lié à la FSFE.]
Mardi soir, Nicolas organisait le 2e MutterWare. Mais qu’est-ce que c’est que ça ?
Le MutterWare est une réunion d’utilisateurs de Mutt qui veulent partager leurs bonnes pratiques et quelques astuces bien utiles. Les non-utilisateurs de mutt curieux sont bienvenus, surtout s’ils sont légèrement blasés de leur client email 
Le nom est inspiré directement du TupperVIM organisé chez Mozilla, à Paris.
Pour cette deuxième édition, nous avons cette fois été invités à admirer les bureaux somptueux de Mozilla boulevard Montmartre. Voir la photo prise par Yoann :

Encore une fois, ce MutterWare était un bon mélange entre utilisateurs (très) expérimentés, et non-utilisateurs de Mutt curieux de voir comment fonctionne le machin et prêts à ouvrir leur terminal pour commencer à configurer la bête !
Quelques informations ont été ajoutées au wiki : https://wiki.fsfe.org/groups/Paris/Mutterware.
Pour ma part, j’insisterai sur cette très bonne page qui permet de démarrer sur Mutt. C’est en anglais mais c’est bien écrit. Cette page a cependant deux défauts à mon avis : elle se concentre sur l’usage à partir d’un serveur mail chez Google (or Gmail a des tas de particularités pas très orthodoxes) et elle se limite à un seul compte. Or je ne sais pas pour vous mais moi, j’ai deux comptes : l’un est plus, « personnel ».
Enfin, la cerise sur le gâteau, c’est Emmanuel qui l’a apportée en me montrant l’outil t-prot, qui permet de nous débarrasser de toutes ces petites choses qui peuvent être désagréables dans le mail : les gens qui font des citations trop longues, les gens qui font du top-posting ou encore les gens ont des signatures de 3 kilomètres. T-prot a aussi des fonctions particulières pour Mutt, comme par exemple l’argument --pgp-move qui déplace les informations relatives aux signatures openPGP d’un email vers le bas, et non vers le haut comme c’est le cas par défaut, ce qui permet d’avoir accès plus directement au contenu du mail, sans avoir à scroller ! Plus d’infos sur la config T-prote d’Emmanuel sur le wiki.
Du coup, j’ai touché pas mal à ma config (dispo sur https://github.com/hugoroy/.mutt). Tout est désormais plus sobre depuis que j’ai modifié les barres de statuts, retiré la barre d’aide, et remplacé quelques codes couleurs. Lire ses mails sur Mutt est encore plus plaisant qu’avant
À bientôt pour la 3e édition ! N’hésitez pas à vous inscrire sur la liste fsfe Paris https://lists.fsfe.org/mailman/listinfo/paris ou à nous rejoindre sur irc #fellows-paris.
Wednesday, 01 May 2013
Installation d’etherpad-lite avec ldap / ssl / apache

Au boulo, suite à une demande d’utilisateurs, j’ai dû mettre en place un service de publication collaborative en ligne. Le choix s’est porté sur etherpad-lite qui a fait ses preuves.
Celui-ci est disponible sur le site: http://etherpad.org/
Installation
Le port n’existant pas dans gentoo, on va devoir se taper l’installation à la pogne.
Donc dans un premier temps, on installe les dépendances (ici node.js) puis on récupère l’archive.
[bash]
echo "net-libs/nodejs ~amd64" >> /etc/portage/package.keywords
emerge -uD nodejs
cd /opt
git clone git://github.com/ether/etherpad-lite.git
[/bash]
On va créer l’utilisateur et le groupe etherpad et passer le dossier sous cette identité
[bash]
useradd etherpad -U -d /opt/etherpad-lite -s /bin/bash
chown etherpad:etherpad ./etherpad-lite
cd ./etherpad-lite/bin
[/bash]
Enfin on teste:
[bash]
ulysse bin # su etherpad -c /opt/etherpad-lite/bin/run.sh
Ensure that all dependencies are up to date… If this is the first time you have run Etherpad please be patient.
Ensure jQuery is downloaded and up to date…
Clear minfified cache…
ensure custom css/js files are created…
start…
[2013-04-29 17:10:38.824] [WARN] console – You need to set a sessionKey value in settings.json, this will allow your users to reconnect to your Etherpad Instance if your instance restarts
[2013-04-29 17:10:38.826] [WARN] console – DirtyDB is used. This is fine for testing but not recommended for production.
[2013-04-29 17:10:39.211] [INFO] console – Installed plugins: ep_etherpad-lite
[2013-04-29 17:10:39.226] [INFO] console – Your Etherpad Lite git version is 2273cf9
[2013-04-29 17:10:39.226] [INFO] console – Report bugs at https://github.com/ether/etherpad-lite/issues
[2013-04-29 17:10:39.260] [INFO] console – info – ‘socket.io started’
[2013-04-29 17:10:39.282] [INFO] console – You can access your Etherpad-Lite instance at http://127.0.0.1:9001/
[2013-04-29 17:10:39.282] [WARN] console – Admin username and password not set in settings.json. To access admin please uncomment and edit ‘users’ in settings.json
[/bash]
En allant dans votre butineur favori, vous devriez voir ceci à l’adresse: http://127.0.0.1:9001/
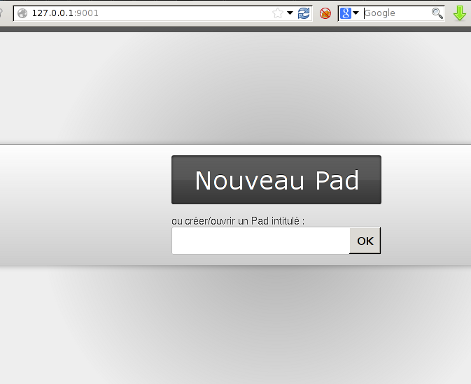
Nous avons donc maintenant, une installation sommaire avec plein de log WARN (Cf ci-dessus)
Configuration
On va stocker les données dans une base MySQL. On va donc créer une base “etherpad” ainsi qu’un utilisateur “ethertap” avec des droits dessus:
[sql]
CREATE DATABASE etherpad CHARACTER SET UTF8 COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON etherpad.* TO ‘etherpad’@’localhost’ IDENTIFIED BY ‘MOTDEPASSEMYSQL’;
[/sql]
Pour la connexion à MySQL, on passera par les sockets
Ici vous trouverez le nécessaire pour la génération des clés / certificats du serveur.
Puis, on complète le fichier de configuration est: /opt/etherpad-lite/settings.json
[bash highlight=”14,24″]
{
"title": "Nom du PAD",
"favicon": "favicon.ico",
"ip": "adresse d’écoute",
"port" : 9001,
"sessionKey" : "chaine_session",
"ssl" : {
"key" : "/etc/ssl/epad/epl-server.key",
"cert" : "/etc/ssl/epad/epl-server.crt"
},
"dbType" : "mysql",
"dbSettings" : {
"user" : "etherpad",
"port" : "/var/run/mysqld/mysqld.sock",
"password": "MOTDEPASSEMYSQL",
"database": "etherpad"
},
"defaultPadText" : "Message d’accueil sur un PAD vierge",
"requireSession" : false,
"editOnly" : false,
"minify" : true,
"maxAge" : 21600,
"abiword" : null,
"requireAuthentication": false,
"requireAuthorization": false,
"users": {
"admin": {
"password": "MOTDEPASSEADMIN",
"is_admin": true
}
},
"socketTransportProtocols" : ["xhr-polling", "jsonp-polling", "htmlfile"],
"loglevel": "INFO",
"logconfig" : {
"appenders": [
{
"type": "file",
"filename": "/opt/etherpad-lite/etherpad.log",
"backups": 3
}
]
}
}
[/bash]
En ligne 14, on indique à MySQL que l’on veut s’y connecter au moyen de sockets.
En ligne 24, on a désactivé l’authentification pour les utilisateurs classiques, car on va se servir de ldap avec apache pour les authentifier.
Maintenant vous pouvez vous rendre sur: https://adresse_d_ecoute:9001
là vous devriez voir l’interface de création / ouverture d’un document.
L’interface web d’administration se trouve à l’adresse: https://adresse_d_ecoute:9001/admin/
vous y trouverez un onglet concernant les plugins, a vous de personnaliser votre etherpad-lite…
Mode reverse-proxy avec Apache + Authentification LDAP
Maintenant, on va faciliter l’accès: on va se donner une joli adresse web et faire une translation de port
Il va falloir installer apache avec son module proxy et modifier le fichier /etc/conf.d/apache2 en rajoutant -D PROXY dans la liste des options de lancement.
On va avoir besoin aussi d’un fichier de configuration de l’hôte virtuel:
[bash highlight=”11-21,29-41″]
<VirtualHost ADRESSE_SERVEUR:443>
ServerAdmin admin@localhost
ServerName NOM_DOMAINE
ServerSignature Off
CustomLog /var/log/apache2/etherpad_access.log combined
ErrorLog /var/log/apache2/etherpad_error.log
SSLEngine on
SSLCipherSuite ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+EXP:+eNULL
SSLCertificateFile /etc/ssl/epad/epl-server.crt
SSLCertificateKeyFile /etc/ssl/epad/epl-server.key
<Location />
AuthType Basic
AuthName "Access restreint"
AuthBasicProvider ldap
AuthzLDAPAuthoritative off
AuthLDAPRemoteUserIsDN off
AuthLDAPGroupAttributeIsDN off
AuthLDAPURL ldap://serveur_ldap/base_ldap?uid?sub
Require valid-user
addDefaultCharset UTF-8
</Location>
<Directory />
Options -Indexes FollowSymlinks Multiviews
AllowOverride All
Order deny,allow
Allow from all
</Directory>
<IfModule mod_proxy.c>
ProxyVia On
SSLProxyEngine on
ProxyRequests Off
SSLProxyCACertificateFile /etc/ssl/epad/epl-server.crt
ProxyPass / https://ADRESSE_ECOUTE_ETHERPAD:9001/
ProxyPassReverse / https://ADRESSE_ECOUTE_ETHERPAD:9001/
ProxyPreserveHost on
<Proxy *>
Options FollowSymLinks MultiViews
AllowOverride All
Order deny,allow
allow from all
</Proxy>
</IfModule>
</VirtualHost>
[/bash]
Les lignes 11 à 21 concernent l’authentification via LDAP. Les lignes 30 à 42 concernent le renvoie vers l’adresse du serveur etherpad sur le port 9001.
EtherPad-lite comme un service
Ici vous trouverez les différents scripts à mettre pour pouvoir lancer Etherpad-lite comme les autres services sur votre serveur.
En gros, sur la gentoo, on va créer un script /etc/init.d/etherpad-lite:
[bash]
#!/sbin/runscript
# Copyright 1999-2013 Gentoo Foundation
# Distributed under the terms of the GNU General Public License v2
# $Header: $
depend() {
need net mysql
after apache2
}
start() {
ebegin "Starting ${RC_SVCNAME}"
start-stop-daemon -S -m –pidfile ${PIDFILE} -x ${NODE} -u ${USER} -d "${ETHERPATH}" -b — ${ARGS}
eend $?
}
stop() {
ebegin "Stopping ${RC_SVCNAME}"
start-stop-daemon -K -x ${NODE} -u ${USER} -d "${ETHERPATH}"
eend $?
}
[/bash]
suivit d’un petit:
[bash]
chmod 0755 /etc/init.d/etherpad-lite
[/bash]
et son fichier de conf /etc/conf.d/etherpad-lite:
[bash]
ETHERPATH="/opt/etherpad-lite/"
ARGS="node_modules/ep_etherpad-lite/node/server.js"
ETHERLOG="${ETHERPATH}/etherpad.log"
USER="etherpad"
PIDFILE="/var/run/etherpad-lite.pid"
NODE="/usr/bin/node"
[/bash]
on test le lancement du service:
[bash]
/etc/init.d/etherpad-lite start
[/bash]
On se rend sur l’adresse habituelle et on devrait voir la même chose.
Si tout fonctionne bien, il nous suffit de configurer le lancement automatique:
[bash]
rc-update add etherpad-lite default
[/bash]
Et de changer le shell de connexion de l’utilisateur etherpad dans /etc/password en remplaçant /bin/bash par /sbin/nologin
Rotation des logs
On va rajouter la rotation des logs. Pour ce faire, on ajoute un petit script:
/etc/logrotate.d/etherpad-lite
[bash]
/opt/etherpad-lite/*log {
missingok
notifempty
sharedscripts
postrotate
/etc/init.d/etherpad-lite restart > /dev/null 2>&1 || true
endscript
}
[/bash]
Exports supplémentaires
Afin de donner la possibilité de réaliser des exports sympas comme pdf, odt, doc, etc. On va avoir besoin d’abiword avec son plugin “command-line”.
[bash]
echo "app-office/abiword plugins" >> /etc/portage/package.use
emerge -D abiword
[/bash]
Puis dans le fichier de configuration d’etherpad-lite (/opt/etherpad-lite/settings.json), on rajoute le chemin vers le binaire abiword que l’on obtiens ainsi:
[bash]
whereis abiword
[/bash]
Dans ce fichier, en ligne 23, on remplace la valeur “null” en face d’abiword par le chemin précédemment trouvé.
Reste à faire:
Il ne reste plus qu’à binder l’authentification LDAP sur celle de etherpad. (Investigation en cours)
N’hésitez pas à me faire remonter vos remarques si ça ne paraît pas clair voire faux.
Wednesday, 03 April 2013
Récupération de données sous linux [WiP]
>> Ceci est un Work in Progress, je le compléterai au fur et à mesure <<
Disclaimer: Bien évidemment, tout ce qui pourrait survenir en suivant les indications mentionnées ci-dessous relève de votre entière responsabilité.
J’ai dû récemment faire de la récupération de données sur un disque de portable contenant des partitions de type NTFS. La machine ne voulait plus démarrer dessus et bien évidemment le possesseur du-dit disque n’avait pas de sauvegarde récente.
Le disque avait une taille de 500Go.
Il existe toute une série d’utilitaires disques qui permettent de traiter ce type de situation.
- badblocks
- smartctl
- fdisk
- ddrescue
- Les utilitaires propres au système de fichier que vous utilisez.
1/ On branche le disque via un adaptateur usb, puis on regarde les logs avec dmesg.
[bash highlight=”24,31″]
dmesg
[185475.284780] hub 2-1:1.0: state 7 ports 8 chg 0000 evt 0004
[185475.285088] hub 2-1:1.0: port 2, status 0101, change 0001, 12 Mb/s
[185475.389105] hub 2-1:1.0: debounce: port 2: total 100ms stable 100ms status 0x101
[185475.400067] hub 2-1:1.0: port 2 not reset yet, waiting 10ms
[185475.462195] usb 2-1.2: new high-speed USB device number 7 using ehci_hcd
[185475.472994] hub 2-1:1.0: port 2 not reset yet, waiting 10ms
[185475.547776] usb 2-1.2: default language 0x0409
[185475.548612] usb 2-1.2: udev 7, busnum 2, minor = 134
[185475.548616] usb 2-1.2: New USB device found, idVendor=152d, idProduct=2338
[185475.548618] usb 2-1.2: New USB device strings: Mfr=1, Product=2, SerialNumber=5
[185475.548620] usb 2-1.2: Product: USB to ATA/ATAPI bridge
[185475.548622] usb 2-1.2: Manufacturer: JMicron
[185475.548623] usb 2-1.2: SerialNumber: 000001D91880
[185475.548770] usb 2-1.2: usb_probe_device
[185475.548773] usb 2-1.2: configuration #1 chosen from 1 choice
[185475.549117] usb 2-1.2: adding 2-1.2:1.0 (config #1, interface 0)
[185475.549399] usb-storage 2-1.2:1.0: usb_probe_interface
[185475.549405] usb-storage 2-1.2:1.0: usb_probe_interface – got id
[185475.550000] scsi10 : usb-storage 2-1.2:1.0
[185476.551237] scsi 10:0:0:0: Direct-Access WDC WD50 00BEVT-75A0RT0 PQ: 0 ANSI: 2 CCS
[185476.551678] sd 10:0:0:0: Attached scsi generic sg2 type 0
[185476.552069] sd 10:0:0:0: [sdb] 976773168 512-byte logical blocks: (500 GB/465 GiB)
[185476.552819] sd 10:0:0:0: [sdb] Write Protect is off
[185476.552824] sd 10:0:0:0: [sdb] Mode Sense: 28 00 00 00
[185476.553690] sd 10:0:0:0: [sdb] No Caching mode page present
[185476.553695] sd 10:0:0:0: [sdb] Assuming drive cache: write through
[185476.556210] sd 10:0:0:0: [sdb] No Caching mode page present
[185476.556213] sd 10:0:0:0: [sdb] Assuming drive cache: write through
[185478.233649] sdb: sdb1 sdb2 sdb3
[185478.236550] sd 10:0:0:0: [sdb] No Caching mode page present
[185478.236558] sd 10:0:0:0: [sdb] Assuming drive cache: write through
[185478.236565] sd 10:0:0:0: [sdb] Attached SCSI disk
[/bash]
Les lignes surlignés vous donnent les infos nécessaires (taille, et identification du disque)
On identifie la partition qui nous intéresse à l’aide de fdisk:
[bash highlight=”11,12″]
fdisk -l /dev/sdb
Disque /dev/sdb : 500.1 Go, 500107862016 octets, 976773168 secteurs
Unités = secteur de 1 × 512 = 512 octets
Taille de secteur (logique / physique) : 512 octets / 512 octets
taille d’E/S (minimale / optimale) : 512 octets / 512 octets
Identifiant de disque : 0x1c6264cf
Périphérique Amorce Début Fin Blocs Id Système
/dev/sdb1 63 80324 40131 de Dell Utility
/dev/sdb2 * 81920 30801919 15360000 7 HPFS/NTFS/exFAT
/dev/sdb3 30801920 976771119 472984600 7 HPFS/NTFS/exFAT
[/bash]
On a ici la partition de boot qui se trouve en /dev/sdb2 et sûrement une partition contenant les documents en /dev/sdb3.
On identifie le système de fichier sur la partition:
[bash]
blkid /dev/sdb2
/dev/sdb2: LABEL="RECOVERY" UUID="6AD2B230D2B1FFFD" TYPE="ntfs"
blkid /dev/sdb3
/dev/sdb3: LABEL="OS" UUID="E60AB6450AB61293" TYPE="ntfs"
[/bash]
2/ On utilise les smartmontools pour regarder la santé du disque:
[bash]
ulysse alex # smartctl -H /dev/sdb
smartctl 5.42 2011-10-20 r3458 [x86_64-linux-3.7.10-gentoo-r1] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
[/bash]
Si tout s’est bien passé, vous devriez voir le mot PASSED sur la dernière ligne.
Puis on se lance sur les tests plus longs:
[bash]
ulysse alex # smartctl -t long /dev/sdb
smartctl 5.42 2011-10-20 r3458 [x86_64-linux-3.7.10-gentoo-r1] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Extended self-test routine immediately in off-line mode".
Drive command "Execute SMART Extended self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 62 minutes for test to complete.
Test will complete after Sat May 11 19:34:33 2013
[/bash]
En enfin, une fois le test terminé (comptez environ un quart d’heure de plus pour être sûr), on lance la commande suivante pour obtenir les résultats:
[bash]
ulysse alex # smartctl -l selftest /dev/sdb
smartctl 5.42 2011-10-20 r3458 [x86_64-linux-3.7.10-gentoo-r1] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 5464 –
# 2 Short offline Completed without error 00% 5463 –
[/bash]
3/ on tente un montage en lecture seule pour être certain d’agir sur la bonne partition:
[bash]
mount -o ro -t ntfs /dev/sdb3 /mnt/usb
[/bash]
Ici, on n’a pas le soucis de montage du disque. Cela fonctionne. Le problème est que le disque contient pas mal de secteurs défectueux.
Une fois la partition identifiée, on démonte afin de commencer le traitement.
[bash]
umount /mnt/usb
[/bash]
On va avoir besoin d’un autre disque de bonne taille et formaté selon un système de fichier permettant de stocker de gros fichiers.
on monte donc le disque qui devra recevoir la copie de travail.
[bash]
mount /dev/sdc1 /mnt/rescue
[/bash]
Dans un premier temps, on peut essayer de déterminer si la partition concernée contient des secteurs défectueux (ceci en mode lecture seule):
[bash]
badblocks -v /dev/sdb3 > /mnt/rescue/bb_sdc.lst
Vérification des blocs 0 à 976761559
Vérification des blocs défectueux (test en mode lecture seule) : 0.05% effectué, 15:12 écoulé. (24/0/0 erreurs)
[/bash]
Cette opération prend pas mal de temps…
En fait, vous pouvez vous en passer au profit de la prochaine étape car ddrescue utilisé avec un fichier de log permet via ddrescuelog de transformer ce fichier de log en fichier au format badblock.
Puis, on va créer une image la plus fidèle possible de la partition contenant les données que l’on souhaite récupérer. Pour cela, on utilise ddrescue pour commencer la récupération puis ddrescuelog pour convertir les logs en liste badblock que l’on pourra utiliser ultérieurement dans la réparation du système de fichiers:
[bash]
ddrescue -r 3 /dev/sdb3 /mnt/rescue/sdb3.img /mnt/rescue/sdb3.log
ddrescuelog -l -b4096 /mnt/rescue/sdb3.log > /mnt/rescue/sdb3.badblocks
[/bash]
Cette opération peut prendre plusieurs heures, donc vous pouvez vous mettre sur autre chose en attendant. Si l’opération s’arrête sur une erreur,
vous pouvez toujours la relancer telle quelle. Le fichier de log assurera la suite et la récupération reprendra là où elle s’est arrêtée.
Après vous devez utiliser le logiciel de réparation adapté à votre système de fichier. Il sera disponible normalement sous la dénomination:
fsck.le_systeme_de_fichier, par expl:
fsck, fsck.ext4, fsck.jfs, fsck.reiserfs,
fsck.cramfs, fsck.ext4dev, fsck.minix, fsck.vfat,
fsck.ext2, fsck.hfs, fsck.msdos, fsck.xfs,
fsck.ext3, fsck.hfsplus, fsck.reiser4, fsck_hfs
Ces utilitaires vous permettrons de ré-utiliser le fichier liste des badblocks:
[bash]
fsck.MONFS -f -l /mnt/rescue/sdb3.badblocks /mnt/rescue/sdb3.img
[/bash]
(Vous devrez bien entendu remplacer MONFS par une des valeurs de la liste ci-dessus)
Ici, la page man de ces utilitaires vous donnera accès aux options spécifiques des systèmes de fichiers utilisés
Certains autres par contre seront des outils à part comme:
btrfsck ou ntfsck/ntfsfix
Dans le cas envisagé ici, on a:
[bash]
ntfsfix -b /mnt/rescue/sdb3.img
[/bash]
L’option -b permet de nettoyer les mauvais secteurs. Si le volume persiste à ne pas vouloir se monter, vous pouvez utiliser l’option -d de ntfsfix qui efface le drapeau “dirty” du volume.
Enfin après tout ceci, il nous reste à monter l’image en lecture seule:
[bash]
mount -o loop,ro -t ntfs /mnt/rescue/sdb3.img /mnt/cdrom
[/bash]
Et là, normalement, tout se trouvera dans le répertoire /mnt/cdrom.
Partie à réaliser:
* Récupération de fichiers effacés ou perdus
Ressources:
Friday, 25 January 2013
Installer une gentoo 64 bits sur un toshiba portege R830-137
Encore un billet bloc-note qui évoluera (manque la partie graphique à faire)
Caractéristiques de l’installation:
- Gentoo 64 bits
- UTF-8
- Btrfs
- Cryptage de la swap et des partitions
- Utilisation du lecteur d’empreintes digitales
- Fluxbox (A faire)
- Conky (A faire)
- Installation / Utilisation de toshset
Caractéristiques de la machine:
- Proc: Intel Corei7 – 2620M:
- Mémoire: 4 Go
- Disque dur SSD de 256 Go SATA
- 3G: F5521 21/5.76 HSPA
[bash]
uname -a
Linux ulysse 3.5.7-gentoo #1 SMP Wed Oct 31 03:12:52 CET 2012 x86_64 Intel(R) Core(TM) i7-2620M CPU @ 2.70GHz GenuineIntel GNU/Linux
lspci
00:00.0 Host bridge: Intel Corporation 2nd Generation Core Processor Family DRAM Controller (rev 09)
00:02.0 VGA compatible controller: Intel Corporation 2nd Generation Core Processor Family Integrated Graphics Controller (rev 09)
00:16.0 Communication controller: Intel Corporation 6 Series/C200 Series Chipset Family MEI Controller #1 (rev 04)
00:16.3 Serial controller: Intel Corporation 6 Series/C200 Series Chipset Family KT Controller (rev 04)
00:19.0 Ethernet controller: Intel Corporation 82579LM Gigabit Network Connection (rev 04)
00:1a.0 USB controller: Intel Corporation 6 Series/C200 Series Chipset Family USB Enhanced Host Controller #2 (rev 04)
00:1b.0 Audio device: Intel Corporation 6 Series/C200 Series Chipset Family High Definition Audio Controller (rev 04)
00:1c.0 PCI bridge: Intel Corporation 6 Series/C200 Series Chipset Family PCI Express Root Port 1 (rev b4)
00:1c.1 PCI bridge: Intel Corporation 6 Series/C200 Series Chipset Family PCI Express Root Port 2 (rev b4)
00:1c.2 PCI bridge: Intel Corporation 6 Series/C200 Series Chipset Family PCI Express Root Port 3 (rev b4)
00:1c.4 PCI bridge: Intel Corporation 6 Series/C200 Series Chipset Family PCI Express Root Port 5 (rev b4)
00:1c.5 PCI bridge: Intel Corporation 6 Series/C200 Series Chipset Family PCI Express Root Port 6 (rev b4)
00:1c.6 PCI bridge: Intel Corporation 82801 Mobile PCI Bridge (rev b4)
00:1d.0 USB controller: Intel Corporation 6 Series/C200 Series Chipset Family USB Enhanced Host Controller #1 (rev 04)
00:1f.0 ISA bridge: Intel Corporation QM67 Express Chipset Family LPC Controller (rev 04)
00:1f.2 SATA controller: Intel Corporation 6 Series/C200 Series Chipset Family 6 port SATA AHCI Controller (rev 04)
01:00.0 System peripheral: Ricoh Co Ltd PCIe SDXC/MMC Host Controller (rev 04)
04:00.0 Network controller: Intel Corporation Centrino Advanced-N 6230 (rev 34)
05:00.0 USB controller: NEC Corporation uPD720200 USB 3.0 Host Controller (rev 04)
lsusb
Bus 001 Device 002: ID 8087:0024 Intel Corp. Integrated Rate Matching Hub
Bus 002 Device 002: ID 8087:0024 Intel Corp. Integrated Rate Matching Hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 004 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 003: ID 08ff:168b AuthenTec, Inc.
Bus 001 Device 005: ID 0bda:58e5 Realtek Semiconductor Corp.
Bus 001 Device 006: ID 0930:1314 Toshiba Corp.
Bus 002 Device 004: ID 8086:0189 Intel Corp.
[/bash]
L’accès au BIOS se fait en pressant la touche F2 au démarrage.
Préambule:
- Création des dvd de restauration
- Enregistrer vos empreintes digitales (Pour le contrôle lors du lancement de la machine)
Une fois tout ceci fini, on va pouvoir se concentrer sur l’installation. Pour ceci, on va suivre un schéma d’action
très général qui correspond peu ou prou aux installations habituelles:
- On boot la machine grâce à un livecd contenant les outils nécessaires aux opérations de base: partitionnement, formatage, cryptage, etc. On peut aussi se servir d’une image réseau. Bref on démarre la machine avec une trousse à outils adéquate
- La machine boot et le système s’installe dans la mémoire. On va pouvoir travailler sur le disque. On le partitionne et on formate les partitions avec le système de fichier choisit
- On va monter le partitions sur la racine du système actuel qui se trouve être en mémoire.
- On va activer la swap, binder le répertoire /dev contenant les références aux périphériques et monter le répertoire /proc
- A ce moment, on dispose d’un support disque bien en place. On va y installer une archives contenant les outils de base de gentoo (la toolchain, les outils systèmes, le shell, les outils permettant de gérer la distribution, etc) ainsi qu’une archive contenant l’arbre portage. On fait ça en récupérant un tarball directement sur le site de gentoo.
- Ceci fait, notre arborescence est complète sur le disque et l’on a pas mal d’outils pour continuer: on va se chrooter dans la nouvelle arborescence.
- Il ne nous reste plus qu’à paramétrer notre système (table des partitions, configuration réseau), compiler le noyau, installer du bootloader et encore quelques outils comme la journalisation, cron, etc.
- Enfin, on sort du chroot, on démonte toutes les partitions et on reboot. Voilà c’est fait !
Une fois le boot terminé et que l’on a accès à la console, on va configurer
quelques trucs:
* La langue
[bash]
loadkeys fr
[/bash]
* L’accès au réseau (eth0)
[bash]
dhcpcd eth0
[/bash]
Préparation du disque
On efface complètement le disque dur (Peut prendre du temps selon la taille du hd)
[bash]
shred -n 7 /dev/sda
[/bash]
On partitionne:
fidsk /dev/sda #on commence à 2048
/boot ext2 32M
swap 8G
/ le reste (dispo pour lvm+ext4 ou btrfs)
On formate /boot
[bash]
mke2fs /dev/sda1
[/bash]
On crypte la swap
[bash]
cryptsetup -c blowfish -h sha256 -d /dev/urandom create swap /dev/sda2
mkswap /dev/mapper/swap
swapon /dev/mapper/swap
[/bash]
On monte la clé USB
On va y générer une clé aléatoire, on crypte la partition avec, puis on active la partition cryptée
[bash]
mount /dev/sdb1 /mnt/key
dd if=/dev/random count=1 of=/mnt/key/root_key
cryptsetup -v –cipher serpent-cbc-essiv:sha256 –key-size 256 luksFormat /dev/sda3 /mnt/key/root_key
cryptsetup –key-file /mnt/key/root_key luksOpen /dev/sda3 root
[/bash]
On peut rajouter un mot de passe en cas de perte de la clé:
[bash]
cryptsetup luksAddKey /dev/sda3 –key-file /mnt/usb/root_key
[/bash]
Formatage / Organisation du disque
Alternative 1 (lvm + ext4)
On va créé les volumes et tout le reste pour LVM2
[bash]
pvcreate –dataalignment 512k /dev/mapper/root
vgcreate –physicalextentsize 512k vg_ssd /dev/mapper/root
lvcreate -L10G -nroot vg_ssd
lvcreate -L10G -nusr vg_ssd
lvcreate -L30G -nhome vg_ssd
lvcreate -L4G -nvar vg_ssd
[/bash]
Puis, on formate en ext4. (classique)
Alternative 2 (Btrfs)
Pour ceci, si vous n’avez pas les binaires dans le livecd, vous récupérez
les sources puis vous compilez en static (make LDFLAGS=-all-static)
Vous mettez tout ça sur une clé usb puis direction la machine à formater.
On formate et on monte:
[bash]
mkfs.btrfs -L GENTOO_ROOT /dev/mapper/root
mkdir /mnt/btrfs
mount -t btrfs -o compress,compress-force,ssd,noacl /dev/mapper/root /mnt/btrfs
btrfsctl -S system /mnt/btrfs
btrfsctl -S var /mnt/btrfs
btrfsctl -S usr /mnt/btrfs
btrfsctl -S home /mnt/btrfs
umount /mnt/btrfs
mount /dev/mapper/root -o subvol=system,compress,ssd /mnt/gentoo
mkdir /mnt/gentoo/{usr,var,home,boot}
mount /dev/mapper/root -o subvol=usr,compress,ssd /mnt/gentoo/usr
mount /dev/mapper/root -o subvol=var,compress,ssd /mnt/gentoo/var
mount /dev/mapper/root -o subvol=home,compress,ssd /mnt/gentoo/home
mount /dev/sda1 /mnt/gentoo/boot
[/bash]
Portage et autres trucs du manuel
Ici on suit le manuel d’installation avec ce fichier /etc/portage/make.conf dans le chroot.
[bash]
CFLAGS="-O2 -march=corei7 -pipe"
CXXFLAGS="${CFLAGS}"
CHOST="x86_64-pc-linux-gnu"
USE="mmx sse sse2 sse3 ssse3 mmx X -kde -gnome alsa dvd cdr dvdr gnutls ldap gcrypt
acpi bash-completion vim-syntax unicode jpeg tiff udev xinerama startup-notification
djvu png qt4 curl nsplugin xml libnotify truetype usb v4l v4l2 python perl xft opengl
urandom vaapi pulseaudio caps tcpd udev glib libsamplerate"
MAKEOPTS="-j5 -l4"
LINGUAS="fr"
VIDEO_CARDS="intel"
DISTDIR="/var/portage/distfiles"
INPUT_DEVICES="evdev keyboard mouse wacom synaptics"
KBUILD_OUTPUT="/mnt/work"
source /var/lib/layman/make.conf
[/bash]
* On peut ré-utiliser les binaires statics de btrfs pour la génération de l’initram
Comme on est sur un ssd, on va compiler sur un disque mémoire tmpfs qui sera monté sur /var/tmp/portage. De même
on va monter l’arbre portage sur une image squashfs.
[bash]
mount -t tmpfs -o size=2G tmpfs /usr/portage
mount -t tmpfs -o size=2G tmpfs /var/tmp/portage (utilisé pour les compilations)
emerge-webrsync
mkdir -p /var/portage/distfiles
mksquashfs /usr/portage /var/portage/portage.sqsh (créé l’archive squashfs que l’on montera à chaque démarrage)
[/bash]
* On se localise en utf8
on va créer le fichier /etc/env.d/02locale et y placer:
[bash]
LANG="fr_FR.UTF-8"
LC_COLLATE="C"
[/bash]
Initram
[bash]
USE="static" emerge -D busybox
mkdir /usr/src/initramfs
cd /usr/src/initramfs
mkdir -p bin lib dev etc mnt/root mnt/key proc root sbin sys
cp -a /dev/{console,null,random,sda1,tty,urandom} ./dev/
cp -a /bin/busybox /usr/src/initramfs/bin/
cp -a /sbin/cryptsetup /usr/src/initramfs/bin/
On va y ajouter un fichier init à la racine
nano /usr/src/initramfs/init
[/bash]
Contenu du fichier init:
[bash]
#!/bin/busybox sh
mount -t proc none /proc
mount -t sysfs none /sys
mount -t devtmpfs none /dev
sleep 3
mount /dev/sdb2 /mnt/key
cryptsetup –key-file /mnt/key/root_key luksOpen /dev/sda2 swap &&
cryptsetup –key-file /mnt/key/root_key luksOpen /dev/sda3 root &&
mount -t btrfs -o ro,subvol=system,ssd,compress /dev/mapper/root /mnt/root
umount /{mnt/key,proc,sys,dev}
exec switch_root /mnt/root /sbin/init
[/bash]
[bash]
chmod +x /usr/src/initramfs/init
find . -print0 | cpio –null -ov –format=newc | gzip -9 > /boot/initramfs.cpio.gz
[/bash]
Le noyau
Pour ça, on va recréé un système de fichier tmpfs et on va compiler dessus
[bash]
emerge gentoo-sources
mkdir /mnt/work
mount -t tmps -o size=2G tmpfs /mnt/work
cd /usr/src/linux
make O=/mnt/work menuconfig #Ici on n’oublie pas l’option du support de initramfs
make O=/mnt/work
make O=/mnt/work modules_install
cp /mnt/work/{System.map,arch/x86/boot/bzImage} /boot/
[/bash]
Et hop, le noyau est installé
Le fichier de conf du noyau (version 3.7):
[bash collapse=”true”]
CONFIG_64BIT=y
CONFIG_X86_64=y
CONFIG_X86=y
CONFIG_INSTRUCTION_DECODER=y
CONFIG_OUTPUT_FORMAT="elf64-x86-64"
CONFIG_ARCH_DEFCONFIG="arch/x86/configs/x86_64_defconfig"
CONFIG_LOCKDEP_SUPPORT=y
CONFIG_STACKTRACE_SUPPORT=y
CONFIG_HAVE_LATENCYTOP_SUPPORT=y
CONFIG_MMU=y
CONFIG_NEED_DMA_MAP_STATE=y
CONFIG_NEED_SG_DMA_LENGTH=y
CONFIG_GENERIC_ISA_DMA=y
CONFIG_GENERIC_BUG=y
CONFIG_GENERIC_BUG_RELATIVE_POINTERS=y
CONFIG_GENERIC_HWEIGHT=y
CONFIG_GENERIC_GPIO=y
CONFIG_ARCH_MAY_HAVE_PC_FDC=y
CONFIG_RWSEM_XCHGADD_ALGORITHM=y
CONFIG_GENERIC_CALIBRATE_DELAY=y
CONFIG_ARCH_HAS_CPU_RELAX=y
CONFIG_ARCH_HAS_DEFAULT_IDLE=y
CONFIG_ARCH_HAS_CACHE_LINE_SIZE=y
CONFIG_ARCH_HAS_CPU_AUTOPROBE=y
CONFIG_HAVE_SETUP_PER_CPU_AREA=y
CONFIG_NEED_PER_CPU_EMBED_FIRST_CHUNK=y
CONFIG_NEED_PER_CPU_PAGE_FIRST_CHUNK=y
CONFIG_ARCH_HIBERNATION_POSSIBLE=y
CONFIG_ARCH_SUSPEND_POSSIBLE=y
CONFIG_ZONE_DMA32=y
CONFIG_AUDIT_ARCH=y
CONFIG_ARCH_SUPPORTS_OPTIMIZED_INLINING=y
CONFIG_ARCH_SUPPORTS_DEBUG_PAGEALLOC=y
CONFIG_X86_64_SMP=y
CONFIG_X86_HT=y
CONFIG_ARCH_HWEIGHT_CFLAGS="-fcall-saved-rdi -fcall-saved-rsi -fcall-saved-rdx -fcall-saved-rcx -fcall-saved-r8 -fcall-saved-r9 -fcall-saved-r10 -fcall-saved-r11"
CONFIG_ARCH_CPU_PROBE_RELEASE=y
CONFIG_ARCH_SUPPORTS_UPROBES=y
CONFIG_DEFCONFIG_LIST="/lib/modules/$UNAME_RELEASE/.config"
CONFIG_HAVE_IRQ_WORK=y
CONFIG_IRQ_WORK=y
CONFIG_BUILDTIME_EXTABLE_SORT=y
CONFIG_EXPERIMENTAL=y
CONFIG_INIT_ENV_ARG_LIMIT=32
CONFIG_CROSS_COMPILE=""
CONFIG_LOCALVERSION=""
CONFIG_HAVE_KERNEL_GZIP=y
CONFIG_HAVE_KERNEL_BZIP2=y
CONFIG_HAVE_KERNEL_LZMA=y
CONFIG_HAVE_KERNEL_XZ=y
CONFIG_HAVE_KERNEL_LZO=y
CONFIG_KERNEL_GZIP=y
CONFIG_DEFAULT_HOSTNAME="dervishe.net"
CONFIG_SWAP=y
CONFIG_SYSVIPC=y
CONFIG_SYSVIPC_SYSCTL=y
CONFIG_POSIX_MQUEUE=y
CONFIG_POSIX_MQUEUE_SYSCTL=y
CONFIG_BSD_PROCESS_ACCT=y
CONFIG_TASKSTATS=y
CONFIG_TASK_DELAY_ACCT=y
CONFIG_TASK_XACCT=y
CONFIG_TASK_IO_ACCOUNTING=y
CONFIG_AUDIT=y
CONFIG_AUDITSYSCALL=y
CONFIG_AUDIT_WATCH=y
CONFIG_AUDIT_TREE=y
CONFIG_HAVE_GENERIC_HARDIRQS=y
CONFIG_GENERIC_HARDIRQS=y
CONFIG_GENERIC_IRQ_PROBE=y
CONFIG_GENERIC_IRQ_SHOW=y
CONFIG_GENERIC_PENDING_IRQ=y
CONFIG_IRQ_FORCED_THREADING=y
CONFIG_SPARSE_IRQ=y
CONFIG_CLOCKSOURCE_WATCHDOG=y
CONFIG_ARCH_CLOCKSOURCE_DATA=y
CONFIG_GENERIC_TIME_VSYSCALL=y
CONFIG_GENERIC_CLOCKEVENTS=y
CONFIG_GENERIC_CLOCKEVENTS_BUILD=y
CONFIG_GENERIC_CLOCKEVENTS_BROADCAST=y
CONFIG_GENERIC_CLOCKEVENTS_MIN_ADJUST=y
CONFIG_GENERIC_CMOS_UPDATE=y
CONFIG_TICK_ONESHOT=y
CONFIG_NO_HZ=y
CONFIG_HIGH_RES_TIMERS=y
CONFIG_TREE_RCU=y
CONFIG_RCU_FANOUT=64
CONFIG_RCU_FANOUT_LEAF=16
CONFIG_IKCONFIG=m
CONFIG_IKCONFIG_PROC=y
CONFIG_LOG_BUF_SHIFT=18
CONFIG_HAVE_UNSTABLE_SCHED_CLOCK=y
CONFIG_CGROUPS=y
CONFIG_CGROUP_FREEZER=y
CONFIG_CPUSETS=y
CONFIG_PROC_PID_CPUSET=y
CONFIG_CGROUP_CPUACCT=y
CONFIG_RESOURCE_COUNTERS=y
CONFIG_CGROUP_SCHED=y
CONFIG_FAIR_GROUP_SCHED=y
CONFIG_CHECKPOINT_RESTORE=y
CONFIG_SYSFS_DEPRECATED=y
CONFIG_SYSFS_DEPRECATED_V2=y
CONFIG_RELAY=y
CONFIG_BLK_DEV_INITRD=y
CONFIG_INITRAMFS_SOURCE=""
CONFIG_RD_GZIP=y
CONFIG_SYSCTL=y
CONFIG_ANON_INODES=y
CONFIG_EXPERT=y
CONFIG_UID16=y
CONFIG_SYSCTL_SYSCALL=y
CONFIG_KALLSYMS=y
CONFIG_HOTPLUG=y
CONFIG_PRINTK=y
CONFIG_BUG=y
CONFIG_ELF_CORE=y
CONFIG_PCSPKR_PLATFORM=y
CONFIG_HAVE_PCSPKR_PLATFORM=y
CONFIG_BASE_FULL=y
CONFIG_FUTEX=y
CONFIG_EPOLL=y
CONFIG_SIGNALFD=y
CONFIG_TIMERFD=y
CONFIG_EVENTFD=y
CONFIG_SHMEM=y
CONFIG_AIO=y
CONFIG_HAVE_PERF_EVENTS=y
CONFIG_PERF_EVENTS=y
CONFIG_VM_EVENT_COUNTERS=y
CONFIG_PCI_QUIRKS=y
CONFIG_SLUB_DEBUG=y
CONFIG_SLUB=y
CONFIG_PROFILING=y
CONFIG_TRACEPOINTS=y
CONFIG_HAVE_OPROFILE=y
CONFIG_OPROFILE_NMI_TIMER=y
CONFIG_KPROBES=y
CONFIG_OPTPROBES=y
CONFIG_HAVE_EFFICIENT_UNALIGNED_ACCESS=y
CONFIG_KRETPROBES=y
CONFIG_USER_RETURN_NOTIFIER=y
CONFIG_HAVE_IOREMAP_PROT=y
CONFIG_HAVE_KPROBES=y
CONFIG_HAVE_KRETPROBES=y
CONFIG_HAVE_OPTPROBES=y
CONFIG_HAVE_ARCH_TRACEHOOK=y
CONFIG_HAVE_DMA_ATTRS=y
CONFIG_USE_GENERIC_SMP_HELPERS=y
CONFIG_GENERIC_SMP_IDLE_THREAD=y
CONFIG_HAVE_REGS_AND_STACK_ACCESS_API=y
CONFIG_HAVE_DMA_API_DEBUG=y
CONFIG_HAVE_HW_BREAKPOINT=y
CONFIG_HAVE_MIXED_BREAKPOINTS_REGS=y
CONFIG_HAVE_USER_RETURN_NOTIFIER=y
CONFIG_HAVE_PERF_EVENTS_NMI=y
CONFIG_HAVE_ARCH_JUMP_LABEL=y
CONFIG_ARCH_HAVE_NMI_SAFE_CMPXCHG=y
CONFIG_HAVE_ALIGNED_STRUCT_PAGE=y
CONFIG_HAVE_CMPXCHG_LOCAL=y
CONFIG_HAVE_CMPXCHG_DOUBLE=y
CONFIG_ARCH_WANT_OLD_COMPAT_IPC=y
CONFIG_HAVE_ARCH_SECCOMP_FILTER=y
CONFIG_SECCOMP_FILTER=y
CONFIG_SLABINFO=y
CONFIG_RT_MUTEXES=y
CONFIG_BASE_SMALL=0
CONFIG_MODULES=y
CONFIG_MODULE_UNLOAD=y
CONFIG_MODULE_FORCE_UNLOAD=y
CONFIG_STOP_MACHINE=y
CONFIG_BLOCK=y
CONFIG_BLK_DEV_BSG=y
CONFIG_PARTITION_ADVANCED=y
CONFIG_OSF_PARTITION=y
CONFIG_AMIGA_PARTITION=y
CONFIG_MAC_PARTITION=y
CONFIG_MSDOS_PARTITION=y
CONFIG_BSD_DISKLABEL=y
CONFIG_MINIX_SUBPARTITION=y
CONFIG_SOLARIS_X86_PARTITION=y
CONFIG_UNIXWARE_DISKLABEL=y
CONFIG_SGI_PARTITION=y
CONFIG_SUN_PARTITION=y
CONFIG_KARMA_PARTITION=y
CONFIG_EFI_PARTITION=y
CONFIG_BLOCK_COMPAT=y
CONFIG_IOSCHED_NOOP=y
CONFIG_IOSCHED_DEADLINE=y
CONFIG_IOSCHED_CFQ=y
CONFIG_DEFAULT_CFQ=y
CONFIG_DEFAULT_IOSCHED="cfq"
CONFIG_PREEMPT_NOTIFIERS=y
CONFIG_PADATA=y
CONFIG_INLINE_SPIN_UNLOCK_IRQ=y
CONFIG_INLINE_READ_UNLOCK=y
CONFIG_INLINE_READ_UNLOCK_IRQ=y
CONFIG_INLINE_WRITE_UNLOCK=y
CONFIG_INLINE_WRITE_UNLOCK_IRQ=y
CONFIG_MUTEX_SPIN_ON_OWNER=y
CONFIG_FREEZER=y
CONFIG_ZONE_DMA=y
CONFIG_SMP=y
CONFIG_X86_MPPARSE=y
CONFIG_X86_EXTENDED_PLATFORM=y
CONFIG_X86_SUPPORTS_MEMORY_FAILURE=y
CONFIG_SCHED_OMIT_FRAME_POINTER=y
CONFIG_NO_BOOTMEM=y
CONFIG_MEMTEST=y
CONFIG_MCORE2=y
CONFIG_X86_INTERNODE_CACHE_SHIFT=6
CONFIG_X86_CMPXCHG=y
CONFIG_X86_L1_CACHE_SHIFT=6
CONFIG_X86_XADD=y
CONFIG_X86_WP_WORKS_OK=y
CONFIG_X86_INTEL_USERCOPY=y
CONFIG_X86_USE_PPRO_CHECKSUM=y
CONFIG_X86_P6_NOP=y
CONFIG_X86_TSC=y
CONFIG_X86_CMPXCHG64=y
CONFIG_X86_CMOV=y
CONFIG_X86_MINIMUM_CPU_FAMILY=64
CONFIG_X86_DEBUGCTLMSR=y
CONFIG_PROCESSOR_SELECT=y
CONFIG_CPU_SUP_INTEL=y
CONFIG_HPET_TIMER=y
CONFIG_HPET_EMULATE_RTC=y
CONFIG_DMI=y
CONFIG_SWIOTLB=y
CONFIG_IOMMU_HELPER=y
CONFIG_NR_CPUS=64
CONFIG_SCHED_SMT=y
CONFIG_SCHED_MC=y
CONFIG_PREEMPT_VOLUNTARY=y
CONFIG_X86_LOCAL_APIC=y
CONFIG_X86_IO_APIC=y
CONFIG_X86_REROUTE_FOR_BROKEN_BOOT_IRQS=y
CONFIG_X86_MCE=y
CONFIG_X86_MCE_INTEL=y
CONFIG_X86_MCE_THRESHOLD=y
CONFIG_X86_THERMAL_VECTOR=y
CONFIG_MICROCODE=y
CONFIG_MICROCODE_INTEL=y
CONFIG_MICROCODE_OLD_INTERFACE=y
CONFIG_X86_MSR=y
CONFIG_X86_CPUID=y
CONFIG_ARCH_PHYS_ADDR_T_64BIT=y
CONFIG_ARCH_DMA_ADDR_T_64BIT=y
CONFIG_DIRECT_GBPAGES=y
CONFIG_NUMA=y
CONFIG_X86_64_ACPI_NUMA=y
CONFIG_NODES_SPAN_OTHER_NODES=y
CONFIG_NODES_SHIFT=6
CONFIG_ARCH_SPARSEMEM_ENABLE=y
CONFIG_ARCH_SPARSEMEM_DEFAULT=y
CONFIG_ARCH_SELECT_MEMORY_MODEL=y
CONFIG_ARCH_PROC_KCORE_TEXT=y
CONFIG_ILLEGAL_POINTER_VALUE=0xdead000000000000
CONFIG_SELECT_MEMORY_MODEL=y
CONFIG_SPARSEMEM_MANUAL=y
CONFIG_SPARSEMEM=y
CONFIG_NEED_MULTIPLE_NODES=y
CONFIG_HAVE_MEMORY_PRESENT=y
CONFIG_SPARSEMEM_EXTREME=y
CONFIG_SPARSEMEM_VMEMMAP_ENABLE=y
CONFIG_SPARSEMEM_ALLOC_MEM_MAP_TOGETHER=y
CONFIG_SPARSEMEM_VMEMMAP=y
CONFIG_HAVE_MEMBLOCK=y
CONFIG_HAVE_MEMBLOCK_NODE_MAP=y
CONFIG_ARCH_DISCARD_MEMBLOCK=y
CONFIG_PAGEFLAGS_EXTENDED=y
CONFIG_SPLIT_PTLOCK_CPUS=4
CONFIG_COMPACTION=y
CONFIG_MIGRATION=y
CONFIG_PHYS_ADDR_T_64BIT=y
CONFIG_ZONE_DMA_FLAG=1
CONFIG_BOUNCE=y
CONFIG_VIRT_TO_BUS=y
CONFIG_MMU_NOTIFIER=y
CONFIG_KSM=y
CONFIG_DEFAULT_MMAP_MIN_ADDR=4096
CONFIG_ARCH_SUPPORTS_MEMORY_FAILURE=y
CONFIG_TRANSPARENT_HUGEPAGE=y
CONFIG_TRANSPARENT_HUGEPAGE_MADVISE=y
CONFIG_CROSS_MEMORY_ATTACH=y
CONFIG_CLEANCACHE=y
CONFIG_X86_CHECK_BIOS_CORRUPTION=y
CONFIG_X86_BOOTPARAM_MEMORY_CORRUPTION_CHECK=y
CONFIG_X86_RESERVE_LOW=64
CONFIG_MTRR=y
CONFIG_MTRR_SANITIZER=y
CONFIG_MTRR_SANITIZER_ENABLE_DEFAULT=0
CONFIG_MTRR_SANITIZER_SPARE_REG_NR_DEFAULT=1
CONFIG_X86_PAT=y
CONFIG_ARCH_USES_PG_UNCACHED=y
CONFIG_ARCH_RANDOM=y
CONFIG_EFI=y
CONFIG_SECCOMP=y
CONFIG_CC_STACKPROTECTOR=y
CONFIG_HZ_1000=y
CONFIG_HZ=1000
CONFIG_SCHED_HRTICK=y
CONFIG_KEXEC=y
CONFIG_CRASH_DUMP=y
CONFIG_PHYSICAL_START=0x1000000
CONFIG_RELOCATABLE=y
CONFIG_PHYSICAL_ALIGN=0x1000000
CONFIG_HOTPLUG_CPU=y
CONFIG_ARCH_ENABLE_MEMORY_HOTPLUG=y
CONFIG_USE_PERCPU_NUMA_NODE_ID=y
CONFIG_ARCH_HIBERNATION_HEADER=y
CONFIG_SUSPEND=y
CONFIG_SUSPEND_FREEZER=y
CONFIG_HIBERNATE_CALLBACKS=y
CONFIG_HIBERNATION=y
CONFIG_PM_STD_PARTITION="/dev/mapper/swap"
CONFIG_PM_SLEEP=y
CONFIG_PM_SLEEP_SMP=y
CONFIG_PM_RUNTIME=y
CONFIG_PM=y
CONFIG_PM_DEBUG=y
CONFIG_PM_ADVANCED_DEBUG=y
CONFIG_CAN_PM_TRACE=y
CONFIG_ACPI=y
CONFIG_ACPI_SLEEP=y
CONFIG_ACPI_PROCFS=y
CONFIG_ACPI_PROCFS_POWER=y
CONFIG_ACPI_PROC_EVENT=y
CONFIG_ACPI_AC=m
CONFIG_ACPI_BATTERY=m
CONFIG_ACPI_BUTTON=y
CONFIG_ACPI_VIDEO=y
CONFIG_ACPI_FAN=m
CONFIG_ACPI_DOCK=y
CONFIG_ACPI_PROCESSOR=m
CONFIG_ACPI_HOTPLUG_CPU=y
CONFIG_ACPI_PROCESSOR_AGGREGATOR=m
CONFIG_ACPI_THERMAL=m
CONFIG_ACPI_NUMA=y
CONFIG_ACPI_BLACKLIST_YEAR=0
CONFIG_ACPI_PCI_SLOT=m
CONFIG_X86_PM_TIMER=y
CONFIG_ACPI_CONTAINER=m
CONFIG_ACPI_SBS=m
CONFIG_ACPI_HED=y
CONFIG_ACPI_CUSTOM_METHOD=m
CONFIG_ACPI_BGRT=m
CONFIG_ACPI_APEI=y
CONFIG_ACPI_APEI_GHES=y
CONFIG_ACPI_APEI_PCIEAER=y
CONFIG_ACPI_APEI_EINJ=m
CONFIG_ACPI_APEI_ERST_DEBUG=m
CONFIG_CPU_FREQ=y
CONFIG_CPU_FREQ_TABLE=y
CONFIG_CPU_FREQ_STAT=m
CONFIG_CPU_FREQ_STAT_DETAILS=y
CONFIG_CPU_FREQ_DEFAULT_GOV_ONDEMAND=y
CONFIG_CPU_FREQ_GOV_PERFORMANCE=y
CONFIG_CPU_FREQ_GOV_POWERSAVE=m
CONFIG_CPU_FREQ_GOV_USERSPACE=m
CONFIG_CPU_FREQ_GOV_ONDEMAND=y
CONFIG_CPU_FREQ_GOV_CONSERVATIVE=m
CONFIG_X86_PCC_CPUFREQ=m
CONFIG_X86_ACPI_CPUFREQ=m
CONFIG_CPU_IDLE=y
CONFIG_CPU_IDLE_GOV_LADDER=y
CONFIG_CPU_IDLE_GOV_MENU=y
CONFIG_INTEL_IDLE=y
CONFIG_PCI=y
CONFIG_PCI_DIRECT=y
CONFIG_PCI_MMCONFIG=y
CONFIG_PCI_DOMAINS=y
CONFIG_PCIEPORTBUS=y
CONFIG_PCIEAER=y
CONFIG_PCIE_ECRC=y
CONFIG_PCIEASPM=y
CONFIG_PCIEASPM_DEBUG=y
CONFIG_PCIEASPM_POWERSAVE=y
CONFIG_PCIE_PME=y
CONFIG_ARCH_SUPPORTS_MSI=y
CONFIG_HT_IRQ=y
CONFIG_PCI_IOAPIC=y
CONFIG_PCI_LABEL=y
CONFIG_ISA_DMA_API=y
CONFIG_BINFMT_ELF=y
CONFIG_COMPAT_BINFMT_ELF=y
CONFIG_ARCH_BINFMT_ELF_RANDOMIZE_PIE=y
CONFIG_CORE_DUMP_DEFAULT_ELF_HEADERS=y
CONFIG_BINFMT_MISC=y
CONFIG_IA32_EMULATION=y
CONFIG_COMPAT=y
CONFIG_COMPAT_FOR_U64_ALIGNMENT=y
CONFIG_SYSVIPC_COMPAT=y
CONFIG_KEYS_COMPAT=y
CONFIG_HAVE_TEXT_POKE_SMP=y
CONFIG_X86_DEV_DMA_OPS=y
CONFIG_NET=y
CONFIG_PACKET=m
CONFIG_UNIX=m
CONFIG_UNIX_DIAG=m
CONFIG_XFRM=y
CONFIG_XFRM_ALGO=m
CONFIG_XFRM_USER=m
CONFIG_NET_KEY=m
CONFIG_INET=y
CONFIG_IP_MULTICAST=y
CONFIG_IP_ADVANCED_ROUTER=y
CONFIG_IP_MULTIPLE_TABLES=y
CONFIG_IP_ROUTE_MULTIPATH=y
CONFIG_IP_ROUTE_VERBOSE=y
CONFIG_IP_ROUTE_CLASSID=y
CONFIG_IP_PNP=y
CONFIG_IP_PNP_DHCP=y
CONFIG_IP_PNP_BOOTP=y
CONFIG_IP_PNP_RARP=y
CONFIG_NET_IPIP=m
CONFIG_NET_IPGRE_DEMUX=m
CONFIG_NET_IPGRE=m
CONFIG_NET_IPGRE_BROADCAST=y
CONFIG_IP_MROUTE=y
CONFIG_IP_PIMSM_V1=y
CONFIG_IP_PIMSM_V2=y
CONFIG_SYN_COOKIES=y
CONFIG_INET_TUNNEL=m
CONFIG_INET_LRO=m
CONFIG_INET_DIAG=m
CONFIG_INET_TCP_DIAG=m
CONFIG_INET_UDP_DIAG=m
CONFIG_TCP_CONG_ADVANCED=y
CONFIG_TCP_CONG_CUBIC=y
CONFIG_DEFAULT_CUBIC=y
CONFIG_DEFAULT_TCP_CONG="cubic"
CONFIG_TCP_MD5SIG=y
CONFIG_IPV6=m
CONFIG_IPV6_PRIVACY=y
CONFIG_IPV6_ROUTER_PREF=y
CONFIG_IPV6_ROUTE_INFO=y
CONFIG_INET6_AH=m
CONFIG_INET6_ESP=m
CONFIG_INET6_TUNNEL=m
CONFIG_INET6_XFRM_MODE_TRANSPORT=m
CONFIG_INET6_XFRM_MODE_TUNNEL=m
CONFIG_INET6_XFRM_MODE_BEET=m
CONFIG_IPV6_SIT=m
CONFIG_IPV6_NDISC_NODETYPE=y
CONFIG_IPV6_TUNNEL=m
CONFIG_IPV6_MULTIPLE_TABLES=y
CONFIG_IPV6_SUBTREES=y
CONFIG_IPV6_MROUTE=y
CONFIG_IPV6_MROUTE_MULTIPLE_TABLES=y
CONFIG_IPV6_PIMSM_V2=y
CONFIG_NETLABEL=y
CONFIG_NETWORK_SECMARK=y
CONFIG_NETFILTER=y
CONFIG_NETFILTER_ADVANCED=y
CONFIG_BRIDGE_NETFILTER=y
CONFIG_NETFILTER_NETLINK=y
CONFIG_NETFILTER_NETLINK_ACCT=m
CONFIG_NETFILTER_NETLINK_QUEUE=m
CONFIG_NETFILTER_NETLINK_LOG=y
CONFIG_NF_CONNTRACK=m
CONFIG_NF_CONNTRACK_MARK=y
CONFIG_NF_CONNTRACK_SECMARK=y
CONFIG_NF_CONNTRACK_ZONES=y
CONFIG_NF_CONNTRACK_PROCFS=y
CONFIG_NF_CONNTRACK_EVENTS=y
CONFIG_NF_CONNTRACK_TIMESTAMP=y
CONFIG_NF_CT_PROTO_DCCP=m
CONFIG_NF_CT_PROTO_GRE=m
CONFIG_NF_CT_PROTO_SCTP=m
CONFIG_NF_CT_PROTO_UDPLITE=m
CONFIG_NF_CONNTRACK_AMANDA=m
CONFIG_NF_CONNTRACK_FTP=m
CONFIG_NF_CONNTRACK_H323=m
CONFIG_NF_CONNTRACK_IRC=m
CONFIG_NF_CONNTRACK_BROADCAST=m
CONFIG_NF_CONNTRACK_NETBIOS_NS=m
CONFIG_NF_CONNTRACK_SNMP=m
CONFIG_NF_CONNTRACK_PPTP=m
CONFIG_NF_CONNTRACK_SANE=m
CONFIG_NF_CONNTRACK_SIP=m
CONFIG_NF_CONNTRACK_TFTP=m
CONFIG_NF_CT_NETLINK=m
CONFIG_NETFILTER_TPROXY=m
CONFIG_NETFILTER_XTABLES=y
CONFIG_NETFILTER_XT_MARK=m
CONFIG_NETFILTER_XT_CONNMARK=m
CONFIG_NETFILTER_XT_TARGET_AUDIT=m
CONFIG_NETFILTER_XT_TARGET_CHECKSUM=m
CONFIG_NETFILTER_XT_TARGET_CLASSIFY=m
CONFIG_NETFILTER_XT_TARGET_CONNMARK=m
CONFIG_NETFILTER_XT_TARGET_CONNSECMARK=m
CONFIG_NETFILTER_XT_TARGET_CT=m
CONFIG_NETFILTER_XT_TARGET_DSCP=m
CONFIG_NETFILTER_XT_TARGET_HL=m
CONFIG_NETFILTER_XT_TARGET_IDLETIMER=m
CONFIG_NETFILTER_XT_TARGET_LED=m
CONFIG_NETFILTER_XT_TARGET_LOG=m
CONFIG_NETFILTER_XT_TARGET_MARK=m
CONFIG_NETFILTER_XT_TARGET_NFLOG=m
CONFIG_NETFILTER_XT_TARGET_NFQUEUE=m
CONFIG_NETFILTER_XT_TARGET_NOTRACK=m
CONFIG_NETFILTER_XT_TARGET_RATEEST=m
CONFIG_NETFILTER_XT_TARGET_TEE=m
CONFIG_NETFILTER_XT_TARGET_TPROXY=m
CONFIG_NETFILTER_XT_TARGET_TRACE=m
CONFIG_NETFILTER_XT_TARGET_SECMARK=m
CONFIG_NETFILTER_XT_TARGET_TCPMSS=m
CONFIG_NETFILTER_XT_TARGET_TCPOPTSTRIP=m
CONFIG_NETFILTER_XT_MATCH_ADDRTYPE=m
CONFIG_NETFILTER_XT_MATCH_CLUSTER=m
CONFIG_NETFILTER_XT_MATCH_COMMENT=m
CONFIG_NETFILTER_XT_MATCH_CONNBYTES=m
CONFIG_NETFILTER_XT_MATCH_CONNLIMIT=m
CONFIG_NETFILTER_XT_MATCH_CONNMARK=m
CONFIG_NETFILTER_XT_MATCH_CONNTRACK=m
CONFIG_NETFILTER_XT_MATCH_CPU=m
CONFIG_NETFILTER_XT_MATCH_DCCP=m
CONFIG_NETFILTER_XT_MATCH_DEVGROUP=m
CONFIG_NETFILTER_XT_MATCH_DSCP=m
CONFIG_NETFILTER_XT_MATCH_ECN=m
CONFIG_NETFILTER_XT_MATCH_ESP=m
CONFIG_NETFILTER_XT_MATCH_HASHLIMIT=m
CONFIG_NETFILTER_XT_MATCH_HELPER=m
CONFIG_NETFILTER_XT_MATCH_HL=m
CONFIG_NETFILTER_XT_MATCH_IPRANGE=m
CONFIG_NETFILTER_XT_MATCH_LENGTH=m
CONFIG_NETFILTER_XT_MATCH_LIMIT=m
CONFIG_NETFILTER_XT_MATCH_MAC=m
CONFIG_NETFILTER_XT_MATCH_MARK=m
CONFIG_NETFILTER_XT_MATCH_MULTIPORT=m
CONFIG_NETFILTER_XT_MATCH_NFACCT=m
CONFIG_NETFILTER_XT_MATCH_OSF=m
CONFIG_NETFILTER_XT_MATCH_OWNER=m
CONFIG_NETFILTER_XT_MATCH_POLICY=m
CONFIG_NETFILTER_XT_MATCH_PKTTYPE=m
CONFIG_NETFILTER_XT_MATCH_QUOTA=m
CONFIG_NETFILTER_XT_MATCH_RATEEST=m
CONFIG_NETFILTER_XT_MATCH_REALM=m
CONFIG_NETFILTER_XT_MATCH_RECENT=m
CONFIG_NETFILTER_XT_MATCH_SCTP=m
CONFIG_NETFILTER_XT_MATCH_SOCKET=m
CONFIG_NETFILTER_XT_MATCH_STATE=m
CONFIG_NETFILTER_XT_MATCH_STATISTIC=m
CONFIG_NETFILTER_XT_MATCH_STRING=m
CONFIG_NETFILTER_XT_MATCH_TCPMSS=m
CONFIG_NETFILTER_XT_MATCH_TIME=m
CONFIG_NETFILTER_XT_MATCH_U32=m
CONFIG_NF_DEFRAG_IPV4=m
CONFIG_NF_CONNTRACK_IPV4=m
CONFIG_NF_CONNTRACK_PROC_COMPAT=y
CONFIG_IP_NF_QUEUE=m
CONFIG_IP_NF_IPTABLES=m
CONFIG_IP_NF_MATCH_AH=m
CONFIG_IP_NF_MATCH_ECN=m
CONFIG_IP_NF_MATCH_RPFILTER=m
CONFIG_IP_NF_MATCH_TTL=m
CONFIG_IP_NF_FILTER=m
CONFIG_IP_NF_TARGET_REJECT=m
CONFIG_IP_NF_TARGET_ULOG=m
CONFIG_NF_NAT=m
CONFIG_NF_NAT_NEEDED=y
CONFIG_IP_NF_TARGET_MASQUERADE=m
CONFIG_IP_NF_TARGET_NETMAP=m
CONFIG_IP_NF_TARGET_REDIRECT=m
CONFIG_NF_NAT_SNMP_BASIC=m
CONFIG_NF_NAT_PROTO_DCCP=m
CONFIG_NF_NAT_PROTO_GRE=m
CONFIG_NF_NAT_PROTO_UDPLITE=m
CONFIG_NF_NAT_PROTO_SCTP=m
CONFIG_NF_NAT_FTP=m
CONFIG_NF_NAT_IRC=m
CONFIG_NF_NAT_TFTP=m
CONFIG_NF_NAT_AMANDA=m
CONFIG_NF_NAT_PPTP=m
CONFIG_NF_NAT_H323=m
CONFIG_NF_NAT_SIP=m
CONFIG_IP_NF_MANGLE=m
CONFIG_IP_NF_TARGET_CLUSTERIP=m
CONFIG_IP_NF_TARGET_ECN=m
CONFIG_IP_NF_TARGET_TTL=m
CONFIG_IP_NF_RAW=m
CONFIG_IP_NF_SECURITY=m
CONFIG_IP_NF_ARPTABLES=m
CONFIG_IP_NF_ARPFILTER=m
CONFIG_IP_NF_ARP_MANGLE=m
CONFIG_NF_DEFRAG_IPV6=m
CONFIG_NF_CONNTRACK_IPV6=m
CONFIG_IP6_NF_IPTABLES=m
CONFIG_IP6_NF_MATCH_AH=m
CONFIG_IP6_NF_MATCH_EUI64=m
CONFIG_IP6_NF_MATCH_FRAG=m
CONFIG_IP6_NF_MATCH_OPTS=m
CONFIG_IP6_NF_MATCH_HL=m
CONFIG_IP6_NF_MATCH_IPV6HEADER=m
CONFIG_IP6_NF_MATCH_MH=m
CONFIG_IP6_NF_MATCH_RPFILTER=m
CONFIG_IP6_NF_MATCH_RT=m
CONFIG_IP6_NF_TARGET_HL=m
CONFIG_IP6_NF_FILTER=m
CONFIG_IP6_NF_TARGET_REJECT=m
CONFIG_IP6_NF_MANGLE=m
CONFIG_IP6_NF_RAW=m
CONFIG_IP6_NF_SECURITY=m
CONFIG_IP_SCTP=m
CONFIG_SCTP_HMAC_MD5=y
CONFIG_ATM=m
CONFIG_ATM_CLIP=m
CONFIG_ATM_CLIP_NO_ICMP=y
CONFIG_ATM_LANE=m
CONFIG_ATM_MPOA=m
CONFIG_ATM_BR2684=m
CONFIG_ATM_BR2684_IPFILTER=y
CONFIG_L2TP=m
CONFIG_L2TP_DEBUGFS=m
CONFIG_L2TP_V3=y
CONFIG_L2TP_IP=m
CONFIG_L2TP_ETH=m
CONFIG_STP=m
CONFIG_BRIDGE=m
CONFIG_BRIDGE_IGMP_SNOOPING=y
CONFIG_LLC=m
CONFIG_ATALK=m
CONFIG_DEV_APPLETALK=m
CONFIG_IPDDP=m
CONFIG_IPDDP_ENCAP=y
CONFIG_IPDDP_DECAP=y
CONFIG_PHONET=m
CONFIG_NET_SCHED=y
CONFIG_NET_CLS=y
CONFIG_NET_EMATCH=y
CONFIG_NET_EMATCH_STACK=32
CONFIG_NET_CLS_ACT=y
CONFIG_NET_SCH_FIFO=y
CONFIG_DNS_RESOLVER=y
CONFIG_BATMAN_ADV=m
CONFIG_BATMAN_ADV_BLA=y
CONFIG_RPS=y
CONFIG_RFS_ACCEL=y
CONFIG_XPS=y
CONFIG_BQL=y
CONFIG_BT=m
CONFIG_BT_RFCOMM=m
CONFIG_BT_RFCOMM_TTY=y
CONFIG_BT_BNEP=m
CONFIG_BT_BNEP_MC_FILTER=y
CONFIG_BT_BNEP_PROTO_FILTER=y
CONFIG_BT_HIDP=m
CONFIG_BT_HCIBTUSB=m
CONFIG_BT_HCIBTSDIO=m
CONFIG_BT_HCIUART=m
CONFIG_BT_HCIUART_H4=y
CONFIG_BT_HCIUART_BCSP=y
CONFIG_BT_HCIUART_LL=y
CONFIG_BT_HCIBCM203X=m
CONFIG_BT_HCIBPA10X=m
CONFIG_BT_HCIBFUSB=m
CONFIG_BT_HCIVHCI=m
CONFIG_AF_RXRPC=m
CONFIG_FIB_RULES=y
CONFIG_WIRELESS=y
CONFIG_CFG80211=m
CONFIG_NL80211_TESTMODE=y
CONFIG_CFG80211_DEFAULT_PS=y
CONFIG_LIB80211=m
CONFIG_MAC80211=m
CONFIG_MAC80211_HAS_RC=y
CONFIG_MAC80211_RC_MINSTREL=y
CONFIG_MAC80211_RC_MINSTREL_HT=y
CONFIG_MAC80211_RC_DEFAULT_MINSTREL=y
CONFIG_MAC80211_RC_DEFAULT="minstrel_ht"
CONFIG_MAC80211_LEDS=y
CONFIG_RFKILL=y
CONFIG_RFKILL_LEDS=y
CONFIG_RFKILL_INPUT=y
CONFIG_RFKILL_REGULATOR=y
CONFIG_CAIF=m
CONFIG_CAIF_NETDEV=m
CONFIG_CAIF_USB=m
CONFIG_CEPH_LIB=m
CONFIG_HAVE_BPF_JIT=y
CONFIG_UEVENT_HELPER_PATH=""
CONFIG_DEVTMPFS=y
CONFIG_DEVTMPFS_MOUNT=y
CONFIG_STANDALONE=y
CONFIG_PREVENT_FIRMWARE_BUILD=y
CONFIG_FW_LOADER=y
CONFIG_FIRMWARE_IN_KERNEL=y
CONFIG_EXTRA_FIRMWARE=""
CONFIG_DEBUG_DEVRES=y
CONFIG_DMA_SHARED_BUFFER=y
CONFIG_CONNECTOR=y
CONFIG_PROC_EVENTS=y
CONFIG_PNP=y
CONFIG_PNP_DEBUG_MESSAGES=y
CONFIG_PNPACPI=y
CONFIG_BLK_DEV=y
CONFIG_BLK_DEV_LOOP=y
CONFIG_BLK_DEV_LOOP_MIN_COUNT=8
CONFIG_BLK_DEV_CRYPTOLOOP=y
CONFIG_BLK_DEV_NBD=m
CONFIG_BLK_DEV_RAM=y
CONFIG_BLK_DEV_RAM_COUNT=16
CONFIG_BLK_DEV_RAM_SIZE=16384
CONFIG_BLK_DEV_XIP=y
CONFIG_SENSORS_LIS3LV02D=m
CONFIG_TIFM_CORE=m
CONFIG_TIFM_7XX1=m
CONFIG_PCH_PHUB=m
CONFIG_SENSORS_LIS3_I2C=m
CONFIG_HAVE_IDE=y
CONFIG_SCSI_MOD=y
CONFIG_SCSI=y
CONFIG_SCSI_DMA=y
CONFIG_SCSI_PROC_FS=y
CONFIG_BLK_DEV_SD=y
CONFIG_BLK_DEV_SR=y
CONFIG_BLK_DEV_SR_VENDOR=y
CONFIG_CHR_DEV_SG=y
CONFIG_SCSI_CONSTANTS=y
CONFIG_SCSI_WAIT_SCAN=m
CONFIG_SCSI_SPI_ATTRS=y
CONFIG_ATA=y
CONFIG_ATA_VERBOSE_ERROR=y
CONFIG_ATA_ACPI=y
CONFIG_SATA_PMP=y
CONFIG_SATA_AHCI=y
CONFIG_ATA_SFF=y
CONFIG_ATA_BMDMA=y
CONFIG_ATA_PIIX=y
CONFIG_PATA_OLDPIIX=y
CONFIG_PATA_SCH=y
CONFIG_PATA_MPIIX=m
CONFIG_PATA_ACPI=m
CONFIG_MD=y
CONFIG_BLK_DEV_MD=y
CONFIG_MD_AUTODETECT=y
CONFIG_BLK_DEV_DM=y
CONFIG_DM_CRYPT=y
CONFIG_DM_SNAPSHOT=y
CONFIG_DM_MIRROR=y
CONFIG_DM_ZERO=y
CONFIG_I2O=y
CONFIG_I2O_LCT_NOTIFY_ON_CHANGES=y
CONFIG_I2O_EXT_ADAPTEC=y
CONFIG_I2O_EXT_ADAPTEC_DMA64=y
CONFIG_I2O_CONFIG=m
CONFIG_I2O_CONFIG_OLD_IOCTL=y
CONFIG_I2O_BUS=m
CONFIG_I2O_BLOCK=m
CONFIG_I2O_SCSI=m
CONFIG_I2O_PROC=m
CONFIG_NETDEVICES=y
CONFIG_NET_CORE=y
CONFIG_BONDING=m
CONFIG_MII=m
CONFIG_NETCONSOLE=y
CONFIG_NETPOLL=y
CONFIG_NET_POLL_CONTROLLER=y
CONFIG_ATM_DRIVERS=y
CONFIG_ETHERNET=y
CONFIG_NET_VENDOR_INTEL=y
CONFIG_E1000E=y
CONFIG_NET_VENDOR_WIZNET=y
CONFIG_USB_USBNET=m
CONFIG_USB_NET_AX8817X=m
CONFIG_USB_NET_CDCETHER=m
CONFIG_USB_NET_CDC_EEM=m
CONFIG_USB_NET_CDC_NCM=m
CONFIG_USB_NET_NET1080=m
CONFIG_USB_NET_CDC_SUBSET=m
CONFIG_USB_BELKIN=y
CONFIG_USB_ARMLINUX=y
CONFIG_USB_NET_ZAURUS=m
CONFIG_USB_HSO=m
CONFIG_USB_CDC_PHONET=m
CONFIG_USB_IPHETH=m
CONFIG_WLAN=y
CONFIG_IWLWIFI=m
CONFIG_IWLWIFI_DEVICE_TESTMODE=y
CONFIG_IWLWIFI_P2P=y
CONFIG_IWLWIFI_EXPERIMENTAL_MFP=y
CONFIG_VMXNET3=m
CONFIG_INPUT=y
CONFIG_INPUT_FF_MEMLESS=y
CONFIG_INPUT_POLLDEV=y
CONFIG_INPUT_SPARSEKMAP=m
CONFIG_INPUT_MOUSEDEV=y
CONFIG_INPUT_MOUSEDEV_SCREEN_X=1024
CONFIG_INPUT_MOUSEDEV_SCREEN_Y=768
CONFIG_INPUT_EVDEV=y
CONFIG_INPUT_KEYBOARD=y
CONFIG_KEYBOARD_ATKBD=y
CONFIG_INPUT_MOUSE=y
CONFIG_MOUSE_PS2=y
CONFIG_MOUSE_PS2_ALPS=y
CONFIG_MOUSE_PS2_LOGIPS2PP=y
CONFIG_MOUSE_PS2_SYNAPTICS=y
CONFIG_MOUSE_PS2_LIFEBOOK=y
CONFIG_MOUSE_PS2_TRACKPOINT=y
CONFIG_MOUSE_SYNAPTICS_I2C=m
CONFIG_INPUT_TABLET=y
CONFIG_TABLET_USB_WACOM=m
CONFIG_SERIO=y
CONFIG_SERIO_I8042=y
CONFIG_SERIO_SERPORT=y
CONFIG_SERIO_LIBPS2=y
CONFIG_VT=y
CONFIG_CONSOLE_TRANSLATIONS=y
CONFIG_VT_CONSOLE=y
CONFIG_VT_CONSOLE_SLEEP=y
CONFIG_HW_CONSOLE=y
CONFIG_VT_HW_CONSOLE_BINDING=y
CONFIG_UNIX98_PTYS=y
CONFIG_SERIAL_NONSTANDARD=y
CONFIG_N_GSM=m
CONFIG_KCOPY=m
CONFIG_DEVKMEM=y
CONFIG_SERIAL_8250=y
CONFIG_SERIAL_8250_CONSOLE=y
CONFIG_FIX_EARLYCON_MEM=y
CONFIG_SERIAL_8250_PCI=y
CONFIG_SERIAL_8250_PNP=y
CONFIG_SERIAL_8250_NR_UARTS=32
CONFIG_SERIAL_8250_RUNTIME_UARTS=4
CONFIG_SERIAL_8250_EXTENDED=y
CONFIG_SERIAL_8250_MANY_PORTS=y
CONFIG_SERIAL_8250_SHARE_IRQ=y
CONFIG_SERIAL_8250_DETECT_IRQ=y
CONFIG_SERIAL_8250_RSA=y
CONFIG_SERIAL_CORE=y
CONFIG_SERIAL_CORE_CONSOLE=y
CONFIG_HW_RANDOM=y
CONFIG_HW_RANDOM_INTEL=y
CONFIG_NVRAM=y
CONFIG_HPET=y
CONFIG_TCG_TPM=y
CONFIG_TCG_TIS=y
CONFIG_TCG_NSC=m
CONFIG_TCG_ATMEL=m
CONFIG_TCG_INFINEON=m
CONFIG_DEVPORT=y
CONFIG_I2C=y
CONFIG_I2C_BOARDINFO=y
CONFIG_I2C_COMPAT=y
CONFIG_I2C_CHARDEV=m
CONFIG_I2C_MUX=m
CONFIG_I2C_MUX_PCA9541=m
CONFIG_I2C_MUX_PCA954x=m
CONFIG_I2C_HELPER_AUTO=y
CONFIG_I2C_ALGOBIT=y
CONFIG_I2C_I801=y
CONFIG_I2C_EG20T=m
CONFIG_I2C_OCORES=m
CONFIG_ARCH_WANT_OPTIONAL_GPIOLIB=y
CONFIG_GPIOLIB=y
CONFIG_POWER_SUPPLY=y
CONFIG_PDA_POWER=m
CONFIG_HWMON=y
CONFIG_HWMON_VID=m
CONFIG_SENSORS_ASC7621=m
CONFIG_SENSORS_GPIO_FAN=y
CONFIG_SENSORS_CORETEMP=y
CONFIG_SENSORS_DME1737=m
CONFIG_SENSORS_EMC1403=m
CONFIG_SENSORS_EMC2103=m
CONFIG_SENSORS_EMC6W201=m
CONFIG_SENSORS_ACPI_POWER=m
CONFIG_THERMAL=y
CONFIG_THERMAL_HWMON=y
CONFIG_WATCHDOG=y
CONFIG_I6300ESB_WDT=m
CONFIG_ITCO_WDT=m
CONFIG_ITCO_VENDOR_SUPPORT=y
CONFIG_SSB_POSSIBLE=y
CONFIG_BCMA_POSSIBLE=y
CONFIG_MFD_CORE=m
CONFIG_LPC_SCH=m
CONFIG_LPC_ICH=m
CONFIG_REGULATOR=y
CONFIG_MEDIA_SUPPORT=m
CONFIG_MEDIA_CONTROLLER=y
CONFIG_VIDEO_DEV=m
CONFIG_VIDEO_V4L2_COMMON=m
CONFIG_VIDEO_V4L2_SUBDEV_API=y
CONFIG_DVB_CORE=m
CONFIG_DVB_NET=y
CONFIG_VIDEO_MEDIA=m
CONFIG_MEDIA_TUNER=m
CONFIG_MEDIA_TUNER_SIMPLE=m
CONFIG_MEDIA_TUNER_TDA8290=m
CONFIG_MEDIA_TUNER_TDA827X=m
CONFIG_MEDIA_TUNER_TDA18271=m
CONFIG_MEDIA_TUNER_TDA9887=m
CONFIG_MEDIA_TUNER_TEA5761=m
CONFIG_MEDIA_TUNER_TEA5767=m
CONFIG_MEDIA_TUNER_MT20XX=m
CONFIG_MEDIA_TUNER_XC2028=m
CONFIG_MEDIA_TUNER_XC5000=m
CONFIG_MEDIA_TUNER_XC4000=m
CONFIG_MEDIA_TUNER_MC44S803=m
CONFIG_VIDEO_V4L2=m
CONFIG_VIDEOBUF2_CORE=m
CONFIG_VIDEOBUF2_MEMOPS=m
CONFIG_VIDEOBUF2_VMALLOC=m
CONFIG_VIDEO_CAPTURE_DRIVERS=y
CONFIG_VIDEO_MSP3400=m
CONFIG_VIDEO_CS53L32A=m
CONFIG_VIDEO_WM8775=m
CONFIG_VIDEO_SAA711X=m
CONFIG_VIDEO_CX25840=m
CONFIG_VIDEO_CX2341X=m
CONFIG_V4L_USB_DRIVERS=y
CONFIG_USB_VIDEO_CLASS=m
CONFIG_USB_VIDEO_CLASS_INPUT_EVDEV=y
CONFIG_V4L_PCI_DRIVERS=y
CONFIG_V4L_PLATFORM_DRIVERS=y
CONFIG_DVB_MAX_ADAPTERS=8
CONFIG_AGP=y
CONFIG_AGP_INTEL=y
CONFIG_VGA_ARB=y
CONFIG_VGA_ARB_MAX_GPUS=16
CONFIG_DRM=y
CONFIG_DRM_KMS_HELPER=y
CONFIG_DRM_I915=y
CONFIG_DRM_I915_KMS=y
CONFIG_STUB_POULSBO=y
CONFIG_VIDEO_OUTPUT_CONTROL=y
CONFIG_FB=y
CONFIG_FB_BOOT_VESA_SUPPORT=y
CONFIG_FB_CFB_FILLRECT=y
CONFIG_FB_CFB_COPYAREA=y
CONFIG_FB_CFB_IMAGEBLIT=y
CONFIG_FB_FOREIGN_ENDIAN=y
CONFIG_FB_BOTH_ENDIAN=y
CONFIG_FB_MODE_HELPERS=y
CONFIG_FB_TILEBLITTING=y
CONFIG_FB_VESA=y
CONFIG_FB_EFI=y
CONFIG_BACKLIGHT_LCD_SUPPORT=y
CONFIG_LCD_CLASS_DEVICE=y
CONFIG_LCD_PLATFORM=y
CONFIG_BACKLIGHT_CLASS_DEVICE=y
CONFIG_BACKLIGHT_GENERIC=y
CONFIG_VGA_CONSOLE=y
CONFIG_VGACON_SOFT_SCROLLBACK=y
CONFIG_VGACON_SOFT_SCROLLBACK_SIZE=64
CONFIG_DUMMY_CONSOLE=y
CONFIG_FRAMEBUFFER_CONSOLE=y
CONFIG_FRAMEBUFFER_CONSOLE_DETECT_PRIMARY=y
CONFIG_FONTS=y
CONFIG_FONT_8x16=y
CONFIG_FONT_AUTOSELECT=y
CONFIG_LOGO=y
CONFIG_LOGO_LINUX_CLUT224=y
CONFIG_SOUND=m
CONFIG_SOUND_OSS_CORE=y
CONFIG_SOUND_OSS_CORE_PRECLAIM=y
CONFIG_SND=m
CONFIG_SND_TIMER=m
CONFIG_SND_PCM=m
CONFIG_SND_HWDEP=m
CONFIG_SND_SEQUENCER=m
CONFIG_SND_SEQ_DUMMY=m
CONFIG_SND_OSSEMUL=y
CONFIG_SND_MIXER_OSS=m
CONFIG_SND_PCM_OSS=m
CONFIG_SND_PCM_OSS_PLUGINS=y
CONFIG_SND_SEQUENCER_OSS=y
CONFIG_SND_HRTIMER=m
CONFIG_SND_SEQ_HRTIMER_DEFAULT=y
CONFIG_SND_DYNAMIC_MINORS=y
CONFIG_SND_SUPPORT_OLD_API=y
CONFIG_SND_VERBOSE_PROCFS=y
CONFIG_SND_VMASTER=y
CONFIG_SND_KCTL_JACK=y
CONFIG_SND_DMA_SGBUF=y
CONFIG_SND_DRIVERS=y
CONFIG_SND_PCI=y
CONFIG_SND_HDA_INTEL=m
CONFIG_SND_HDA_PREALLOC_SIZE=64
CONFIG_SND_HDA_HWDEP=y
CONFIG_SND_HDA_CODEC_REALTEK=y
CONFIG_SND_HDA_CODEC_ANALOG=y
CONFIG_SND_HDA_CODEC_SIGMATEL=y
CONFIG_SND_HDA_CODEC_VIA=y
CONFIG_SND_HDA_CODEC_HDMI=y
CONFIG_SND_HDA_CODEC_CIRRUS=y
CONFIG_SND_HDA_CODEC_CONEXANT=y
CONFIG_SND_HDA_CODEC_CA0110=y
CONFIG_SND_HDA_CODEC_CA0132=y
CONFIG_SND_HDA_CODEC_CMEDIA=y
CONFIG_SND_HDA_CODEC_SI3054=y
CONFIG_SND_HDA_GENERIC=y
CONFIG_SND_USB=y
CONFIG_HID=y
CONFIG_HIDRAW=y
CONFIG_HID_GENERIC=y
CONFIG_HID_GYRATION=y
CONFIG_HID_NTRIG=y
CONFIG_HID_PANTHERLORD=y
CONFIG_PANTHERLORD_FF=y
CONFIG_HID_PETALYNX=y
CONFIG_HID_SAMSUNG=y
CONFIG_HID_SONY=y
CONFIG_HID_SUNPLUS=y
CONFIG_HID_TOPSEED=y
CONFIG_USB_HID=y
CONFIG_HID_PID=y
CONFIG_USB_HIDDEV=y
CONFIG_USB_ARCH_HAS_OHCI=y
CONFIG_USB_ARCH_HAS_EHCI=y
CONFIG_USB_ARCH_HAS_XHCI=y
CONFIG_USB_SUPPORT=y
CONFIG_USB_COMMON=y
CONFIG_USB_ARCH_HAS_HCD=y
CONFIG_USB=y
CONFIG_USB_DEBUG=y
CONFIG_USB_ANNOUNCE_NEW_DEVICES=y
CONFIG_USB_SUSPEND=y
CONFIG_USB_MON=y
CONFIG_USB_XHCI_HCD=y
CONFIG_USB_EHCI_HCD=y
CONFIG_USB_EHCI_ROOT_HUB_TT=y
CONFIG_USB_OHCI_HCD=y
CONFIG_USB_OHCI_LITTLE_ENDIAN=y
CONFIG_USB_UHCI_HCD=y
CONFIG_USB_ACM=m
CONFIG_USB_PRINTER=m
CONFIG_USB_STORAGE=y
CONFIG_USB_LIBUSUAL=y
CONFIG_USB_SERIAL=m
CONFIG_USB_SERIAL_IPAQ=m
CONFIG_USB_GADGET=m
CONFIG_USB_GADGET_VBUS_DRAW=2
CONFIG_USB_GADGET_STORAGE_NUM_BUFFERS=2
CONFIG_USB_GOKU=m
CONFIG_USB_ETH=m
CONFIG_USB_ETH_RNDIS=y
CONFIG_USB_ETH_EEM=y
CONFIG_USB_G_NCM=m
CONFIG_USB_G_SERIAL=m
CONFIG_USB_CDC_COMPOSITE=m
CONFIG_USB_G_ACM_MS=m
CONFIG_USB_G_MULTI=m
CONFIG_USB_G_MULTI_RNDIS=y
CONFIG_USB_G_MULTI_CDC=y
CONFIG_USB_G_HID=m
CONFIG_USB_G_WEBCAM=m
CONFIG_MMC=m
CONFIG_MMC_BLOCK=m
CONFIG_MMC_BLOCK_MINORS=8
CONFIG_MMC_BLOCK_BOUNCE=y
CONFIG_MMC_SDHCI=m
CONFIG_MMC_SDHCI_PCI=m
CONFIG_MMC_TIFM_SD=m
CONFIG_MMC_USHC=m
CONFIG_NEW_LEDS=y
CONFIG_LEDS_CLASS=y
CONFIG_LEDS_TRIGGERS=y
CONFIG_LEDS_TRIGGER_TIMER=m
CONFIG_LEDS_TRIGGER_HEARTBEAT=m
CONFIG_LEDS_TRIGGER_BACKLIGHT=m
CONFIG_LEDS_TRIGGER_GPIO=m
CONFIG_LEDS_TRIGGER_DEFAULT_ON=m
CONFIG_EDAC=y
CONFIG_RTC_LIB=y
CONFIG_RTC_CLASS=y
CONFIG_RTC_INTF_SYSFS=y
CONFIG_RTC_INTF_PROC=y
CONFIG_RTC_INTF_DEV=y
CONFIG_RTC_DRV_CMOS=y
CONFIG_DMADEVICES=y
CONFIG_INTEL_MID_DMAC=m
CONFIG_INTEL_IOATDMA=m
CONFIG_DMA_ENGINE=y
CONFIG_NET_DMA=y
CONFIG_DCA=m
CONFIG_STAGING=y
CONFIG_ZRAM=m
CONFIG_ZRAM_DEBUG=y
CONFIG_ZCACHE=y
CONFIG_ZSMALLOC=y
CONFIG_PHONE=m
CONFIG_PHONE_IXJ=m
CONFIG_X86_PLATFORM_DEVICES=y
CONFIG_TOSHIBA_BT_RFKILL=y
CONFIG_INTEL_IPS=y
CONFIG_INTEL_OAKTRAIL=y
CONFIG_CLKEVT_I8253=y
CONFIG_I8253_LOCK=y
CONFIG_CLKBLD_I8253=y
CONFIG_IOMMU_SUPPORT=y
CONFIG_PM_DEVFREQ=y
CONFIG_DEVFREQ_GOV_SIMPLE_ONDEMAND=y
CONFIG_DEVFREQ_GOV_PERFORMANCE=y
CONFIG_DEVFREQ_GOV_POWERSAVE=y
CONFIG_DEVFREQ_GOV_USERSPACE=y
CONFIG_FIRMWARE_MEMMAP=y
CONFIG_EFI_VARS=y
CONFIG_DMIID=y
CONFIG_DCACHE_WORD_ACCESS=y
CONFIG_EXT2_FS=y
CONFIG_EXT2_FS_XATTR=y
CONFIG_EXT2_FS_POSIX_ACL=y
CONFIG_EXT2_FS_SECURITY=y
CONFIG_EXT2_FS_XIP=y
CONFIG_EXT3_FS=m
CONFIG_EXT3_DEFAULTS_TO_ORDERED=y
CONFIG_EXT3_FS_XATTR=y
CONFIG_EXT3_FS_POSIX_ACL=y
CONFIG_EXT3_FS_SECURITY=y
CONFIG_EXT4_FS=m
CONFIG_EXT4_FS_XATTR=y
CONFIG_EXT4_FS_POSIX_ACL=y
CONFIG_EXT4_FS_SECURITY=y
CONFIG_FS_XIP=y
CONFIG_JBD=m
CONFIG_JBD2=m
CONFIG_FS_MBCACHE=y
CONFIG_REISERFS_FS=m
CONFIG_REISERFS_CHECK=y
CONFIG_REISERFS_PROC_INFO=y
CONFIG_REISERFS_FS_XATTR=y
CONFIG_REISERFS_FS_POSIX_ACL=y
CONFIG_REISERFS_FS_SECURITY=y
CONFIG_JFS_FS=m
CONFIG_JFS_POSIX_ACL=y
CONFIG_JFS_SECURITY=y
CONFIG_JFS_STATISTICS=y
CONFIG_XFS_FS=m
CONFIG_XFS_QUOTA=y
CONFIG_XFS_POSIX_ACL=y
CONFIG_XFS_RT=y
CONFIG_GFS2_FS=m
CONFIG_GFS2_FS_LOCKING_DLM=y
CONFIG_OCFS2_FS=m
CONFIG_OCFS2_FS_O2CB=m
CONFIG_OCFS2_FS_USERSPACE_CLUSTER=m
CONFIG_OCFS2_FS_STATS=y
CONFIG_OCFS2_DEBUG_MASKLOG=y
CONFIG_BTRFS_FS=y
CONFIG_BTRFS_FS_POSIX_ACL=y
CONFIG_NILFS2_FS=m
CONFIG_FS_POSIX_ACL=y
CONFIG_EXPORTFS=m
CONFIG_FILE_LOCKING=y
CONFIG_FSNOTIFY=y
CONFIG_DNOTIFY=y
CONFIG_INOTIFY_USER=y
CONFIG_FANOTIFY=y
CONFIG_FANOTIFY_ACCESS_PERMISSIONS=y
CONFIG_QUOTA=y
CONFIG_QUOTA_NETLINK_INTERFACE=y
CONFIG_QUOTA_DEBUG=y
CONFIG_QUOTA_TREE=y
CONFIG_QFMT_V2=y
CONFIG_QUOTACTL=y
CONFIG_QUOTACTL_COMPAT=y
CONFIG_AUTOFS4_FS=y
CONFIG_FUSE_FS=m
CONFIG_CUSE=m
CONFIG_GENERIC_ACL=y
CONFIG_FSCACHE=m
CONFIG_FSCACHE_STATS=y
CONFIG_FSCACHE_HISTOGRAM=y
CONFIG_CACHEFILES=m
CONFIG_CACHEFILES_HISTOGRAM=y
CONFIG_ISO9660_FS=m
CONFIG_JOLIET=y
CONFIG_ZISOFS=y
CONFIG_UDF_FS=m
CONFIG_UDF_NLS=y
CONFIG_FAT_FS=m
CONFIG_MSDOS_FS=m
CONFIG_VFAT_FS=m
CONFIG_FAT_DEFAULT_CODEPAGE=437
CONFIG_FAT_DEFAULT_IOCHARSET="iso8859-1"
CONFIG_PROC_FS=y
CONFIG_PROC_KCORE=y
CONFIG_PROC_VMCORE=y
CONFIG_PROC_SYSCTL=y
CONFIG_PROC_PAGE_MONITOR=y
CONFIG_SYSFS=y
CONFIG_TMPFS=y
CONFIG_TMPFS_POSIX_ACL=y
CONFIG_TMPFS_XATTR=y
CONFIG_HUGETLBFS=y
CONFIG_HUGETLB_PAGE=y
CONFIG_CONFIGFS_FS=m
CONFIG_MISC_FILESYSTEMS=y
CONFIG_ADFS_FS=m
CONFIG_AFFS_FS=m
CONFIG_ECRYPT_FS=m
CONFIG_HFS_FS=m
CONFIG_HFSPLUS_FS=m
CONFIG_BEFS_FS=m
CONFIG_BFS_FS=m
CONFIG_EFS_FS=m
CONFIG_LOGFS=m
CONFIG_CRAMFS=m
CONFIG_SQUASHFS=m
CONFIG_SQUASHFS_XATTR=y
CONFIG_SQUASHFS_ZLIB=y
CONFIG_SQUASHFS_LZO=y
CONFIG_SQUASHFS_XZ=y
CONFIG_SQUASHFS_FRAGMENT_CACHE_SIZE=3
CONFIG_VXFS_FS=m
CONFIG_MINIX_FS=m
CONFIG_OMFS_FS=m
CONFIG_HPFS_FS=m
CONFIG_QNX4FS_FS=m
CONFIG_QNX6FS_FS=m
CONFIG_ROMFS_FS=m
CONFIG_ROMFS_BACKED_BY_BLOCK=y
CONFIG_ROMFS_ON_BLOCK=y
CONFIG_PSTORE=y
CONFIG_SYSV_FS=m
CONFIG_UFS_FS=m
CONFIG_UFS_FS_WRITE=y
CONFIG_NETWORK_FILESYSTEMS=y
CONFIG_NFS_FS=m
CONFIG_NFS_V2=y
CONFIG_NFS_V3=y
CONFIG_NFS_V3_ACL=y
CONFIG_NFS_V4=y
CONFIG_NFS_USE_KERNEL_DNS=y
CONFIG_LOCKD=m
CONFIG_LOCKD_V4=y
CONFIG_NFS_ACL_SUPPORT=m
CONFIG_NFS_COMMON=y
CONFIG_SUNRPC=m
CONFIG_SUNRPC_GSS=m
CONFIG_RPCSEC_GSS_KRB5=m
CONFIG_CEPH_FS=m
CONFIG_CIFS=m
CONFIG_CIFS_STATS=y
CONFIG_CIFS_STATS2=y
CONFIG_CIFS_WEAK_PW_HASH=y
CONFIG_CIFS_UPCALL=y
CONFIG_CIFS_XATTR=y
CONFIG_CIFS_POSIX=y
CONFIG_CIFS_DFS_UPCALL=y
CONFIG_CIFS_ACL=y
CONFIG_CODA_FS=m
CONFIG_AFS_FS=m
CONFIG_NLS=y
CONFIG_NLS_DEFAULT="utf8"
CONFIG_NLS_CODEPAGE_437=y
CONFIG_NLS_ASCII=y
CONFIG_NLS_ISO8859_1=y
CONFIG_NLS_ISO8859_15=y
CONFIG_NLS_UTF8=y
CONFIG_DLM=m
CONFIG_TRACE_IRQFLAGS_SUPPORT=y
CONFIG_PRINTK_TIME=y
CONFIG_DEFAULT_MESSAGE_LOGLEVEL=4
CONFIG_ENABLE_MUST_CHECK=y
CONFIG_FRAME_WARN=2048
CONFIG_MAGIC_SYSRQ=y
CONFIG_DEBUG_FS=y
CONFIG_DEBUG_KERNEL=y
CONFIG_PANIC_ON_OOPS_VALUE=0
CONFIG_SCHEDSTATS=y
CONFIG_TIMER_STATS=y
CONFIG_STACKTRACE=y
CONFIG_DEBUG_STACK_USAGE=y
CONFIG_DEBUG_BUGVERBOSE=y
CONFIG_ARCH_WANT_FRAME_POINTERS=y
CONFIG_FRAME_POINTER=y
CONFIG_RCU_CPU_STALL_TIMEOUT=60
CONFIG_USER_STACKTRACE_SUPPORT=y
CONFIG_NOP_TRACER=y
CONFIG_HAVE_FUNCTION_TRACER=y
CONFIG_HAVE_FUNCTION_GRAPH_TRACER=y
CONFIG_HAVE_FUNCTION_GRAPH_FP_TEST=y
CONFIG_HAVE_FUNCTION_TRACE_MCOUNT_TEST=y
CONFIG_HAVE_DYNAMIC_FTRACE=y
CONFIG_HAVE_FTRACE_MCOUNT_RECORD=y
CONFIG_HAVE_SYSCALL_TRACEPOINTS=y
CONFIG_HAVE_C_RECORDMCOUNT=y
CONFIG_RING_BUFFER=y
CONFIG_EVENT_TRACING=y
CONFIG_EVENT_POWER_TRACING_DEPRECATED=y
CONFIG_CONTEXT_SWITCH_TRACER=y
CONFIG_TRACING=y
CONFIG_GENERIC_TRACER=y
CONFIG_TRACING_SUPPORT=y
CONFIG_FTRACE=y
CONFIG_BRANCH_PROFILE_NONE=y
CONFIG_BLK_DEV_IO_TRACE=y
CONFIG_KPROBE_EVENT=y
CONFIG_PROBE_EVENTS=y
CONFIG_PROVIDE_OHCI1394_DMA_INIT=y
CONFIG_HAVE_ARCH_KGDB=y
CONFIG_HAVE_ARCH_KMEMCHECK=y
CONFIG_X86_VERBOSE_BOOTUP=y
CONFIG_EARLY_PRINTK=y
CONFIG_EARLY_PRINTK_DBGP=y
CONFIG_DEBUG_STACKOVERFLOW=y
CONFIG_DEBUG_RODATA=y
CONFIG_DEBUG_NX_TEST=m
CONFIG_HAVE_MMIOTRACE_SUPPORT=y
CONFIG_IO_DELAY_TYPE_0X80=0
CONFIG_IO_DELAY_TYPE_0XED=1
CONFIG_IO_DELAY_TYPE_UDELAY=2
CONFIG_IO_DELAY_TYPE_NONE=3
CONFIG_IO_DELAY_0X80=y
CONFIG_DEFAULT_IO_DELAY_TYPE=0
CONFIG_DEBUG_BOOT_PARAMS=y
CONFIG_OPTIMIZE_INLINING=y
CONFIG_KEYS=y
CONFIG_TRUSTED_KEYS=y
CONFIG_ENCRYPTED_KEYS=y
CONFIG_KEYS_DEBUG_PROC_KEYS=y
CONFIG_SECURITY=y
CONFIG_SECURITYFS=y
CONFIG_SECURITY_NETWORK=y
CONFIG_SECURITY_NETWORK_XFRM=y
CONFIG_SECURITY_PATH=y
CONFIG_LSM_MMAP_MIN_ADDR=65536
CONFIG_SECURITY_SELINUX=y
CONFIG_SECURITY_SELINUX_BOOTPARAM=y
CONFIG_SECURITY_SELINUX_BOOTPARAM_VALUE=1
CONFIG_SECURITY_SELINUX_DISABLE=y
CONFIG_SECURITY_SELINUX_DEVELOP=y
CONFIG_SECURITY_SELINUX_AVC_STATS=y
CONFIG_SECURITY_SELINUX_CHECKREQPROT_VALUE=1
CONFIG_SECURITY_YAMA=y
CONFIG_INTEGRITY=y
CONFIG_IMA=y
CONFIG_IMA_MEASURE_PCR_IDX=10
CONFIG_IMA_AUDIT=y
CONFIG_IMA_LSM_RULES=y
CONFIG_DEFAULT_SECURITY_SELINUX=y
CONFIG_DEFAULT_SECURITY="selinux"
CONFIG_ASYNC_TX_DISABLE_PQ_VAL_DMA=y
CONFIG_ASYNC_TX_DISABLE_XOR_VAL_DMA=y
CONFIG_CRYPTO=y
CONFIG_CRYPTO_ALGAPI=y
CONFIG_CRYPTO_ALGAPI2=y
CONFIG_CRYPTO_AEAD=y
CONFIG_CRYPTO_AEAD2=y
CONFIG_CRYPTO_BLKCIPHER=y
CONFIG_CRYPTO_BLKCIPHER2=y
CONFIG_CRYPTO_HASH=y
CONFIG_CRYPTO_HASH2=y
CONFIG_CRYPTO_RNG=y
CONFIG_CRYPTO_RNG2=y
CONFIG_CRYPTO_PCOMP=y
CONFIG_CRYPTO_PCOMP2=y
CONFIG_CRYPTO_MANAGER=y
CONFIG_CRYPTO_MANAGER2=y
CONFIG_CRYPTO_USER=m
CONFIG_CRYPTO_MANAGER_DISABLE_TESTS=y
CONFIG_CRYPTO_GF128MUL=y
CONFIG_CRYPTO_NULL=m
CONFIG_CRYPTO_PCRYPT=y
CONFIG_CRYPTO_WORKQUEUE=y
CONFIG_CRYPTO_CRYPTD=y
CONFIG_CRYPTO_AUTHENC=y
CONFIG_CRYPTO_CCM=m
CONFIG_CRYPTO_GCM=m
CONFIG_CRYPTO_SEQIV=y
CONFIG_CRYPTO_CBC=y
CONFIG_CRYPTO_CTR=y
CONFIG_CRYPTO_CTS=y
CONFIG_CRYPTO_ECB=y
CONFIG_CRYPTO_LRW=y
CONFIG_CRYPTO_PCBC=y
CONFIG_CRYPTO_XTS=y
CONFIG_CRYPTO_HMAC=y
CONFIG_CRYPTO_XCBC=y
CONFIG_CRYPTO_VMAC=y
CONFIG_CRYPTO_CRC32C=y
CONFIG_CRYPTO_CRC32C_INTEL=y
CONFIG_CRYPTO_GHASH=y
CONFIG_CRYPTO_MD4=y
CONFIG_CRYPTO_MD5=y
CONFIG_CRYPTO_MICHAEL_MIC=m
CONFIG_CRYPTO_RMD128=m
CONFIG_CRYPTO_RMD160=m
CONFIG_CRYPTO_RMD256=m
CONFIG_CRYPTO_RMD320=m
CONFIG_CRYPTO_SHA1=y
CONFIG_CRYPTO_SHA1_SSSE3=y
CONFIG_CRYPTO_SHA256=y
CONFIG_CRYPTO_SHA512=y
CONFIG_CRYPTO_TGR192=m
CONFIG_CRYPTO_WP512=m
CONFIG_CRYPTO_GHASH_CLMUL_NI_INTEL=m
CONFIG_CRYPTO_AES=y
CONFIG_CRYPTO_AES_X86_64=y
CONFIG_CRYPTO_AES_NI_INTEL=y
CONFIG_CRYPTO_ANUBIS=m
CONFIG_CRYPTO_ARC4=y
CONFIG_CRYPTO_BLOWFISH_COMMON=y
CONFIG_CRYPTO_BLOWFISH_X86_64=y
CONFIG_CRYPTO_CAMELLIA_X86_64=y
CONFIG_CRYPTO_CAST5=m
CONFIG_CRYPTO_CAST6=m
CONFIG_CRYPTO_DES=y
CONFIG_CRYPTO_FCRYPT=m
CONFIG_CRYPTO_KHAZAD=m
CONFIG_CRYPTO_SALSA20_X86_64=y
CONFIG_CRYPTO_SEED=m
CONFIG_CRYPTO_SERPENT=y
CONFIG_CRYPTO_SERPENT_SSE2_X86_64=y
CONFIG_CRYPTO_TEA=m
CONFIG_CRYPTO_TWOFISH_COMMON=y
CONFIG_CRYPTO_TWOFISH_X86_64=y
CONFIG_CRYPTO_TWOFISH_X86_64_3WAY=y
CONFIG_CRYPTO_DEFLATE=y
CONFIG_CRYPTO_ZLIB=y
CONFIG_CRYPTO_LZO=y
CONFIG_CRYPTO_ANSI_CPRNG=y
CONFIG_CRYPTO_USER_API=y
CONFIG_CRYPTO_USER_API_HASH=y
CONFIG_CRYPTO_USER_API_SKCIPHER=y
CONFIG_CRYPTO_HW=y
CONFIG_HAVE_KVM=y
CONFIG_HAVE_KVM_IRQCHIP=y
CONFIG_HAVE_KVM_EVENTFD=y
CONFIG_KVM_APIC_ARCHITECTURE=y
CONFIG_KVM_MMIO=y
CONFIG_KVM_ASYNC_PF=y
CONFIG_HAVE_KVM_MSI=y
CONFIG_VIRTUALIZATION=y
CONFIG_KVM=m
CONFIG_KVM_INTEL=m
CONFIG_KVM_MMU_AUDIT=y
CONFIG_VHOST_NET=m
CONFIG_BINARY_PRINTF=y
CONFIG_BITREVERSE=y
CONFIG_GENERIC_STRNCPY_FROM_USER=y
CONFIG_GENERIC_STRNLEN_USER=y
CONFIG_GENERIC_FIND_FIRST_BIT=y
CONFIG_GENERIC_PCI_IOMAP=y
CONFIG_GENERIC_IOMAP=y
CONFIG_GENERIC_IO=y
CONFIG_CRC_CCITT=y
CONFIG_CRC16=y
CONFIG_CRC_T10DIF=y
CONFIG_CRC_ITU_T=y
CONFIG_CRC32=y
CONFIG_CRC32_SELFTEST=y
CONFIG_CRC32_SLICEBY8=y
CONFIG_CRC7=y
CONFIG_LIBCRC32C=y
CONFIG_CRC8=y
CONFIG_ZLIB_INFLATE=y
CONFIG_ZLIB_DEFLATE=y
CONFIG_LZO_COMPRESS=y
CONFIG_LZO_DECOMPRESS=y
CONFIG_XZ_DEC=y
CONFIG_XZ_DEC_X86=y
CONFIG_XZ_DEC_POWERPC=y
CONFIG_XZ_DEC_IA64=y
CONFIG_XZ_DEC_ARM=y
CONFIG_XZ_DEC_ARMTHUMB=y
CONFIG_XZ_DEC_SPARC=y
CONFIG_XZ_DEC_BCJ=y
CONFIG_XZ_DEC_TEST=y
CONFIG_DECOMPRESS_GZIP=y
CONFIG_GENERIC_ALLOCATOR=y
CONFIG_TEXTSEARCH=y
CONFIG_TEXTSEARCH_KMP=m
CONFIG_TEXTSEARCH_BM=m
CONFIG_TEXTSEARCH_FSM=m
CONFIG_BTREE=y
CONFIG_HAS_IOMEM=y
CONFIG_HAS_IOPORT=y
CONFIG_HAS_DMA=y
CONFIG_CHECK_SIGNATURE=y
CONFIG_CPU_RMAP=y
CONFIG_DQL=y
CONFIG_NLATTR=y
CONFIG_AVERAGE=y
CONFIG_CORDIC=y
CONFIG_DDR=y
[/bash]
Toshset et toshiba_acpi
Grâce au travail de Charles Schwieters, on peut utiliser certaines fonctions (luminosité de l’écran, etc). Dans un premier temps, il faut patcher les sources du noyau.
Vous réccupérez le patch ici et vous avez un les sources (et même les binaires 32 et 64 bits) de toshset ici.
[bash]
cd /usr/src/linux
wget http://schwieters.org/toshset/toshiba_acpi-current.patch ~/toshiba_acpi-current.patch
patch -p1 < ~/toshiba_acpi-current.patch
[/bash]
Ensuite s’assurer d’avoir dans le fichier /mnt/work/.config les options suivantes:
[bash]
CONFIG_ACPI=y
CONFIG_ACPI_WMI=y
CONFIG_BACKLIGHT_CLASS_DEVICE=y
CONFIG_INPUT=y
CONFIG_RFKILL=y # ou pas de CONFIG_RFKILL
CONFIG_LEDS_CLASS=y
CONFIG_NEW_LEDS=y
CONFIG_INPUT_POLLDEV=y
CONFIG_INPUT_SPARSEKMAP=y
[/bash]
Vous pouvez retrouver ces valeurs dans le fichier /usr/src/linux/drivers/platform/x86/Kconfig .
Puis viennent les classiques:
[bash]
make O=/mnt/work && make O=/mnt/work modules_install
cp /mnt/work/{System.map,arch/x86/boot/bzImage} /boot/
[/bash]
n’oubliez pas de sauvegarder le fichier /mnt/work/.config car comme il est placé sur un système de fichier temporaire, il disparaîtra leur du prochain démontage de /mnt/work.
Le lecteur d’empreintes digitales
On installe la librairie libfprint , le module fprint pour pam:
[bash]
emerge -D libfprint pam_fprint
[/bash]
On va éditer le fichier /etc/pam.d/system-auth: Vous y rajoutez la ligne 2
[bash highlight=”2″]
auth required pam_env.so
auth sufficient pam_fprint.so
auth sufficient pam_unix.so try_first_pass likeauth nullok
auth required pam_deny.so
account required pam_unix.so
account optional pam_permit.so
password required pam_cracklib.so difok=2 minlen=8 dcredit=2 ocredit=2 retry=3
password required pam_unix.so try_first_pass use_authtok nullok sha512 shadow
password optional pam_permit.so
session required pam_limits.so
session required pam_env.so
session required pam_unix.so
session optional pam_permit.so
[/bash]
Enfin, on enregistre au moins une empreinte en tant qu’utilisateur normal:
[bash]
ulysse pam.d$ pam_fprint_enroll
This program will enroll your finger, unconditionally overwriting any selected print that was enrolled
previously. If you want to continue, press enter, otherwise hit Ctrl+C
Found device claimed by AuthenTec AES1660 driver
Opened device. It’s now time to enroll your finger.
You will need to successfully scan your Right Index Finger 1 times to complete the process.
Scan your finger now.
Enroll complete!
Enrollment completed!
[/bash]
Maintenant, à chaque fois que vous vous loguerez, il suffira de taper le login, la touche “Entrée” du clavier et
la machine vous demandera de lui montrez votre index.
Petit bonus supplémentaire que je viens de trouver sur le blog de Peter Senna Tschudin, ici: on devrait pouvoir étendre le système à 16G de mémoire (il cite par expl celle-ci: 2 * Patriot PSD38G13332S (8GB PC3 – 10600 1333MHz CL9 SoDimm)
MAJ: J’ai testé et ça fonctionne du tonnerre
Petits scripts
On a installé l’arborescence portage dans une archive squashfs. On ne pourra donc plus utiliser emerge –sync pour la mettre à jour. On va donc se servir d’un petit script qui va automatiser les tâches nécessaires: ~/update_portage
[bash]
cat > ~/update_portage << "EOF"
>#!/bin/bash
>
>REPOS=/usr/portage
>ARCHIVE=/var/portage/portage.sqsh
>
>if [ $(cat /proc/mounts | grep $REPOS | wc -l) -eq 1 ]; then umount $REPOS; fi
>mount -t tmpfs -o size=1G tmpfs $REPOS
>sleep 2
>emerge –sync > /dev/null 2>&1
>sleep 2
>mv $ARCHIVE{,.bak}
>mksquashfs $REPOS $ARCHIVE &&
>sleep 2
>rm ${ARCHIVE}.bak
>mount -o remount,ro $ARCHIVE $REPOS
>EOF
chmod o+x ~/update_portage
[/bash]
Sources:
Monday, 31 December 2012
FreeBSD 9.1 sur un MacBook Pro 1,2
DISCLAIMER: Cet article est le bloc note de mon installation d’un freebsd 9.1 sur un MacBook Pro version 1,2. Il va évoluer avec le temps. C’est mon premier contact avec la bête donc, j’adapterai au fur et à mesure certains détails (comme le shéma de partition).
TODO: (sans ordre particulier)
* lecteur de smartcard (couplé à gpg)
* Utilisation de GELI avec la smartcard
* Utilisation de la webcam
* Création d’un dump du disque avec une installation fraîche afin de pouvoir tout réinstaller d’un coup et mise à dispo de l’image
Ayant récupéré un macbook pro version 1,2 je me suis mis en devoir de le libérer de son os initial sale. Le passage aux *BSD me démangeant de plus en plus, c’était donc l’occasion de le faire.
Pour les spécifications de ce mac, on va ici: www.everymac.com
Ici, on a la description du proc: ark.intel.com on y voit que c’est un 32 bits.
L’organisation du système de fichier sera le suivant:
* 10 Go pour / (racine)
* 4 Go pour le swap
* 10 Go pour /var
* 30 Go pour /home
* 30 Go pour /usr
* 10 Go pour /jails
Pour /tmp, on utilisera tmpfs.
Pour info, vous avez cette page: hier(7) qui décrit la hiérarchie standard du système de fichiers sur FreeBSD.
Dans un premier temps, on va sur ftp://ftp.freebsd.org/pub/FreeBSD/releases/i386/i386/ISO-IMAGES/ récupérer une image à graver sur une galette (J’ai pris la version 9.1) et l’on va booter dessus.
Puis on va suivre l’installation classique. On choisit un schéma de clavier Français macbook pro + ISO8859-15.
On lance la partition du disque, là j’ai dû choisir un schéma BSD classique et non le GPT.
J’ai rajouté aussi les sources dans la liste des packages à récupérer.
On demande aussi le démarrage de moused, ntpd, sshd et powerd
Une fois l’install terminée, on va demander un shell et éditer /etc/fstab:
On crypte la swap et on rajoute /tmp et /cdrom.
[bash]
vi /etc/fstab
Device Mountpoint FStype Options Dump Pass
/dev/ada0b.eli none swap sw 0 0
tmpfs /tmp tmpfs rw,mode=777 0 0
/dev/cd0 /cdrom cd9660 ro,noauto,users 0 0
[/bash]
On en profite aussi pour créer /cdrom et enfin on adapte le paramétrage à une utilisation desktop (l’optimisation par défaut est celle d’un serveur).
[bash]
echo "kern.sched.preempt_thresh=224" >> /etc/sysctl.conf
[/bash]
on reboot et on va tuner le bouzin.
On change le cryptage des mots de passe:
Dans /etc/login.conf on remplace:
[bash]:passwd_format=sha512:[/bash]
par
[bash]:passwd_format=blf:[/bash]
On en profite aussi pour créer une classe afin de localiser en français le clavier et le mettre en UTF-8:
[bash]
french|French Users Accounts:\
:charset=UTF-8:\
:lang=fr_FR.UTF-8:\
:tc=default:[/bash]
puis, on reconstruit la base:
[bash]cap_mkdb /etc/login.conf[/bash]
On lance vipw et on rajoute le nom de la classe ‘french’ sur la ligne de votre utilisateur (entre les :: qui se trouvent après son gid).
enfin on fait
[bash]echo "defaultclass = french" >> /etc/adduser.conf[/bash]
et on change les mots de passe des utilisateurs.
On configure /etc/make.conf:
[bash]cp /usr/share/examples/etc/make.conf /etc/[/bash]
et vous appliquez les options qui vous conviennent.
On va s’occuper des ports:
Pour les récupérer, on a plusieurs solutions possibles. Pour ma part j’ai opté pour subversion.
On va donc l’installer
[bash]
cd /usr/ports/devel/subversion
make install clean
[/bash]
Puis, on met à jour
[bash]
cd /usr/ports
svn update
[/bash]
On installe les vérifications de sécurité:
[bash]
cd ports-mgmt/portaudit
make install clean
portaudit -Fa
[/bash]
Pour portaudit, l’option F récupère la base de données des vulnérabilités et le ‘a’ va tester le tout.
Maintenant, on va s’occuper du pare-feu:
Ici on va utiliser pf (PacketFilter le fieroualle d’OpenBSD) et pflog pour les logs:
on rajoutes donc dans /etc/rc.conf
[bash]
pf_enable="YES"
pf_rules="/etc/pf.conf"
pflog_enable="YES"
[/bash]
Puis le pf.conf: (Ici je fais dans le grossier, je bloque tout en entrée et n’autorise que les sorties).
[bash]
ifaces = "{(msk0), (ath0)}"
set skip on lo
scrub in all
block all
pass out inet proto tcp from $ifaces to any flags S/SA keep state
pass out inet proto {udp, icmp} from $ifaces to any keep state
[/bash]
Afin de pouvoir accéder aux différents senseurs et illuminer son clavier, on va utiliser asmc.
On va donc devoir recompiler le noyau afin d’en profiter.
[bash]
cd /usr/src/sys/i386/conf
mkdir /root/kernels
cp GENERIC /root/kernels/MACKERNEL
ln -s /root/kernels/MACKERNEL
echo "device asmc" >> ./MACKERNEL
cd /usr/src
make buildkernel KERNCONF=MACKERNEL
make installkernel KERNCONF=MACKERNEL
[/bash]
Puis on reboot.
A partir de ce moment, tout ce qui concerne les senseurs est accessible via:
[bash]
sysctl dev.asmc.0
[/bash]
Voici le résultat chez moi:
[bash collapse=”true”]
dev.asmc.0.%desc: Apple SMC MacBook Pro Core Duo (17-inch)
dev.asmc.0.%driver: asmc
dev.asmc.0.%location: handle=\_SB_.PCI0.LPCB.SMC_
dev.asmc.0.%pnpinfo: _HID=APP0001 _UID=0
dev.asmc.0.%parent: acpi0
dev.asmc.0.fan.0.speed: 1047
dev.asmc.0.fan.0.safespeed: 1200
dev.asmc.0.fan.0.minspeed: 1000
dev.asmc.0.fan.0.maxspeed: 5500
dev.asmc.0.fan.0.targetspeed: 1045
dev.asmc.0.fan.1.speed: 1047
dev.asmc.0.fan.1.safespeed: 1200
dev.asmc.0.fan.1.minspeed: 1000
dev.asmc.0.fan.1.maxspeed: 5500
dev.asmc.0.fan.1.targetspeed: 1045
dev.asmc.0.temp.enclosure: 34
dev.asmc.0.temp.heatsink1: 51
dev.asmc.0.temp.heatsink2: 45
dev.asmc.0.temp.memory: 52
dev.asmc.0.temp.graphics: 62
dev.asmc.0.temp.graphicssink: 58
dev.asmc.0.temp.unknown: 66
dev.asmc.0.light.left: 10
dev.asmc.0.light.right: 32
dev.asmc.0.light.control: 127
dev.asmc.0.sms.x: -33
dev.asmc.0.sms.y: -11
dev.asmc.0.sms.z: 211
[/bash]
Pour profiter de la mise en pose du disque lors d’un mouvement brusque, on va se servir de ataidle:
[bash]
cd /usr/ports/sysutils/ataidle
make install clean
[/bash]
puis
On rajoute dans /etc/devd.conf:
[bash]
notify 0 {
match "system" "ACPI";
match "subsystem" "asmc";
action "/usr/local/sbin/ataidle -s /dev/ad5";
};
[/bash]
Le clavier:
Pour le rétro-éclairage du clavier, on fait (vous pouvez mettre n’importe quelle valeur entre 0 et 255):
[bash]
echo "dev.asmc.0.light.control=127" >> /etc/sysctl.conf
[/bash]
On va aussi activer le bouton d’éjection du lecteur de cd/dvd. Pour ceci, on fait:
[bash]
echo "Consumer:Consumer_Control.Consumer:Eject 1 0 umount /cdrom && cdcontrol eject" > /etc/usbhidaction.uhid0
echo "/usr/bin/usbhidaction -f /dev/uhid0 -c /etc/usbhidaction.uhid0" >> /etc.rc.local
[/bash]
Le clavier d’office fournit: fr.macbookpro.acc.kbd contient une inversion des touches “@#” et “<>”. Une personne à fait
une rectification qui permet de résoudre le soucis. Le nouveau fichier est sur son site: http://www.lamaiziere.net/mbp_freebsd.html.
On sauvegarde l’ancien au cas où et on le remplace par le nouveau:
[bash]
wget http://www.lamaiziere.net/fr.macbookpro.acc.kbd
mv /usr/src/share/syscons/keymaps/fr.macbook.acc.kbd /usr/src/share/syscons/keymaps/fr.macbook.acc.kbd.bak
cp ./fr.macbookpro.acc.kbd /usr/src/share/syscons/keymaps/fr.macbook.acc.kbd
[/bash]
Ceci dit je n’ai pas réussit à le faire fonctionner…
On va installer maintenant Xorg:
[bash]
cd /usr/ports/x11/xorg
make install clean
cd ~
Xorg -configure
[/bash]
Ceci nous donnera une ébauche de fichier de Xorg. On va l’éditer et le compléter:
[bash collapse=”true”]
Section "ServerLayout"
Identifier "X.org Configured"
Screen 0 "Screen0" 0 0
InputDevice "Mouse0" "CorePointer"
InputDevice "Keyboard0" "CoreKeyboard"
Option "AutoAddDevices" "false"
Option "AIGLX" "true"
EndSection
Section "Extensions"
Option "Composite" "Enable"
EndSection
Section "Files"
ModulePath "/usr/local/lib/xorg/modules"
FontPath "/usr/local/lib/X11/fonts/misc/"
FontPath "/usr/local/lib/X11/fonts/TTF/"
FontPath "/usr/local/lib/X11/fonts/OTF"
FontPath "/usr/local/lib/X11/fonts/Type1/"
FontPath "/usr/local/lib/X11/fonts/100dpi/"
FontPath "/usr/local/lib/X11/fonts/75dpi/"
EndSection
Section "Module"
Load "extmod"
Load "freetype"
Load "record"
Load "dbe"
Load "dri"
Load "dri2"
Load "glx"
EndSection
Section "InputDevice"
Identifier "Keyboard0"
Option "XkbRules" "xorg"
Option "XkbModel" "macbook79"
Option "XkbLayout" "fr"
Driver "kbd"
EndSection
Section "InputDevice"
Identifier "Mouse0"
Driver "mouse"
Option "Protocol" "auto"
Option "Device" "/dev/sysmouse"
Option "ZAxisMapping" "4 5 6 7"
EndSection
Section "Monitor"
Identifier "Monitor0"
VendorName "APP"
ModelName "Color LCD"
EndSection
Section "Device"
Option "NoAccel" "false"
Option "AccelMethod" "EXA"
Option "DRI" "true"
Identifier "Card0"
Driver "radeon"
VendorName "Advanced Micro Devices [AMD] nee ATI"
BoardName "M56P [Radeon Mobility X1600]"
BusID "PCI:1:0:0"
EndSection
Section "Screen"
Identifier "Screen0"
Device "Card0"
Monitor "Monitor0"
SubSection "Display"
Viewport 0 0
Depth 1
EndSubSection
SubSection "Display"
Viewport 0 0
Depth 4
EndSubSection
SubSection "Display"
Viewport 0 0
Depth 8
EndSubSection
SubSection "Display"
Viewport 0 0
Depth 15
EndSubSection
SubSection "Display"
Viewport 0 0
Depth 16
EndSubSection
SubSection "Display"
Viewport 0 0
Depth 24
EndSubSection
EndSection
[/bash]
Pour avoir la bonne configuration de clavier sous Xorg, il va falloir remplacer le fichier de map:
[bash]
wget http://bersace03.free.fr/pub/Development/Linux/xkb-mac/fr.ancien fr
mv /usr/local/share/X11/xkb/symbols/macintosh_vndr/fr /usr/local/share/X11/xkb/symbols/macintosh_vndr/fr.bak
cp fr /usr/local/share/X11/xkb/symbols/macintosh_vndr/
[/bash]
Pour le trackpad, on va utiliser le driver atp, pour ça on va devoir recompiler notre noyau:
[bash]
echo "device atp" >> /root/kernels/MACKERNEL
cd /usr/src
make buildkernel KERNCONF=MACKERNEL
make installkernel KERNCONF=MACKERNEL
[/bash]
Puis on reboot.
On modifie /etc/rc.conf
[bash]
moused_enable="YES"
moused_type="auto"
moused_port="/dev/atp0"
moused_nondefault_enable="YES"
moused_ums0_enable="YES"
moused_ums1_enable="YES"
[/bash]
Pour que le trackpad fonctionne pour tous les utilisateurs, j’ai dû rajouter une ligne dans /etc/devfs.conf
[bash]
echo "perm /dev/sysmouse 0666" >> /etc/devfs.conf
[/bash]
Il nous reste le window manager, on va utiliser fluxbox:
[bash]
cd /usr/ports/x11-wm/fluxbox
make install clean
echo "exec startfluxbox" > ~/.xinitrc
[/bash]
On va avoir besoin d’un fichier “startup” dans ~/.fluxbox/ qui contiendra tout ce que l’on veut lancer directement avec fluxbox
[bash]
touch ~/.fluxbox/startup
[/bash]
un simple startx devrait maintenant vous montrer une belle interface graphique aussi simple qu’efficace.
Pour fixer un fond d’écran, on va utiliser feh:
[bash]
cd /usr/ports/graphics/feh
make install clean
[/bash]
On va créer un répertoire dans .fluxbox pour stocker les images de fond:
[bash]
mkdir ~/.fluxbox/backgrounds
[/bash]
et on y dépose des images
On rajoute conky histoire d’afficher des infos sur le système plus d’autres trucs utils:
[bash]
cd /usr/ports/sysutil/conky
make install clean
[/bash]
Enfin, on configure conky. Pour ça, on va éditer le fichier .conkyrc et y mettre ce contenu:
[bash collapse=”true”]
use_xft yes
xftfont DejaVu Sans Mono:size=10:style=Bold
xftalpha 0.8
update_interval 2.0
total_run_times 0
own_window no
own_window_type normal
own_window_transparent yes
minimum_size 280 5
draw_shades no
draw_outline no
draw_borders no
draw_graph_borders no
stippled_borders 8
border_inner_margin 4
border_width 1
default_color white
default_shade_color black
default_outline_color black
alignment top_left
gap_x 12
gap_y 12
no_buffers yes
uppercase no
cpu_avg_samples 1
net_avg_samples 1
use_spacer none
override_utf8_locale yes
TEXT
${color green} $nodename – $sysname $kernel on $machine
$time$color
$hr
${color green}Uptime:$color $uptime – Load:$color $loadavg
${color green}Coeur 1:$color ${freq cpu0} Mhz ${color red}${cpu cpu0}% ${cpubar cpu0}
${color green}Coeur 2:$color ${freq cpu1} Mhz ${color red}${cpu cpu1}% ${cpubar cpu1}
${color green}RAM:$color $mem/$memmax – ${color red}$memperc% ${membar 4}
${color green}Pagination:$color $swap/$swapmax – ${color red}$swapperc% ${swapbar 4}
${color green}Batterie: $color$battery_time h ${color blue}${battery_bar 5 0}
${color green}Ventilateurs: 1:$color${exec sysctl dev.asmc.0.fan.0.speed | awk ‘{FS=":"}{ print $2 }’} TPM${color green} 2:$color${exec sysctl dev.asmc.0.fan.1.speed | awk ‘{FS=":"}{ print $2 }’} TPM
${color green}Luminosité: gauche:$color${exec sysctl dev.asmc.0.light.left | awk ‘{FS=":"}{ print $2 }’}${color green} droite:$color${exec sysctl dev.asmc.0.light.right | awk ‘{FS=":"}{ print $2 }’}
$color$stippled_hr
${color green}Températures:
Coeur 1:$color${exec sysctl dev.cpu.0.temperature | awk ‘{FS=":"}{ print $2 }’}${color green} Coeur 2:$color${exec sysctl dev.cpu.1.temperature | awk ‘{FS=":"}{ print $2 }’}
${color green} GPU:$color${exec sysctl dev.asmc.0.temp.graphics | awk ‘{FS=":"}{ print $2 }’},0C${color green} Mémoire:$color${exec sysctl dev.asmc.0.temp.memory | awk ‘{FS=":"}{ print $2 }’},0C
${color green} Rad. 1: $color${exec sysctl dev.asmc.0.temp.heatsink1 | awk ‘{FS=":"}{ print $2 }’},0C${color green} Rad. 2:$color${exec sysctl dev.asmc.0.temp.heatsink2 | awk ‘{FS=":"}{ print $2 }’},0C
${color green} Chassis:$color${exec sysctl dev.asmc.0.temp.enclosure | awk ‘{FS=":"}{ print $2 }’},0C
$color$stippled_hr
${color green}Reseau:
Passerelle: $color${exec netstat -r | grep default | awk ‘{print $2}’}
${if_up msk0}
${color green}Filaire: $color${addr msk0}
${color green}Montee:$color ${upspeed msk0} ${color green}${offset 150}Descente:$color ${downspeed msk0}
${upspeedgraph msk0 32,200 ff0000 0000ff -t -l}${downspeedgraph msk0 32,150 ff0000 0000ff -t -l}
$endif
${if_up ath0}
${color green}Wifi: $color${addr ath0}
${color green}Montee:$color ${upspeed ath0} ${color green} – Descente:$color ${downspeed ath0}
${upspeedgraph ath0 32,200 ff0000 0000ff -t -l}${downspeedgraph ath0 32,200 ff0000 0000ff -t -l}
$endif
$color$stippled_hr
${color green}Systeme de fichiers:
$color / ${goto 80}${fs_type /} ${color blue}${fs_used /}/${fs_size /} ${fs_bar 6 /}
$color /usr ${goto 80}${fs_type /usr} ${color blue}${fs_used /usr}/${fs_size /usr} ${fs_bar 6 /usr}
$color /var ${goto 80}${fs_type /var} ${color blue}${fs_used /var}/${fs_size /var} ${fs_bar 6 /var}
$color /tmp ${goto 80}${fs_type /tmp} ${color blue}${fs_used /tmp}/${fs_size /tmp} ${fs_bar 6 /tmp}
$color /home ${goto 80}${fs_type /home} ${color blue}${fs_used /home}/${fs_size /home} ${fs_bar 6 /home}
$color$stippled_hr
${color green}Processes:$color $processes ${color green}Running:$color $running_processes
${color green}Name PID CPU % MEM %
${color}${top name 1} ${top pid 1} ${top cpu 1} ${top mem 1}
${color}${top name 2} ${top pid 2} ${top cpu 2} ${top mem 2}
${color}${top name 3} ${top pid 3} ${top cpu 3} ${top mem 3}
${color}${top name 4} ${top pid 4} ${top cpu 4} ${top mem 4}
[/bash]
~/.fluxbox/startup devient:
[bash]
exec conky &
exec feh –bg-center /home/dervishe/.fluxbox/backgrounds/MON_IMAGE_DE_FOND &
exec fluxbox
[/bash]
Finalement, voici ce que ça donne:

Ressources:
Fichier de conf du noyau:
[bash collapse=”true”]
cpu I686_CPU
ident MACKERNEL
options SCHED_ULE # ULE scheduler
options PREEMPTION # Enable kernel thread preemption
options INET # InterNETworking
options INET6 # IPv6 communications protocols
options SCTP # Stream Control Transmission Protocol
options FFS # Berkeley Fast Filesystem
options SOFTUPDATES # Enable FFS soft updates support
options UFS_ACL # Support for access control lists
options UFS_DIRHASH # Improve performance on big directories
options UFS_GJOURNAL # Enable gjournal-based UFS journaling
options MD_ROOT # MD is a potential root device
options NFSCL # New Network Filesystem Client
options NFSD # New Network Filesystem Server
options NFSLOCKD # Network Lock Manager
options NFS_ROOT # NFS usable as /, requires NFSCL
options MSDOSFS # MSDOS Filesystem
options CD9660 # ISO 9660 Filesystem
options PROCFS # Process filesystem (requires PSEUDOFS)
options PSEUDOFS # Pseudo-filesystem framework
options GEOM_PART_GPT # GUID Partition Tables.
options GEOM_RAID # Soft RAID functionality.
options GEOM_LABEL # Provides labelization
options COMPAT_FREEBSD4 # Compatible with FreeBSD4
options COMPAT_FREEBSD5 # Compatible with FreeBSD5
options COMPAT_FREEBSD6 # Compatible with FreeBSD6
options COMPAT_FREEBSD7 # Compatible with FreeBSD7
options SCSI_DELAY=5000 # Delay (in ms) before probing SCSI
options KTRACE # ktrace(1) support
options STACK # stack(9) support
options SYSVSHM # SYSV-style shared memory
options SYSVMSG # SYSV-style message queues
options SYSVSEM # SYSV-style semaphores
options _KPOSIX_PRIORITY_SCHEDULING # POSIX P1003_1B real-time extensions
options PRINTF_BUFR_SIZE=128 # Prevent printf output being interspersed.
options KBD_INSTALL_CDEV # install a CDEV entry in /dev
options HWPMC_HOOKS # Necessary kernel hooks for hwpmc(4)
options AUDIT # Security event auditing
options MAC # TrustedBSD MAC Framework
options INCLUDE_CONFIG_FILE # Include this file in kernel
options KDB # Kernel debugger related code
options KDB_TRACE # Print a stack trace for a panic
options SMP # Symmetric MultiProcessor Kernel
device apic # I/O APIC
device cpufreq
device acpi
device eisa
device pci
device ahci # AHCI-compatible SATA controllers
device ata # Legacy ATA/SATA controllers
options ATA_CAM # Handle legacy controllers with CAM
options ATA_STATIC_ID # Static device numbering
options AHD_REG_PRETTY_PRINT # Print register bitfields in debug
device scbus # SCSI bus (required for ATA/SCSI)
device ch # SCSI media changers
device da # Direct Access (disks)
device sa # Sequential Access (tape etc)
device cd # CD
device pass # Passthrough device (direct ATA/SCSI access)
device ses # Enclosure Services (SES and SAF-TE)
device ctl # CAM Target Layer
device vga # VGA video card driver
options VESA # Add support for VESA BIOS Extensions (VBE)
device splash # Splash screen and screen saver support
device sc
options SC_PIXEL_MODE # add support for the raster text mode
device agp # support several AGP chipsets
device pmtimer
device cbb # cardbus (yenta) bridge
device uart # Generic UART driver
device ppc
device ppbus # Parallel port bus (required)
device lpt # Printer
device plip # TCP/IP over parallel
device ppi # Parallel port interface device
device puc # Multi I/O cards and multi-channel UARTs
device miibus # MII bus support
device msk # Marvell/SysKonnect Yukon II Gigabit Ethernet
device wlan # 802.11 support
options IEEE80211_DEBUG # enable debug msgs
options IEEE80211_AMPDU_AGE # age frames in AMPDU reorder q’s
options IEEE80211_SUPPORT_MESH # enable 802.11s draft support
device wlan_wep # 802.11 WEP support
device wlan_ccmp # 802.11 CCMP support
device wlan_tkip # 802.11 TKIP support
device wlan_amrr # AMRR transmit rate control algorithm
device ath # Atheros NIC’s
device ath_pci # Atheros pci/cardbus glue
device ath_hal # pci/cardbus chip support
options AH_SUPPORT_AR5416 # enable AR5416 tx/rx descriptors
device ath_rate_sample # SampleRate tx rate control for ath
device loop # Network loopback
device random # Entropy device
device ether # Ethernet support
device vlan # 802.1Q VLAN support
device tun # Packet tunnel.
device pty # BSD-style compatibility pseudo ttys
device md # Memory "disks"
device gif # IPv6 and IPv4 tunneling
device faith # IPv6-to-IPv4 relaying (translation)
device firmware # firmware assist module
device bpf # Berkeley packet filter
options USB_DEBUG # enable debug msgs
device uhci # UHCI PCI->USB interface
device ohci # OHCI PCI->USB interface
device ehci # EHCI PCI->USB interface (USB 2.0)
device usb # USB Bus (required)
device uhid # "Human Interface Devices"
device ukbd # Keyboard
device ulpt # Printer
device umass # Disks/Mass storage – Requires scbus and da
device ums # Mouse
device firewire # FireWire bus code
device fwe # Ethernet over FireWire (non-standard!)
device fwip # IP over FireWire (RFC 2734,3146)
device dcons # Dumb console driver
device dcons_crom # Configuration ROM for dcons
device sound # Generic sound driver (required)
device snd_hda # Intel High Definition Audio
device asmc
device atp
[/bash]
Les deux sources principales correspondant à l’installation sont: la doc officielle et les pages man des commandes ou autres (on y trouve des indications très précieuses  )
)
== Non classées ==
http://olivier.cochard.me/bidouillage/installation-et-configuration-de-freebsd-comme-poste-de-travail
http://wiki.freebsd.org/AppleMacbook
https://help.ubuntu.com/community/MactelSupportTeam/AppleIntelInstallation (problème du délai avant le boot freebsd)
http://www.freebsd.org/doc/en_US.ISO8859-1/books/handbook/kernelconfig-building.html
http://www.unix.com/man-page/FreeBSD/4/asmc/
http://howtounix.info/man/FreeBSD/man4/atp.4
https://cooltrainer.org/2012/01/02/a-freebsd-9-desktop-how-to/
http://blog.hplogsdon.com/tuning-freebsd-for-apple-hardware/
http://bersace03.free.fr/pub/Development/Linux/xkb-mac/
== Sécurisation ==
http://skreuzer.pbworks.com/w/page/6627216/FreeBSD
http://www.roe.ch/FreeBSD_Contributions
http://www.freebsd.org/cgi/man.cgi?query=geli&sektion=8
http://www.freebsd.org/doc/en_US.ISO8859-1/books/handbook/disks-encrypting.html
http://www.gooze.eu/howto/smartcard-quickstarter-guide/freebsd-installation
http://www.freebsd.org/doc/en_US.ISO8859-1/books/handbook/firewalls-pf.html
Thursday, 27 September 2012
Un environnement de développement PHP avec Vim
Dans cet article, on va mettre en place un environnement de développement pour le web assez léger et complet avec que des bonnes choses libres dedans.
1/ L’édition
On va utiliser vim. Dans un premier temps, on l’installe donc.
Chez moi: emerge -uD vim
On active la numérotation des lignes et les replis en ajoutant ceci à votre ~/.vimrc :
[bash]
:set number
:set foldmethod=marker
[/bash]
La seconde ligne permet d’activer le replis dans les fichiers. Pour ceci, vous devez ajouter en commentaire au début de votre fichier, l’entrée:
[bash]
vim: foldmarker MARKER_DEBUT,MARKER_FIN
[/bash]
Remplacez MARKER_DEBUT et MARKER_FIN par ce que vous souhaitez (du genre ‘{{{‘ et ‘}}}’). Il vous suffit après de délimiter vos blocs avec ces deux marqueurs. Un petit z-o pour ouvrir le bloc et z-c pour le fermer.
Puis phpdoc:
Le greffon PDV (PhpDocumentor for Vim) permet d’ajouter rapidement des commentaires et tags phpdoc dans vos scripts.
Une fois celui-ci installé, il vous faudra modifier votre fichier ~/.vimrc en lui ajoutant les lignes suivantes:
[bash]
source ~/.vim/plugin/php-doc.vim
imap <C-o> <ESC>:set paste<CR>:call PhpDoc()<CR>:set nopaste<CR>
[/bash]
Après ceci, un petit CTRL+o en mode édition ajoutera un bloc commentaire avec des infos à compléter.
Puis l’auto-complétion des commandes:
Téléchargez le greffon ici puis on met fichier dans ~/.vim/plugin/
Téléchargez le second greffon ici puis on met fichier dans ~/.vim/autoload/
Récupérez aussi le fichier contenant la liste des commandes php ici et on le place dans ~/.vim/syntax/
Toujours dans le ~/.vimrc on ajoute:
[bash]
set complete=.,w,b,u,t,i,k~/.vim/syntax/php.api
autocmd FileType php set omnifunc=phpcomplete#CompletePHP
source ~/.vim/plugin/word_complete.vim
call DoWordComplete()
[/bash]
On va enfin modifier la configuration de ~/.vim/plugin/word_complete.vim pour mettre l’auto-complétion avec une chaîne d’au moins 3 caractères:
[bash highlight=”49,51″ firstline=”44″]
" ==================== file word_complete.vimrc ====================
" User Configuration file for word_complete.vim .
" To use this, uncomment and change the defaults.
" Do not complete words shorter than this length:
let g:WC_min_len = 3
" Use this key to accept the offered completion:
let g:WC_accept_key = "<Tab>"
" ==================== end: word_complete.vimrc ====================
[/bash]
La seconde ligne surlignée vous permet de changer la touche d’acceptation de la complétion.
Puis la coloration syntaxique:
Ajoutez dans votre ~/.vimrc ceci:
[bash]
syntax on
filetype on
[/bash]
La seconde ligne active la détection des types de fichiers.
Vous pouvez mettre à jour la coloration syntaxique avec la version php 5.3 via ce lien. Dans l’archive, il y a un script php à exécuter en ligne de commande qui vous permettra de mettre à jours vous-même le-dit fichier.
Enfin la vérification de votre code avec php:
Ici, on va redéfinir la commande makeprg (make programme) de vim pour la faire pointer vers la version cli de php avec l’option -l:
[bash]
set makeprg=/usr/lib64/php5.4/bin/php\ -l\ %
nmap <F9> :make<ENTER>:copen<ENTER><CTRL>L
[/bash]
Maintenant à chaque fois que vous utiliserez la touche F9, cela déclenchera php -l sur votre fichier en cours d’édition
2/ Le Débogage
Pour le débogage sous PHP on a le choix de le faire à grands coups de var_dump() (qui devient vite pénible) ou d’utiliser une extension de PHP xdebug. Celle-ci s’installe donc sur le serveur et se déclenche automatiquement (selon sa configuration) lorsque le serveur reçoit une requête http avec le paramètre XDEBUG_SESSION_START=1.
* PHP
L’installation se fait de la manière la plus simple avec un petit:
[bash]
pecl install xdebug
[/bash]
Si vous voulez une installation plus spécifique: installation xdebug
Après vous ajoutez cette ligne à votre php.ini:
zend_extension=”/usr/local/php/modules/xdebug.so”
Et vous devez paramétrer le fichier de configuration de xdebug (chez moi: /etc/php/apache2-php5.4/xdebug.ini). Le miens ressemble à ça:
[bash highlight=”1,3,29-32,35-40″]
zend_extension=/usr/lib64/php5.4/lib/extensions/no-debug-zts-20100525/xdebug.so
xdebug.auto_trace="1"
xdebug.trace_output_dir="/dir_Traces"
xdebug.trace_output_name="trace.%c"
xdebug.trace_format="0"
xdebug.trace_options="0"
xdebug.collect_includes="1"
xdebug.collect_params="0"
xdebug.collect_return="0"
xdebug.collect_vars="0"
xdebug.default_enable="0"
xdebug.extended_info="1"
xdebug.manual_url="http://www.php.net"
xdebug.max_nesting_level="100"
xdebug.show_exception_trace="0"
xdebug.show_local_vars="0"
xdebug.show_mem_delta="0"
xdebug.dump.COOKIE="NULL"
xdebug.dump.ENV="NULL"
xdebug.dump.FILES="NULL"
xdebug.dump.GET="NULL"
xdebug.dump.POST="NULL"
xdebug.dump.REQUEST="NULL"
xdebug.dump.SERVER="NULL"
xdebug.dump.SESSION="NULL"
xdebug.dump_globals="1"
xdebug.dump_once="1"
xdebug.dump_undefined="0"
xdebug.profiler_enable="0"
xdebug.profiler_output_dir="/dir_Profiles"
xdebug.profiler_output_name="callgrind.out.%p"
xdebug.profiler_enable_trigger="1"
xdebug.profiler_append="1"
xdebug.profiler_aggregate="0"
xdebug.remote_enable="1"
xdebug.remote_handler="dbgp"
xdebug.remote_host="localhost"
xdebug.remote_mode="req"
xdebug.remote_port="9000"
xdebug.remote_autostart="0"
xdebug.remote_log=""
xdebug.idekey=""
xdebug.var_display_max_data="512"
xdebug.var_display_max_depth="2"
xdebug.var_display_max_children="128"
[/bash]
J’ai surligné les lignes importantes. Évidemment, vous devez adapter les paramètres à votre système (du genre dir_Profiles et dir_Traces).
* vim
Pour utiliser xdebug avec vim, vous devez installer le greffon suivant: dbgp remote debugger.
Pour cela vous copiez les fichiers debugger.py et debugger.vim de l’archive dans votre répertoire: ~/.vim/plugin/
Une fois le greffon installé, il vous suffira d’appuyer sur F5 dans vim et vous aurez 10 secondes pour lancer votre requête http dans votre navigateur.
Pour ce faire, vous avez deux possibilités:
Passer un paramètre à la requête: http://adresse_du_site?XDEBUG_SESSION_START=1 ou
si vous utilisez firefox, celui-ci possède une extension bien pratique dans notre cas: easy xdebug. Celle-ci permet de déclencher le débogage à distance et le profilage de vos scripts via l’appuie sur deux boutons.
Une fois le débogueur lancé, F2 vous amène à l’instruction suivante, F3 vous fait sauter au bloc suivant, F12 vous donne le contenu de la variable sur laquelle se trouve votre curseur et F5 vous amène au point d’arrêt suivant ou à la fin du script.
:Bp permet d’ajouter ou d’ôter des points d’arrêt.
3/ Le profilage
* Qcachegrind
Qcachegrind est une partie du projet KCachegrind que vous trouverez ici.
L’installation se fait très facilement.
Dans un premier temps, vous téléchargez les sources de KCachegrind, décompressez l’archive. Puis vous vous rendez dans le sous-répertoire qcachegrind et vous tapez:
[bash]
qmake
make
[/bash]
Si tout se passe bien vous devriez obtenir un binaire qcachegrind dans le-dit répertoire.
Il suffira ensuite de lancer l’application et d’ouvrir avec les fichier callgrind générés par xdebug (Cf la configuration de xdebug plus haut, ligne 31).
Voici à quoi cela ressemble:

4/ Goodies
* pdepend est un petit logiciel qui permet de faire de la métrologie logicielle. Il vous sortira des graphiques exprimant un certain nombre de mesures (comme le nombre total d’appel de méthodes, le nombre de classes ou encore la complexité cyclomatique du code) au format svg.
Pour l’installer il faut passer par PEAR.
[bash]
pear channel-discover pear.pdepend.org
pear install pdepend/PHP_Depend
[/bash]
Pour générer les graphiques tapez:
[bash]
pdepend –overview-pyramid=./graphique-pyramide.svg –jdepend-chart=./diagramme-dep.svg ./arborescence-du-code
[/bash]
Ceci vous créera deux images svg.
Voici le type de diagrammes que vous obtiendrez:


* Dia est un logiciel qui permet de faire des diagrammes et schémas. Il possède notamment une librairie UML permettant de faire tous vos diagrammes de classes, et autres.
Autre intérêt et non des moindres, on peut installer un greffon qui se nomme uml2php5 qui permet d’exporter directement vos schémas de classes sous formes de squelettes php
(et ceci est paramétrable en plus!).
Pour l’installation de dia, reportez-vous à votre distribution.
Voici une image de l’interface:

Après, on va installer uml2php5: Allez ici et téléchargez le paquet. Les instructions d’installation sont relativement claires.
En rapide, il suffit de décompresser l’archives et de copier 5 fichiers (stylesheet.xml, dia-uml-classes.zx, dia-uml2php5.zx, dia-uml2phpsoap.zx et dia-uml2php5.conf.xsl) dans le répertoire de dia contenant les spécifications des greffons, chez, moi il se trouve ici: /usr/share/dia/xslt
Le fichier de configuration de uml2php5 est: dia-uml2php5.conf.xsl
[html collapse=”true”]
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<!–
Parameter : INDENT_STR
Values : [TAB] or SPACE CHAR(s)
Comment : if you want you can replace [TAB] with [SPACE] char(s)
–>
<xsl:param name="INDENT_STR"><xsl:text> </xsl:text></xsl:param>
<!–
Parameter : CLOSE_TAG
Values : ON / OFF
Comment : if you want source code ended or not by ‘?>’
–>
<xsl:param name="CLOSE_TAG">ON</xsl:param>
<!–
Parameter : CLASS_FILE_EXTENSION
Values : .class.php / whatever you want
Comment : define file extension for classes
–>
<xsl:param name="CLASS_FILE_EXTENSION">.class.php</xsl:param>
<!–
Parameter : INTERFACE_FILE_EXTENSION
Values : .interface.php / whatever you want
Comment : define file extension for interfaces
–>
<xsl:param name="INTERFACE_FILE_EXTENSION">.interface.php</xsl:param>
<!–
Parameter : GENERATE_DOC_TAGS
Values : ON / OFF
Comment : if you want document your source code or not
–>
<xsl:param name="GENERATE_DOC_TAGS">ON</xsl:param>
<!–
Parameter : COMPOSITION_IMPLICIT_NAMING
Values : ON / OFF
Comment : generate or not composition attribute if role is missing
–>
<xsl:param name="COMPOSITION_IMPLICIT_NAMING">ON</xsl:param>
<!–
Parameter : AGGREGATION_IMPLICIT_NAMING
Values : ON / OFF
Comment : generate or not aggregation attribute and method
–>
<xsl:param name="AGGREGATION_IMPLICIT_NAMING">ON</xsl:param>
<!–
Parameter : AUTO_EXPAND_INTERFACES
Values : ON / OFF
Comment : generate interface methods automaticaly
–>
<xsl:param name="AUTO_EXPAND_INTERFACES">ON</xsl:param>
<!–
Parameter : _AUTHOR_
Values : Name <email>
Comment : define the content of @author tag
–>
<xsl:param name="_AUTHOR_">Alexandre Keledjian <dervishe@yahoo.fr></xsl:param>
<!–
Parameter : _COPYRIGHT_
Values : Any
Comment : define the content of @copyright tag
–>
<xsl:param name="_COPYRIGHT_">AFPD</xsl:param>
<!–
Parameter : _LICENSE_
Values : URL Name
Comment : define the content of @license tag
–>
<xsl:param name="_LICENSE_">http://www.gnu.org/licenses</xsl:param>
<!–
Parameter : TRANSLATE_CONSTRUCTOR
Values : ON / OFF
Comment : translate the name of the constructor to __construct
–>
<xsl:param name="TRANSLATE_CONSTRUCTOR">ON</xsl:param>
<!–
Parameter : TRANSLATE_DESTRUCTOR
Values : ON / OFF
Comment : translate the name of the ~destructor to __destruct
–>
<xsl:param name="TRANSLATE_DESTRUCTOR">ON</xsl:param>
<!–
Parameter : _CR
Values : Linux :
Windows :
Comment : Define cariage return/Line feed
–>
<xsl:param name="_CR"><xsl:text>
</xsl:text></xsl:param>
<!–
Parameter : AUTO_SETTERS_GETTERS
Values : ON/OFF (default: OFF)
Comment : allows generation of setters/getters for private data
–>
<xsl:param name="AUTO_SETTERS_GETTERS"><xsl:text>ON</xsl:text></xsl:param>
<!–
Parameter : SOAP_SERVER_URL
Values : Any (default: URL/)
Comment : SOAP server url (ie: xxxx.yyyy.zzz/ )
–>
<xsl:param name="SOAP_SERVER_URL"><xsl:text>URL/</xsl:text></xsl:param>
</xsl:stylesheet>
[/html]
Voici ce que ça donne:
Le schéma de dia: 
Et son export en php:
[php collapse=”true”]
<?php
/**
*
* Code skeleton generated by dia-uml2php5 plugin
* written by KDO kdo@zpmag.com
* @author Alexandre Keledjian <dervishe@yahoo.fr>
* @copyright AFPD
*/
class Utilisateur {
/**
*
* @var int
* @access private
*/
private $id;
/**
*
* @var int
* @access private
*/
private $id_personne;
/**
*
* @var string
* @access private
*/
private $login;
/**
*
* @var string
* @access private
*/
private $nom;
/**
*
* @var string
* @access private
*/
private $prenom;
/**
*
* @var string
* @access private
*/
private $photo;
/**
*
* @var array
* @access private
*/
private $roles = array();
/**
*
* @var string
* @access private
*/
private $dn;
/**
*
* @var string
* @access private
*/
private $courriel_adm;
const USR = ‘U’;
const SAR = ‘SAR’;
const ADM = ‘A’;
const SA = ‘SA’;
/**
* @access public
* @param string $login
*/
public final function __construct($login = null) {
}
/**
* @access public
* @return bool
*/
public final function isSuperAdmin() {
}
/**
* renvoie: 1 U1 > U2, -1 U1 < U2 et 0 sinon
* @access public
* @param Utilisateur $user1
* @param Utilisateur $user2
* @param int $region
* @return int
*/
public final function compare(Utilisateur $user1, Utilisateur $user2, $region) {
}
// setters / getters
public function set_id($value) {
$this->id = $value;
}
public function get_id() {
return $this->id;
}
public function set_id_personne($value) {
$this->id_personne = $value;
}
public function get_id_personne() {
return $this->id_personne;
}
public function set_login($value) {
$this->login = $value;
}
public function get_login() {
return $this->login;
}
public function set_nom($value) {
$this->nom = $value;
}
public function get_nom() {
return $this->nom;
}
public function set_prenom($value) {
$this->prenom = $value;
}
public function get_prenom() {
return $this->prenom;
}
public function set_photo($value) {
$this->photo = $value;
}
public function get_photo() {
return $this->photo;
}
public function set_roles($value) {
$this->roles = $value;
}
public function get_roles() {
return $this->roles;
}
public function set_dn($value) {
$this->dn = $value;
}
public function get_dn() {
return $this->dn;
}
public function set_courriel_adm($value) {
$this->courriel_adm = $value;
}
public function get_courriel_adm() {
return $this->courriel_adm;
}
}
?>
[/php]
* better-snipmate-snippet est un greffon vim (évolution du greffon snipmate) qui permet plein de choses comme la création automatique de bloc de codes ou leur édition plus rapide. Une petite vidéo qui montre les possibilités du greffon initial: ici
Pour l’installer, son auteur préconise l’utilisation du greffon pathogen.
On le télécharge ici. Vous le copiez dans ~/.vim/plugin
Il ne vous reste plus qu’à créer le répertoire ~/.vim/bundle et à rajouter en début de ~/.vimrc la ligne:
[bash]
call pathogen#infect()
[/bash]
Après il ne vous restera qu’à ajouter les greffons dans un répertoire situé dans ~/.vim/bundle.
Donc pour installer better-snipmate-snippet on va mettre ses sources via git dans ~/.vim/bundle :
[bash]
cd ~/.vim/bundle
git clone git://github.com/bartekd/better-snipmate-snippets.git
[/bash]
* MySQL-Workbench Si vous voulez de belles images de vos bases de données et / ou les manipuler graphiquement, vous pouvez utiliser MySQL WorkBench, téléchargeable ici.
La version “MySQL Workbench Community Edition” est sous license GPL.
Une petite image de l’interface jolie:

Pour finir, voici à quoi ressemble mon ~/.vimrc:
[bash]
call pathogen#infect()
:set number
:set fileformat=unix
:set encoding=utf-8
syntax on
filetype on
:set foldmethod=marker
source ~/.vim/plugin/php-doc.vim
imap <C-o> <ESC>:set paste<CR>:call PhpDoc()<CR>:set nopaste<CR>
set complete=.,w,b,u,t,i,k~/.vim/syntax/php.api
autocmd FileType php set omnifunc=phpcomplete#CompletePHP
source ~/.vim/plugin/word_complete.vim
call DoWordComplete()
set makeprg=/usr/lib64/php5.4/bin/php\ -l\ %
nmap <F9> :make<ENTER>:copen<ENTER><CTRL>L
[/bash]
Voilà, on arrive au bout du chemin. Si ça ne vous paraît pas clair, incomplet, voire inexact, n’hésitez pas à faire des remarques, je mettrai à jour au fur et à mesure.
Edit:
(28/09/2012)
* Rajout de la partie coloration syntaxique php 5.3
* Rajout de l’auto-complétion
* Check de syntax avec le client php
Monday, 13 August 2012
Des logiciels libres et un petit script vous aident à gagner de la place
Ayant eu un besoin récent de libérer des étagères chez moi, je me suis mis en tête de numériser tous mes cd musicaux. La tâche à réaliser se décomposait en: rippage du cd, récupération des informations cddb (les noms des morceaux, ceux des artistes, le genre, l’année et le numéro des pistes), encodage en flac (Free Lossless Audio Codec: c’est de la compression rapide et sans perte, tous les détails en cliquant sur le lien), ajout des tags id3 aux morceaux et constitution d’une playlist m3u pour l’album.
Dans un premier temps, je me suis frotté aux différents outils que je pourrai utiliser:
- cdda2wav pour le rippage du cd. Cet utilitaire est inclus dans la suite cdrecord (cdrtools)
- ffmpeg pour l’encodage
- eyeD3 pour travailler les tags id3 (j’ai pris celui-ci pour sa gestion des tags id3v2)
La tâche n’est absolument pas compliquée mais vraiment rébarbative. Étant d’un tempérament loutresque, je me suis fait un petit utilitaire sous la forme d’un script shell qui automatise tout ceci.
Pour la plupart des distributions, cdrecord/cdrtools et ffmpeg seront sans doute déjà installés. Il ne reste qu’à trouver le paquet de eyeD3 correspondant à votre distribution.
Une fois avoir constaté la présence de ces 3 outils sur la machine avec un petit whereis des familles:
whereis cdda2wav ffmpeg eyeD3
Si tout se passe bien, vous devriez obtenir 3 lignes avec le chemin vers chacun des utilitaires.
Il ne restait plus qu’à les utiliser avec les bonnes options:
[bash]
cdda2wav -L 0 -max -paranoia -B
ffmpeg -i monfic.wav monfic.flac
eyeD3 -2 -A "Titre album" -Y annee -G "Genre" -t "Titre" -n "Piste" -a "Interprete" monfichier.flac
[/bash]
Pour la ligne n°1:
cdda2wav va lire le cd, récupérer les données id3 sur le serveur cddb en vous demandant de choisir si plusieurs enregistrements correspondent (drapeaux: -L 0), écrire les fichiers d’information (les futurs .inf qui seront utilisés pour récupérer les tags id3) et ripper le contenu du cd sous la forme de fichiers wav (drapeaux: -B -max -paranoia) en utilisant la bibliothèque cdparanoia (meilleur rip à priori).
La ligne n°2 correspond à l’encodage (ici il n’y a rien à dire).
La ligne n°3 enfin, permet le rajout des tags id3 entre parenthèses au morceau monfichier.flac
Il ne restait plus qu’à mettre tout ceci en musique dans un petit script.
Je vous l’ai mis ici.
[bash collapse=”true”]
#!/bin/bash
# Auteur: dervishe / Alex Keledjian <dervishe@yahoo.fr>
# License: GPL2
# vim: foldmarker{{{,}}}
# Script permettant l’encodage de CD musicaux en flac à la volée
# avec fixation des tags id3 et création d’une liste m3u
#{{{Paramètres
DEVICE=’/dev/sr0′
VERSION="0.2"
ARTISTE=’Nouvel_artiste’
ALBUM=’Nouvel_album’
RIPPER=’cdda2wav’
ENCODEUR=’ffmpeg’
EDIT_ID3=’eyeD3′
EJECTEUR_ALT=’eject’
EJECTEUR=’cdrecord’
ENCODAGE_FIN=’UTF-8′
VERBEUX=1
PARANO=0
EJECT=1
NAME_TRACKS=0
WITH_M3U=1
WITH_ID3=1
JUST_ID3=0
JUST_M3U=0
FORCE_REP=0
KEEP_WFILES=0
FROM_FILES=0
REP_TMP="./tmp_$(date +%s)"
WITH_ITUNES=0
PARSE=0
ASK=0
SEPARATEUR=’/’
#}}}
function show_version() { #{{{
echo "Version: $VERSION – dervishe / Alex Keledjian <dervishe@yahoo.fr> – GPL2"
} #}}}
function show_help() { #{{{
local NOM_SOFT=$(echo $0 | sed ‘s/.*\/\([^\/]*\)$/\1/’)
show_version
echo "Usage:
$0 [options]
Options: (Les valeurs par défaut sont mentionnées entre des parenthèses)
GÉNÉRAL:
-h –help Montre l’aide
-v –version Montre la version
-d –dev Spécifier le lecteur (${DEVICE})
–quiet Mode non verbeux
–parano Utilise la libparanoia
–force-rep Force les répertoires à ceux fixée via les options -a et -A
–keep-files Garder les fichiers intermédiaires (.wav, .inf, etc.)
M3U (Playlistes):
–just-m3u Seulement construire la liste m3u
–no-m3u Ne pas faire la liste m3u
ID3 (Tag des morceaux):
-a <nom de l’artiste> Spécifier le nom de l’artiste (${ARTISTE})
-A <nom de l’album> Spécifier le nom de l’album (${ALBUM})
–just-id3 Seulement ajouter les infos id3
–no-id3 Ne pas ajouter les données id3 aux moreaux
–itunes-compat Active la compatibilité avec itunes pour les tags id3
–name-tracks Nommer les fichiers avec le nom des morceaux correspondants
-p <separateur> Analyse la titre de la chanson pour en extraire l’interprète et le titre
–ask-sep Demande le séparateur à utiliser pour analyser le titre/artiste.
–from-local-files Désactive la récupération des infos sur le serveur cddb et
force l’utilisation de fichiers locaux afin de construire les tags id3.
Utilisation:
$NOM_SOFT est assez simple d’utilisation. Mettons que vous ayez un album des ‘berniques hurlantes’ s’appelant ‘Les moules en folie’
et que vous souhaitiez en immortaliser une copie de sauvegarde. Placez-vous dans le répertoire qui doit contenir vos sauvegardes.
Plusieurs choix s’offrent à vous:
* Je suis fainéant, $NOM_SOFT va tout faire tout seul:
$0
* Je veux spécifier le titre de l’album et le nom de l’artiste:
$0 -a ‘berniques hurlantes’ -A ‘Les moules en folie’
Par défaut, $NOM_SOFT va créer automatiquement les fichiers m3u de l’album et mettre des tags id3 sur tous les morceaux.
Vous pouvez outrepasser ce comportement en utilisant les drapeaux –no-id3 et/ou –no-m3u.
Notes:
* L’encodage des donnés id3 se fait en UTF-8
* L’utilisation conjointe des drapeaux –just-id3 et –just-m3u résultera dans l’exécution du seul dernier drapeau mentionné.
* Si, lors de la phase de capture des informations, $NOM_SOFT semble bloqué, arrêter-le et relancer-le sans utiliser le drapeau
–quiet . Cela provient du fait que $RIPPER a besoin de votre aide pour l’identification de l’album.
* Pour utiliser les tags id3, il faut que votre machine soit connectée à Internet. Le script le vérifiera automatiquement et vous
proposera des options le cas échéant.
* Si vous avez déjà les fichiers inf d’une précédente récupération, en les mettant dans le même répertoire que les fichiers flac,
vous pouvez forcer leur utilisation afin de construire les tags id3. Pour ceci vous devez impérativement donner le nom de l’artiste,
celui de l’album et utiliser le drapeau –from-local-files.
* En cas d’utilisation des options: –just-m3u ou –just-id3, si vous avez des soucis liés à la non-localisation des répertoires
artiste/album, vous pouvez les forcer avec l’utilisation conjointe des options: \"-a artiste -A album –force-rep\".
* L’éjection automatique du cd nécessite un des programmes $EJECTEUR ou $EJECTEUR_ALT. Ils sont testés dans cet ordre et si aucun
n’est présent l’éjection est simplement annulée et le fait est signalé.
* Le mode ‘paranoia’ (drapeau –parano) demande à $RIPPER d’utiliser la libparanoia. Le rippage est plus long mais permet de
meilleurs résultats (à utiliser si vous avez un soucis de rippage).
* Le drapeau -p sert en cas de compilations (disques ayant plusieurs interprètes différents) à fixer les bonnes valeurs aux tags id3
‘artiste’ et ‘titre’. En paramètre, on doit lui passer le caractère séparant le nom de l’artiste, du titre dans les fichiers cddb.
Cette fonction n’est effective que dans le cadre d’actions activant la gestion des tags id3.
"
} #}}}
function check_rip() { #{{{
echo -n "[*] Recherche du ripper ${RIPPER}:"
for NUTIL in $(whereis -b $RIPPER | sed ‘s/^[^:]*: //’); do
if [ -x "$NUTIL" ]; then
RIPPER="$NUTIL"
echo " [OK] (${RIPPER})"
return 0
fi
done
echo -e "\n${RIPPER} n’a pas été trouvé, vous pouvez le spécifier avec l’option -r."
exit -1
} #}}}
function check_enc() { #{{{
echo -n "[*] Recherche de l’encodeur ${ENCODEUR}:"
for NUTIL in $(whereis -b $ENCODEUR | sed ‘s/^[^:]*: //’); do
if [ -x "$NUTIL" ]; then
ENCODEUR="$NUTIL"
echo " [OK] (${ENCODEUR})"
return 0
fi
done
echo -e "\n${ENCODEUR} n’a pas été trouvé, vous pouvez le spécifier avec l’option -e."
exit -1
} #}}}
function check_id3() { #{{{
echo -n "[*] Recherche de l’éditeur ID3 ${EDIT_ID3}:"
for NUTIL in $(whereis -b $EDIT_ID3 | sed ‘s/^[^:]*: //’); do
if [ -x "$NUTIL" ]; then
EDIT_ID3="$NUTIL"
echo " [OK] (${EDIT_ID3})"
return 0
fi
done
echo -e "\n${EDIT_ID3} n’a pas été trouvé, vous pouvez le spécifier avec l’option -i."
exit -1
} #}}}
function check_eject() { #{{{
echo -n "[*] Recherche de la commande d’éjection:"
for NUTIL in $(whereis -b $EJECTEUR | sed ‘s/^[^:]*: //’); do
if [ -x "$NUTIL" ]; then
EJECTEUR="$NUTIL"
echo " [OK] (${EJECTEUR})"
EJECTEUR="$EJECTEUR –eject –dev "
return 0
fi
done
# Test la solution alternative ‘cdrecord’
for NUTIL in $(whereis -b $EJECTEUR_ALT | sed ‘s/^[^:]*: //’); do
if [ -x "$NUTIL" ]; then
EJECTEUR="$NUTIL"
echo " [OK] (${EJECTEUR})"
return 0
fi
done
EJECT=0
echo " [FAIL] $EJECTEUR et $EJECTEUR_ALT n’ont pas été trouvés."
} #}}}
function check_connexion() { #{{{
echo -n "[*] Test de la connexion internet:"
ping -c 1 -w 2 www.google.fr > /dev/null 2>&1
if [ $? -eq 0 ]; then
echo " [OK]"
return 1
fi
echo -ne "\n\nVotre connexion internet semble non opérationnelle.
On peut désactiver la génération des tags id3. Vous pourrez alors
la refaire plus tard en exécutant:
cd $(pwd)
$0 –just-id3 -a ‘${ARTISTE}’ -A ‘${ALBUM}’
La génération des tags id3 doit-elle être désactivée (o) ou voulez-vous
continuer avec les valeurs: ‘${ARTISTE}’ et ‘${ALBUM}’ (n) ou bien encore
sortir pour spécifier certaines informations en tapant (s) ? ([o]/n/s) "
read REPI
if ! [ "$REPI" == ‘n’ ]; then WITH_ID3=0; fi
if [ "$REPI" == ‘s’ ]; then exit 1; fi
echo -e "\n[*] Désactivation de la génération des tags id3: [OK]"
} #}}}
function check_tools() { #{{{
check_rip &&
check_enc &&
if [ "$WITH_ID3" -eq 1 ]; then check_id3; fi
check_eject
} #}}}
function transcode() { #{{{
if ! [ -f ./audio.cddb ]; then
echo -n "[*] Lecture des données du disque: "
local FLAG_ID3=’ -L 0′
if [ "$WITH_ID3" -eq 0 ]; then FLAG_ID3=’ -no-infofile’; fi
local FLAG_PARANO=”
if [ "$PARANO" -eq 1 ]; then FLAG_PARANO=" -paranoia"; fi
if [ "$VERBEUX" -eq 1 ]; then
echo "${RIPPER}${FLAG_ID3}${FLAG_PARANO} -max -B -D $DEVICE"
${RIPPER}${FLAG_ID3}${FLAG_PARANO} -max -B -D $DEVICE
else
${RIPPER}${FLAG_ID3}${FLAG_PARANO} -max -B -D $DEVICE > /dev/null 2>&1
fi
echo " [OK]"
fi
echo -n "[*] Transcodage des pistes:"
for i in $(ls ./*.wav); do
if [ "$VERBEUX" -eq 1 ]; then
$ENCODEUR -i $i $i.flac > /dev/null 2>&1
else
$ENCODEUR -i $i $i.flac
fi
mv $i.flac $(echo ${i}.flac | sed "s/\.wav//")
if [ "$KEEP_WFILES" -eq 0 ]; then rm $i; fi
done
echo " [OK]"
} #}}}
function create_rep() { #{{{
if ! [ -d "$1" ]; then
echo -n "[*] Création du répertoire:"
mkdir "$1" > /dev/null 2>&1 || echo -e "\n$1 n’a pût être créé. Vérifiez les permissions.";
if ! [ -d "$1" ]; then exit -1; fi
echo " [OK] ($1)"
fi
} #}}}
function create_m3u () { #{{{
echo -n "[*] Création du fichier:";
ls ./*.flac > ./${ALBUM}.m3u
echo " [OK] (${ALBUM}.m3u)";
} #}}}
function add_id3_tag () { #{{{
if [ "$ASK" -eq 1 ]; then
echo -ne "\n Quel séparateur souhaitez-vous utiliser ? "
read REPONSE
SEPARATEUR=$REPONSE
fi
echo -n "[*] Ajout des tags m3u aux fichiers flac:"
if [ $(file ./audio.cddb | grep ‘UTF’ | wc -l) -eq 0 ]; then modif_encodage ./audio.cddb; fi
DYEAR=$(cat ./audio.cddb | grep "DYEAR" | sed ‘s/.*=\(.*\)/\1/g’)
if [ "$DYEAR" == ” ]; then DYEAR=0000; fi
DGENRE=$(cat ./audio.cddb | grep "DGENRE" | sed ‘s/.*=\(.*\)/\1/g’)
if [ $($EDIT_ID3 -l | grep ": ${DGENRE}" | wc -l) -eq 0 ]; then
echo -ne "\nLe genre est marqué comme: ‘$DGENRE’ or il ne fait pas partie de la liste autorisée.
Voulez-vous en fixer un (‘Aucun’ pour non, ‘L’ pour obtenir les valeurs possibles puis le nom ou le numéro correspondant au genre.) ? "
read REP
case $REP in
L ) echo -e "\n"
$EDIT_ID3 -l
echo -ne "\nGenre: "
read REPL
FLAG_GENRE="$REPL" ;;
Aucun ) FLAG_GENRE=” ;;
* ) FLAG_GENRE="$REP" ;;
esac
else
FLAG_GENRE="$DGENRE"
fi
exit;
for FICHIER in $(ls ./*.inf); do
if [ $(file $FICHIER | grep ‘UTF’ | wc -l) -eq 0 ]; then modif_encodage $FICHIER; fi
TITRE=$(cat $FICHIER | grep "Tracktitle" | sed "s/.*=\s*’\(.*\)’/\1/g")
if [ "$PARSE" -eq 1 ] && [ $(echo $TITRE | grep "$SEPARATEUR" | wc -l) -eq 1 ]; then
PERF=$(echo $TITRE | awk "BEGIN{ FS=\"${SEPARATEUR}\" }; { print \$1 }")
TITRE=$(echo $TITRE | awk "BEGIN{ FS=\"${SEPARATEUR}\" }; { print \$2 }")
else
PERF=$(cat $FICHIER | grep "Performer" | sed "s/.*=\s*’\(.*\)’/\1/g")
fi
DALBUM=$(cat $FICHIER | grep "Albumtitle" | sed "s/.*=\s*’\(.*\)’/\1/g")
if [ "$DALBUM" == ” ]; then DALBUM=$ALBUM; fi
if [ "$PERF" == ” ]; then PERF=$ARTISTE; fi
TNUM=$(echo $FICHIER | sed ‘s/.*_\([[:digit:]]*\).*/\1/’)
if [ "$TNUM" == ” ]; then TNUM=00; fi
NFICHIER=$(echo $FICHIER | sed ‘s/\.inf/\.flac/’)
if [ "$WITH_ITUNES" -eq 1 ]; then
local FLAG_ITUNES=’ –itunes’
else
local FLAG_ITUNES=”
fi
if [ "$FLAG_GENRE" == ” ]; then
if [ "$VERBEUX" -eq 1 ]; then
$EDIT_ID3 -2$FLAG_ITUNES -A "$DALBUM" -Y "$DYEAR" -t "$TITRE" -n "$TNUM" -a "$PERF" "$NFICHIER"
else
$EDIT_ID3 -2$FLAG_ITUNES -A "$DALBUM" -Y "$DYEAR" -t "$TITRE" -n "$TNUM" -a "$PERF" "$NFICHIER" > /dev/null 2>&1
fi
else
if [ $(echo ‘$FLAG_GENRE’ | grep "\s" | wc -l) -gt 0 ]; then
if [ $VERBEUX -eq 1 ]; then
$EDIT_ID3 -2$FLAG_ITUNES -A "$DALBUM" -Y "$DYEAR" -G "$FLAG_GENRE" -t "$TITRE" -n "$TNUM" -a "$PERF" "$NFICHIER"
else
$EDIT_ID3 -2$FLAG_ITUNES -A "$DALBUM" -Y "$DYEAR" -G "$FLAG_GENRE" -t "$TITRE" -n "$TNUM" -a "$PERF" "$NFICHIER" > /dev/null 2>&1
fi
else
if [ "$VERBEUX" -eq 1 ]; then
$EDIT_ID3 -2$FLAG_ITUNES -A "$DALBUM" -Y "$DYEAR" -G "$FLAG_GENRE" -t "$TITRE" -n "$TNUM" -a "$PERF" "$NFICHIER"
else
$EDIT_ID3 -2$FLAG_ITUNES -A "$DALBUM" -Y "$DYEAR" -G "$FLAG_GENRE" -t "$TITRE" -n "$TNUM" -a "$PERF" "$NFICHIER" > /dev/null 2>&1
fi
fi
fi
if [ "$NAME_TRACKS" -eq 1 ]; then
local NF=$(normalize ${TNUM}_${TITRE}.flac)
if ! [ "$NF" == "${TNUM}_.flac" ]; then mv $(echo $FICHIER | sed ‘s/\.inf/\.flac/’) ./${NF}; fi
fi
done
echo " [OK]"
} #}}}
function modif_encodage() { #{{{
local ENC="$(file $1 | awk ‘{ print $2 }’)"
if [ "$ENC" == ‘ISO-8859′ ]; then ENC=’ISO-8859-1′; fi
iconv -f $ENC -t $ENCODAGE_FIN ./$1 > ./$1.bak
mv ./$1.bak ./$1
} #}}}
function clean_work_files() { #{{{
echo -n "[*] Nettoyage des fichiers de travail:"
if [ -d "../${ALBUM}" ] && [ $(ls ../${ALBUM} | grep -v "flac\|m3u" | wc -l) -gt 0 ]; then rm $(ls ../${ALBUM} | grep -v "flac\|m3u"); fi
echo " [OK]"
} #}}}
function guess_who() { #{{{
echo -n "[*] Lecture des données du disque: "
if ! [ -d "$REP_TMP" ]; then mkdir $REP_TMP; fi
cd $REP_TMP
if [ "$JUST_ID3" -eq 0 ] && [ "$JUST_M3U" -eq 0 ]; then
local FLAG_BUILD="-max -B"
if [ "$PARANO" -eq 1 ]; then FLAG_BUILD="-paranoia $FLAG_BUILD"; fi
else
local FLAG_BUILD=’-J’
fi
if [ "$VERBEUX" -eq 1 ]; then
$RIPPER -L 0 $FLAG_BUILD -D $DEVICE;
else
$RIPPER -L 0 $FLAG_BUILD -D $DEVICE > /dev/null 2>&1;
fi
echo -e "\n" > ./file.tmp; cat ./audio.cddb >> ./file.tmp; mv ./file.tmp ./audio.cddb # Nécessaire pour l’assimilation du fichier à un fichier texte pour file
if [ $(file ./audio.cddb | grep ‘UTF’ | wc -l) -eq 0 ]; then modif_encodage ./audio.cddb; fi
TITRE_ALBUM=$(cat ./audio.cddb | grep DTITLE | sed ‘s/.*=\(.*\)/\1/’);
local TMP1=$(normalize $(echo $TITRE_ALBUM | sed ‘s/\(.*\)\s*\/.*/\1/’))
local TMP2=$(normalize $(echo $TITRE_ALBUM | sed ‘s/.*\/\s*\(.*\)/\1/’))
if [ "$ARTISTE" == ‘Nouvel_artiste’ ] && ! [ "$TMP1" == ” ]; then ARTISTE="${TMP1}"; fi
if [ "$ALBUM" == ‘Nouvel_album’ ] && ! [ "$TMP2" == ” ]; then ALBUM="${TMP2}"; fi
cd ..
echo " [OK]"
} #}}}
function normalize() { #{{{
local argument="$@"
if [[ "$argument" =~ "\s*([^[[:space:]]].*[^[[:space:]]])\s*" ]]; then
$argument=${BASH_REMATCH[1]}
fi
argument=$(echo $argument | sed ‘s/\s/_/g’)
echo $argument
} #}}}
function check_argument() { #{{{
if [ -z "$OPTARG" ]; then
echo -e "\nIl manque un argument au drapeau: ‘-$1’\n"
show_help
exit -1
fi
} #}}}
#{{{ Analyse des paramètres
while getopts "hvA:a:d:p:-:" option; do
case $option in
h ) show_help
exit 0 ;;
v ) show_version
exit 0 ;;
a ) check_argument ‘a’; ARTISTE=$(normalize $(echo $OPTARG)) ;;
A ) check_argument ‘A’; ALBUM=$(normalize $(echo $OPTARG)) ;;
d ) check_argument ‘d’; DEVICE=$OPTARG ;;
p ) SEPARATEUR=$OPTARG; PARSE=1 ;;
– ) case $OPTARG in
help ) show_help
exit 0 ;;
version ) show_version
exit 0 ;;
quiet ) VERBEUX=0 ;;
parano ) PARANO=1 ;;
name-tracks ) NAME_TRACKS=1 ;;
force-rep ) FORCE_REP=1 ;;
keep-files ) KEEP_WFILES=1 ;;
from-local-files ) FROM_FILES=1 ;;
ask-sep ) ASK=1; PARSE=1 ;;
just-m3u ) JUST_M3U=1; WITH_ID3=0 ;;
just-id3 ) JUST_ID3=1; WITH_M3U=0 ;;
no-m3u ) WITH_M3U=0 ;;
no-id3 ) WITH_ID3=0 ;;
itunes-compat ) WITH_ITUNES=1 ;;
* ) echo "Option non reconnue: ${OPTARG}"
show_help
exit -1 ;;
esac ;;
? ) echo -e "\nUn des drapeaux que vous avez utilisé nécessite un argument.\n"
show_help
exit -1 ;;
esac
done
#}}}
#{{{ Main
if [ "$WITH_ID3" -eq 1 ]; then check_connexion; fi
check_tools &&
if [ "$FROM_FILES" -eq 0 ] && [ "$ALBUM" == ‘Nouvel_album’ ] || [ "$FROM_FILES" -eq 0 ] && [ "$ARTISTE" == ‘Nouvel_artiste’ ] && [ "$WITH_ID3" -eq 1 ] && [ "$FORCE_REP" -eq 0 ]; then
guess_who
else
if [ "$ALBUM" == ‘Nouvel_album’ ] && [ "$ARTISTE" == ‘Nouvel_artiste’ ] && [ "$FORCE_REP" -eq 0 ]; then
echo -e "\nVous n’avez pas spécifié d’artiste et d’album.";
exit -1;
fi
ARTISTE=$(normalize "$ARTISTE")
ALBUM=$(normalize "$ALBUM")
fi
if [ "$JUST_ID3" -eq 0 ] && [ "$JUST_M3U" -eq 0 ]; then
create_rep ./$ARTISTE &&
create_rep ./${ARTISTE}/${ALBUM}
if [ -d "$REP_TMP" ]; then
mv ${REP_TMP}/* ./${ARTISTE}/${ALBUM}/
if [ "$KEEP_WFILES" -eq 0 ]; then rmdir $REP_TMP; fi
fi
cd ./${ARTISTE}/${ALBUM} &&
transcode || exit -1
else
if ! [ -d "./${ARTISTE}/${ALBUM}" ]; then
echo -e "\nErreur de lecture de répertoire: ‘./${ARTISTE}/${ALBUM}’ n’existe pas !";
exit -1;
fi
if [ -d "$REP_TMP" ]; then
mv ${REP_TMP}/* ./${ARTISTE}/${ALBUM}/
if [ "$KEEP_WFILES" -eq 0 ]; then rmdir $REP_TMP; fi
fi
cd ./${ARTISTE}/${ALBUM}
fi
if [ "$WITH_ID3" -eq 1 ]; then
if [ "$JUST_ID3" -eq 1 ]; then
if ! [ -f ./audio.cddb ] && [ "$FROM_FILES" -eq 1 ]; then
if [ "$VERBEUX" -eq 1 ]; then
$RIPPER -L 0 -J -D $DEVICE;
else
$RIPPER -L 0 -J -D $DEVICE > /dev/null 2>&1;
fi
fi
if [ "$NAME_TRACKS" -eq 1 ]; then WITH_M3U=1; fi
fi
if [ "$EJECT" -eq 1 ] && [ "$FROM_FILES" -eq 0 ]; then ${EJECTEUR} ${DEVICE} > /dev/null 2>&1; fi
add_id3_tag
else
if [ "$EJECT" -eq 1 ] && [ "$FROM_FILES" -eq 0 ] && [ "$JUST_M3U" -eq 0 ]; then ${EJECTEUR} ${DEVICE} > /dev/null 2>&1; fi
fi
if [ "$WITH_M3U" -eq 1 ]; then
create_m3u;
if [ "$JUST_M3U" -eq 1 ]; then exit 1; fi
fi
if [ "$KEEP_WFILES" -eq 0 ]; then clean_work_files; fi
#}}}
[/bash]
Pour l’utiliser, copiez le contenu ou téléchargez-le dans un fichier (par expl cd2flac), puis:
chmod +x ./cd2flac
Je vous recommande de créer un répertoire temporaire d’où vous pourrez exécuter le script.
Du coups, j’y ai placé une aide accessible via:
./cd2flac --help
Si vous avez des suggestions, ou modif, n’hésitez pas à proposer.
Je pense rajouter la possibilité de lire les fichiers inf non plus seulement à partir du serveur cddb mais aussi via un fichier texte (ce qui permettra de tagguer les disques n’ayant pas de fiches cddb).
Monday, 25 June 2012
ACTA : « une forme douce de terrorisme » / “A kind of soft terrorism”
Nous sommes censés représenter les citoyens, mais comme ils sont occupés à autre chose, nous sommes censés réfléchir à leur place !
We are supposed to represent citizens, however since they are busy with other things, we are supposed to think for them!
— Marielle Gallo, députée du parlement européen favorable à ACTA, à propos du vote des commissions du parlement européen contre le texte.
pro-ACTA MEP, about the vote against the treaty from the European Parliament commissions
(source pcINpact)
Friday, 27 January 2012
Quelques notes sur la seconde licence publique Mozilla (MPL 2.0)
(A short post in French on the Mozilla Public License 2.0. If you want to know about it, you can read in English Luis Villa, who led the update process. Richard Fontana wrote an article (RedHat); and the FSF has lauded the compatibility with GNU licenses.)
Cette année, une petite nouvelle est arrivée dans le monde des licences de logiciel libre : la seconde version de la licence publique Mozilla (MPL 2.0). Elle n’est pas totalement nouvelle, car elle garde l’esprit général de la première version puisqu’il s’agit d’une licence de faible copyleft. C’est-à-dire que cette licence permet dans une certaine mesure — assez large — de combiner du code régi par la MPL avec du code sous une autre licence (y compris propriétaire). Pour autant, des modifications apportées aux fichiers du code MPL doivent être régies par les mêmes obligations : mise à disposition du code source, notifications des droits des utilisateurs (droits d’utiliser, de partager, d’étudier le fonctionnement et de publier des modifications — la définition d’un logiciel libre).
Ainsi, la MPL est un bon compromis, entre d’un côté les licences “académiques” (BSD, MIT) et de l’autre, les licences copyleft¹ fortes comme la licence publique générale GNU. Mais comme tout compromis, la MPL souffre des inconvénients incombant à chacun des deux modèles de licence.
Il y a cependant des qualités indéniables à la MPL 2.0, que j’ai voulues résumer ici […]
Lire Les qualités de la MPL 2.0.
Friday, 13 January 2012
Débat « Surfons libre », le samedi 4 février après midi !
![]()
Réservez votre 4 février après midi pour une convergence maximale des luttes ! Surfons libre. Nous débattrons notamment des alternatives libres aux services de google& co. Ça causera auto-hébergement à n’en pas douter 
————-
Après-midi de débats surfons libre
Le Samedi 4 février de 15 à 18h
Au Moulin à Café, 9 Pl. de la Garenne
Paris 14ème , M° Pernety
Au programme:
Présentation de l’idée du Collectif Surfons Libres – Surfons libres c’est l’idée de faire dialoguer les organisations et citoyens qui défendent un Internet libre ! – 15 minutes
Les services en ligne à la solde des publicitaires ? Surfez couverts ! (Avec l’association Résistance à l’Agression Publicitaire)
15 minutes + 25 minutes débat
Plate-forme de mobilisation citoyenne en ligne pour la protection des données personnelles (Avec Internet Sans Frontières)
15 minutes + 25 minutes débat
Débat citoyen et libre sur les alternatives aux services non respectueux des données personnelles et logiciels propriétaires
40 minutes
La constitution d’un collectif SURFONS LIBRES, collectif d’individus et d’organisations pour la défense d’un Internet libre
30 minutes
Un Internet libre et accessible pour toutes et tous c’est possible !
Tuesday, 03 January 2012
TrueBlock Plus: Qui peut le plus, peut le moins !

Et voilà, il n’aura pas fallu bien longtemps pour voir une fourchette de l’excellent Ad Block Plus se mettre en place après l’horrible mise à jour… True Block Plus est dans la place de Mozilla et les commentaires sur l’initiative de Éric Bishop, le mainteneur, sont plutôt positifs. Son initiateur affirme ne pas vouloir, pour le moment, un développement parallèle mais seulement conserver les acquis sans cette case à cocher étrangement inutile qui laisse passer certaines pubs. Ce dernier appelle aux dons, mais pas pour lui, pour le projet Ad Block Plus. Je ne peux m’empêcher d’y voir une certaine ironie, voire un message caché, qui pourrait être « Si tu veux du fric, on va t’en donner, mais s’il-te-plaît ne prostitue pas cette belle extension aux pubards ! ».
La question est de savoir désormais, combien vont préférer une extension qui bloque la pub à une extension qui bloque la pub si l’utilisateur le veux vraiment. Je me demande si le mainteneur de Ad Block Plus ne s’est pas inspiré de Zuckerberg avec ses tonnes de fonctionnalités intrusives activées par défaut que l’utilisateur peut désactiver s’il le veut vraiment. Ces gens-là, c’est une informatique basée sur l’exploitation de l’inculture numérique qu’ils promeuvent. Et c’est mal. Ce n’est pas parce qu’on a des connaissances qu’il faut chercher à piéger les autres, bien au contraire. Il ne faut rien laisser passer, même si Ad Block Plus n’en est évidemment pas au niveau de facebook qui bat tous les records…
De toute façon, le modèle publicitaire sur internet n’a aucun avenir. Le récent rachat de Rue 89 par le Nouvel obs qui n’a toujours pas trouvé l’équilibre le démontre. À l’inverse, Wikipedia est parvenu à récolter 20 millions d’euros en 50 jours uniquement car son fondateur ne veut pas de publicité et qu’il considère cet espace comme un jardin public. Pour ma part, j’aimerais que tout Internet soit un magnifique jardin public et que la publicité ne soit pas là pour polluer l’information que je partage. True Block plus m’en donne la possibilité mais je trouve injuste que ceux qui n’aient pas les même connaissances que moi ne partagent pas ce bonheur.
Il y a le choix entre deux options, soit un modèle payant semi-public à la Mediapart ou totalement privé à la @si, soit le mécénat qui consisterait à faire vivre des sites par le don. À titre personnel, j’ai un faible pour le principe du mécénat global proposé par Stallman et la Free Software Fondation.
Bon, et bien entendu, le modèle publicitaire est loin d’être entaillé par True Block Plus, il en faudra bien plus. Je pense que la meilleure parade est de démontrer qu’il est possible de faire autrement, car au fond, il n’y a bien que les publicitaires qui aiment la publicité.
Téléchargez True Block Plus et encouragez son initiateur pour que l’extension sorte des abîmes du site de Mozilla !
Sunday, 01 January 2012
Je quitte facebook

Après quatre ans d’activité sur Facebook, j’ai décidé de quitter ce service dans moins d’une semaine, de récupérer toutes mes données personnelles et les faire supprimer du serveur de l’entreprise. C’est avec un peu de tristesse et dans un certain esprit de sacrifice que j’ai pris cette décision il y a quelques mois de cela. Depuis quelques années – ceux et celles qui me suivent sur le réseau social ont pu le constater – le nombre d’informations mettant en garde les utilisateurs contre Facebook, à tous les niveaux, va croissant. Le plus inquiétant et le plus palpable est sans doute le problème de la maîtrise des données personnelles de l’utilisateur. Malgré des initiatives dont le but premier est de rassurer les utilisateurs et les marchés financiers en vue d’une entrée en bourse imminente, Facebook reste un espace d’insécurité numérique où l’internaute est à la merci d’une seule logique : récolter toujours plus vos données personnelles et augmenter toujours d’avantage leur caractère publique.
Les usages des données personnelles sont multiples et inquiétants. En premier lieu, la publicité ciblée, que l’on ne présente plus et qui représente plus de 80 % des revenus de Facebook. L’entreprise a fait le choix, ces derniers temps, de lancer une initiative « pédagogique » envers ses utilisateurs dans le but de leur faire avaler toujours plus de publicités intrusives et superflues. Bientôt, l’entreprise en mettra dans votre fil de statuts. En second lieu, Facebook collabore avec des autorités d’États pour la lutte « anti-terroriste », notamment avec les États-Unis. Les relations de Mark avec le président Barack Obama sont au beau fixe. Le problème se trouve dans la définition de ce terme de terroriste et qui cela englobe. Quand les services des états recherchent « des terroristes », ils ont très probablement accès à l’ensemble des données présentes sur Facebook. Les limitations ne sont pas réellement définies. En troisième lieu, bien que Facebook assure ne pas vendre les bases de données à des entreprises commerciales, et qui, pour le prouver, se contente d’asséner que « ce ne serait pas dans son intérêt », nous pouvons légitimement nous poser la question. Puisque Facebook est une entreprise commerciale, le but recherché est le profit. N’y a-t-il pas de profits à tirer dans la vente de bases de données personnelles sous le manteau ?
Les utilisateurs de Facebook sont la seule raison d’être de Facebook. Sans utilisateurs, pas de données personnelles, sans données personnelles, pas de profit. Pourtant, nous ne participons pas aux prises de décisions stratégiques de l’entreprise concernant son développement et nous ne pouvons pas vérifier les fonctionnalités de collecte de données ou de censure dans le code source puisque celui-ci relève strictement du secret industriel.
La récolte frauduleuse des données personnelles et le fichage systématique de plus en plus millimétré sont les premières raisons de mon départ. Comme l’a démontré Internet Sans Frontières dans sa plainte auprès de la CNIL, Facebook utilise des méthodes dangereuses qui mettent en péril les libertés des citoyens. Collecte des données en dehors de Facebook par l’intermédiaire du bouton like, création de profils fantômes à travers la synchronisation des répertoires de courriels et de téléphones, identification systématique et automatique des visages sur les photos avec la technique biométrique…
La publicité croissante et insidieuse, utilisant des méthodes de chantage affectif pour faire cliquer mes ami.e.s, me gêne profondément. Lorsque je livre mes infos persos à la publicité Facebook, je livre mes ami.e.s en pâture aux publicitaires qui ne manqueront pas de faire remarquer que j’aime tel ou tel produit. Si actuellement cela s’arrête à informer mes ami.e.s que moi aussi je suis fan du Coca-Cola (ce qui n’est pas mon cas :-)), il est à craindre des usages encore plus intrusifs qui exploiteraient les photos sur lesquelles vous vous trouvez en train de consommer une marque en particulier. Ils ont la technique, reste à voir pour Facebook les obstacles juridiques et moraux des utilisateurs.
La politique de censure exercée par Facebook est de plus en plus inquiétante. Si l’on sait depuis 2009 que Facebook est le toutou des industries du divertissements, par la censure de The Pirate Bay notamment (essayez de poster un lien The Pirate Bay pour voir ;-)), la dernière censure notable de septembre 2011 atteint des sommets. Les premiers messages sur le réseau appelant à Occupy Wallstreet ont été honteusement censurés, sans justification et par des techniques sournoises. Certains événements ont été supprimés, d’autres statuts ont été rendus visibles uniquement par ceux et celle qui les postaient. Facebook – qui doit rentrer en bourse très prochainement, rappelons-le – a un intérêt direct à censurer un tel mouvement pour éviter toute contestation de cette institution qui sert son expansion. D’autres cas de censures, nombreux, ont été recensés, nous ne les listerons pas ici.
Voici les principales raisons de mon départ sommairement résumées. Certains et certaines se demanderont probablement « Mais pourquoi avoir attendu si longtemps ? ». En réalité, je pense que nous avons vécu ces dernières années une période de révolution informationaliste incroyable et qu’aujourd’hui nous nous réveillons un peu avec la gueule de bois. Comme si nous nous retrouvions en terrain conquis. Le premier volet a été l’émerveillement de ces nouveaux moyens de partage et de débat démocratique qui ont transformé profondément et durablement l’organisation sociale du Monde. L’accès de tout-e citoyen-ne à une masse d’informations toujours plus importante et précieuse participe à rendre la société plus transparente et lui redonner un pouvoir politique. Je ne m’étalerai pas sur cette période car aujourd’hui il faut nous atteler à éviter le second volet : une contre-révolution dangereuse en progression qui consiste en la surveillance constante et systématique du citoyen. Si ce processus est déjà bien avancé, il n’est pas encore complet et total. Nous assistons, trop passivement, à la reprise en mains des États et des grandes entreprises qui ont des intérêts divergents à ceux des citoyennes et des citoyens libres. Si dans ce billet je parle en particulier de Facebook, ce n’est pas le seul enjeu auquel il faut s’intéresser. Mais il faut occuper le terrain, tout le terrain.
La deuxième raison pour laquelle j’ai attendu aussi longtemps avant de me jeter à l’eau est affective. En effet, grâce au réseau social Facebook, je garde contact avec de nombreux/nombreuses ami.e.s à travers la France et le Monde que je ne vois pas tous les jours. Si je quitte Facebook, je perdrais avec certains, très probablement, le contact faible qu’il restait. De plus, j’adore papoter politique et de choses simples de la vie, voir les photos de mariages, de soirées, des nouveaux nés, etc. Également, je vais perdre un relais efficace pour les publications de mon blog. Ou bien encore professionnellement, par l’intermédiaire de Facebook j’ai pu accéder à de nombreuses opportunités. La vie locale de ma cité universitaire me sera moins accessible car les soirées et autres événements sont annoncés d’abord sur Facebook. Ne pas être sur Facebook donc, à l’heure actuelle, je le vois comme un véritable handicap social.
Ceci étant, comme je l’ai écrit précédemment, la raison d’être de Facebook, ce sont ses utilisateurs. Sans utilisateurs, Facebook ne représente aucun intérêt. C’est pourquoi, plus que dans n’importe quel type de situation, l’adéquation entre la pensée et l’acte doit primer. L’architecture du réseau et l’organisation qui maintient et développe le service sont les racines du problèmes. La nature centralisée du service est un problème en soit pour la maîtrise des données personnelles. Le simple fait de permettre à une organisation, quelle que soit sa logique, d’avoir autant de données sur autant de personnes devrait nous pousser à ne pas nous y inscrire. La moindre dérive dans la gestion du droit d’accès à ces données peut avoir des conséquences catastrophiques pour les libertés. De nombreux internautes ont déjà fait ce constat et ont pris le parti de lancer des initiatives d’alternatives. De nombreux projets de logiciels libres de réseaux sociaux sont en cours de développement. Diaspora, Status.net, GNU social, Crabgrass… et de nombreux autres. J’avais notamment participé à Movim pendant un moment. Bref, ce n’est pas ce qui manque.
Dans les jours, semaines et mois qui viennent, en tant que simple citoyen, je vais entreprendre des démarches afin d’obtenir de Facebook deux choses :
-
La récupération de la totalité des données personnelles que j’ai ajoutées ou qui ont été générées.
-
La suppression totale de mes données personnelles des serveurs de Facebook dans un délai convenable et légal.
Je vous tiendrai au courant régulièrement des avancées.
Pour finir, je vous recommande la lecture d’un billet que j’ai écrit en mai 2010 qui reste aujourd’hui plus que jamais d’actualité.
« Des syndicats 2.0 pour défendre les intérêts des contributeurs »
Comme quoi, ma critique de Facebook ne date pas d’il y a deux jours 
Bonne année 2012 !
Pour rester en contact avec moi :
twitter : @antoninmoulart Identi.ca : @antoninmoulart
Diaspora : https://joindiaspora.com/u/antoninus (j’envoie des invitations sur demande)
Mon courriel : antonin@moulart.org
mon jabber : antonin@jappix.com
Mon téléphone : sur demande
Tuesday, 13 December 2011
Faut-il initier un fork de Ad Block Plus ?
![]()
Ad Block Plus annonce qu’il ne bloquera plus toutes les publicités. L’extension phare de firefox vient de remettre en question l’utilité de sa vocation. Il fallait le faire et ils l’ont fait… Serait-ce dus à irrésistible pression de google, principale financeur de mozilla firefox ? La communauté serait-elle arrivé à la conclusion que la publicité présenterait un intéret pour l’internaute ? Queneni !
L’argument avancé est l’argument du pire: « Un peu de publicité c’est bien pour faire vivre les petits sites ! ». Tout le fatalisme d’une pensée dominante résumé en une seule petite phrase TINA « There Is No Alternative ».
Et pourtant ! Parmi les 10 sites les plus consultés au monde, une communauté d’irréductible résiste encore et toujours à l’envahisseur. Il s’agit de wikipedia, qui, sans publicité, fait figure d’exemple en embauchant pas moins de 90 salariés et entretenant une infra-structure serveur des plus impressionnantes.
De plus en plus nombreux sont les sites d’informations en ligne à trouver des modèles économiques alternatifs durable. On peut notamment penser à Mediapart et Arrêts sur image qui depuis quelques années vivent grâce aux abonnements de ses membres. D’autres sites comme reflets.info font le paris ambitieux des dons en ligne. Si les rédacteurs sont loin de vivre de ces recettes, il faut souligner cette volonté d’encourager les internautes à changer leurs comportements de consommation sur internet. Du propre avoeux des auteurs, le site tourne actuellement à 20% de ses capacités, ce qui pourrait donner envie aux internautes de donner s’ils souhaitent d’avantage de productions. Autre exemple, le blog de Paul Jorion tourne très bien sur ce modèle avec des recettes d’un peu plus de 3000 € mensuel, le blog fait figure d’exemple sur l’internet français.
Le modèle économique d’un site d’information n’est pas simplement une question de respect des données personnelles des utilisateurs ou de pollution visuelle sur le site en question. C’est d’abord et surtout la question de l’indépendance qui est soulevé. Souvenez vous il y a quelques semaines de l’affaire de la tribune qui avait publié un article desservant les intérêts de l’industrie du nucléaire… Du jour au lendemain Henry Proglio PDG d’EDF avait supprimé une campagne publicitaire dans la revue qui devait la financer à hauteur de 60 000€. De quoi mettre un journal en faillite… Et puis, on peut s’interroger de l’intérêt d’une firme, ancien monopole d’état, à faire de la publicité… Sur qui cherchent-ils à prendre avantage ? Il n’y a pas de concurrent… Tout le monde sait que les EPR sont sur à 200%, non ? A moins que la population ait besoin d’être rassuré… N’est-il pas inutile de se payer des pages de propagande dans des journaux respectable qui bradent leur crédibilité pour faire vivre leur rédaction ? A moins que ce soit pour contrôler le contenu… ???
Ad Block Plus nous rassure tout de même. Pour ceux qui ne veulent même pas (des furieux probablement) de « pub acceptable », il y a toujours moyen de cocher une case pour s’en débarasser. Ad Block Plus nous colle une option de retrait de la publicité en second degré ! Cela signifie que pour ne pas voir de publicité dans votre navigation web, il faut d’abord installer firefox, ensuite installer Ad Block Plus et après cocher la petite case dans la configuration de l’extension pour dire « Non, je ne veux VRAIMENT pas de publicité ! ». La prochaine sera peut-être l’ajout d’une seconde case « Non, j’insiste vraiment, vous me faites chier avec vos réclames !!! » ? On peut continuer comme ça à l’infinie…
La publicité sur internet est par définition inacceptable car elle est inintéressante et sans intérêt pour l’internaute. Les flots d’informations qui circulent sur le réseau sont déjà assez laborieux à trier et notre temps de cerveau assez précieux pour qu’en plus nous devions filtrer mentalement le bon grain de l’ivraie. Sans parler des problèmes de la récolte des données personnelles qu’Ad Block plus ne traite pas…
Alors la question est la suivante: Faut-il créer un fork d’ad block plus ?
Il s’agirait d’une extension antipub avec une option de retrait par défaut de la publicité (ben oui, c’est un peu le but d’une telle extension), tout simplement. Elle s’adresserait à tous ceux qui n’ont pas le temps de s’amuser à cocher des cases inutile sur un logiciel précieux.
A cela s’ajouterait une partie de type « ghostery » qui bloquerait l’ensemble des scripts qui traques nos données personnelles sans nous demander la permission préalable et explicite.
La question de bloquer les anti-block devrait également être une piste que ce fameux logiciel explorerait. Également la question de la publicité sur les vidéos ?
Bref, on pourrait appeler cette extension « ad block vraiment » ou « ad block plus plus ». Ce serait une super extension appréciable et une belle réponse à ce choix politique de la communauté d’ad block plus des plus absurdes.

Thursday, 21 July 2011
La FSFE aux RMLL
La FSFE était présente aux Rencontres mondiales du logiciel libre, qui se tenaient ce mois de juillet à Strasbourg. Un grand merci aux organisateurs, notamment à Jean-Michel Ramseyer et Nicolas Jean pour le thème Internet du programme, qui se focalisait notamment sur les systèmes distribués libres.
C’est d’ailleurs l’un des nombreux sujets abordés par Karsten Gerloff, interviewé lors des RMLLs. Vous pouvez télécharger l’entretien, doublé en français sur le site des RMLL (streaming, m3u ou téléchargement direct, ogg/vorbis).
Wednesday, 30 March 2011
Célébration du Document Freedom Day à Berlin


Aujourd’hui, plusieurs fellows de la FSFE, Matthias Kirschner, Stephan Uhlmann (FFII) et moi-même avons revêtu nos plus beaux habits de cérémonie, et sommes allés à la rencontre de ARD, un des plus grands groupes de diffusion de médias allemands (télévision, radio, site internet).
Nous avons organisé ce rendez-vous, en partenariat avec la FFII, pour les féliciter des moyens de diffusion mis en oeuvre sur leur site, où les utilisateurs peuvent visionner les vidéos au format libre « Ogg Theora ». Ceci permet à tous l’accès aux contenus vidéo de l’entreprise publique, sans imposer un format ou un logiciel en particulier. Sur d’autres sites proposant des vidéos, ceux-ci se révèlent en effet souvent être propriétaires et n’offrent donc pas la liberté de choix aux internautes.
Nous avons donc remis le « prix pour l’utilisation et la promotion des standards ouverts » aux responsables du site, qui d’après leur propos se sont battus en interne contre vents, marées et budgets pour finalement proposer des formats libres. Par les temps qui courent, ou la plupart des sites de contenus se tournent vers l’alternative la plus connue par simplicité, la volonté de promouvoir des formats libres relève d’un certain courage que nos deux associations se devaient de couronner.
Après une part de tarte “rOgg On!” et un petit café, la discussion fut lancée et a été très instructive, dévoilant au fur et à mesure les coulisses techniques de l’architecture informatique de cet immense centre multimédia. Les différents formats dans lesquels les vidéos sont sauvegardés, combien de temps elles le sont et pourquoi, et nombreuses autres anecdotes nous ont tenus en haleine pendant une petite heure et demi.
Les photos de l’événement sont disponibles sur le wiki de la FSFE, enjoy! Que cela vous donne envie de participer l’année prochaine.
Et bien sûr, plus d’info sur le DFD là : http://documentfreedom.org
Wednesday, 16 February 2011
Microsoft interdit les logiciels libres sur son Windows Marketplace
Jan Wildeboer vient de découvrir dans le contrat gouvernant le Windows Marketplace, l’ “App Store” du Windows Phone et de la XBox, quelques stipulations intéressantes…
Article 5 (traduit par mes soins):
e. L’Application ne doit inclure ni logiciel, ni documentation, ni aucun autre matériel qui, totalement ou en partie, est gouverné par ou sujet à une Licence Exclue, ou qui autrement causerait à l’Application d’être assujettie aux termes d’une Licence Exclue.
Comment le contrat définit-il une Licence Exclue ?
“Licence Exclue” comprend toute licence requérant, comme condition d’utilisation, de modification et/ou de distribution du logiciel assujetti à la licence, que le logiciel ou tout autre logiciel combiné et/ou distribué avec lui soit (i) dévoilé ou distribué sous la forme de code source; (ii) licencié dans le but de produire des œuvres dérivées; ou (iii) redistribuable sans frais*. Les Licences Exclues incluent, mais ne sons pas limitées aux Licences GPLv3. Dans le cadre de cette définition, “Licences GPLv3” désignent la Licence Générale Publique GNU version 3, la Licence Affero Générale Publique GNU version 3, la Licence Moindre Générale Publique GNU version 3, ainsi que tout équivalent à celles-ci.
Donc, ce n’est pas seulement le copyleft qui semble banni (comme on pourrait en faire l’interprétation concernant les conditions de l’App Store d’Apple) mais bien toute licence équivalant aux licences GPL désignées et surtout, tout logiciel qu’on peut partager librement…
Correction: le contrat exclut toute licence qui requiert la “redistribuabilité” sans frais du logiciel. Peut-on dire qu’une licence BSD/MIT requiert cela? Un logiciel n’est libre que si on a la liberté de redistribuer des copies. On ne peut pas dire que la licence du logiciel libre requiert la redistribution sans frais, mais elle requiert cette possibilité (donc on parle bien de “redistribuabilité”, en anglais “redistributable”).
* “redistribuable sans frais” : ça concerne bien tous les logiciels libres, GPL, BSD, MIT…
Friday, 08 October 2010
Euro 2012 des logiciels libres : nouvelle vague de résultats

Près d’un mois après les matchs qualificatifs des 3-4 Septembre, 42 pays ont de nouveau joués pour la qualification à l’Euro 2012. De notre côté, la notation des gouvernements suivant leur utilisation et promotion des logiciels libres continue ! Guido a mis les résultats des 21 matchs de ce 8 Octobre en ligne , et comme d’habitude, voilà mon appréciation des grands affrontements de ce 8 Octobre :
- Allemagne 4 : 2 Turquie : Défaite sans surprise de l’Allemagne, une des équipes meneuses de cet Euro 2012 des logiciels libres. La Turquie marque tout de même deux buts grâce à une politique active de promotion des logiciels libres dans l’éducation.
- Portugal 2 : 3 Danemark : Au premier abord, ces deux équipes semblaient au coude à coude. Cependant, le Danemark se démarque clairement avec une législation pro logiciels libres et standards ouverts, et une plateforme de téléchargement de tous les logiciels développés pour les gouvernement, délivrés sous licences libres.
- France – Roumanie : Ces deux pays ne se rencontrent que le 9 Octobre, mais le match promet d’être intéressant : tandis que la France se place parmi les équipes favorites de cette compétition avec un très fort engagement de plusieurs ministères et la migration déjà accomplie de l’Assemblées nationale, de la police et d’autres administrations majeures, la Roumanie se pose en fière opposante avec un premier pas très prometteur fait dans le domaine de l’éducation.
Prochaine grande notation le 12 Octobre, avec 22 matchs à venir ! D’ici là on attend deux match pour demain : Portugal – Danemark et Israel – Croatie…
Comme pour les dernières vagues de qualification, vous pouvez influencer les résultats de votre équipe favorite en ajoutant des informations sur le wiki jusqu’à la veille du match. Si vous n’avez pas encore de droits d’écriture, vous pouvez tout simplement créer un compte invité ou envoyer un message via identi.ca à Guido en mettant le tag “euro4fs”.
Notez également qu’à la suite de la campagne PDF readers, le nombre d’institutions publiques d’un pays qui auront retiré les publicités poru des lecteurs non libres de leurs sites internet sera également un facteur de victoire pour l’Euro 2012. Donc : plus vous reportez d’institutions, plus vous augmentez les chancesde votre gouvernement de gagner des points dans l’Euro 2012 (ceci indépendamment du fait que vous contribuez alors aussi à diminuer la distorsion de concurrence faite par ce biais par les gouvernements)
Pour voir les scores des matchs qui ont eu lieu jusque à présent, vous pouvez consulter la page de résultats sur le wiki.
Monday, 13 September 2010
Sus aux sites gouvernementaux !!!
En ce mois de rentrée, la FSFE vous propose une activité aussi atypique qu’utile :
![]()
La campagne PDFreaders reprend du service avec dans un premier temps une traque acharnée des publicités et recommandations d’utilisation de lecteur PDF non libres (Adobe reader, Foxit…) sur les pages gouverementales.
Le principe est simple : en principe, le gouvernement n’a pas à proposer exclusivement un unique programme pour lire les PDF quand des alternatives existent et que recommander ce même programme revient à le privilégier par rapport à ses concurrents sans justification aucune d’une telle préférence.Cela reviendrait à avoir un panneau devant la barre de péage d’une autoroute déclarant :
Que penseriez vous d’un panneau au bord de l’autoroute proclamant “vous avez besoin d’une Mercedes pour rouler sur cette aoutoroute. Contactez la concession Mercedes la plus proche pour un essai gratuit — Votre Gouvernement”.
De deux choses l’une :
– soit le gouvernement n’est pas conscient que ces recommandations sont un problèmes car il ne connait pas les alternatives, au quel cas la campagne ne peut que leur ouvrir les yeux et les amener à corriger cette erreur.
– soit le gouvernment fait délibérément de la publicité pour ces logiciels propriétaires, au quel cas il nous revient de leur expliquer pourquoi ils devraient préférer les logiciels libres et, tenter de les faire changer d’opinion.
Jusqu’au 17 Octobre, aidez nous à répertorier les pages gouvernementales concernées grâce à notre formulaire sur la page de la campagne. Vous pouvez aussi signer la pétition qui sera ensuite envoyée aux institutions répertoriées assortie d’une lettre explicative.
Nous comptons sur vous pour nous aider à établir une liste la plus exhaustive possible ! Les chercheurs les plus actifs se verront remettre un paquet surprise FSFE ainsi qu’une entrée gratuite à FSCONS.
Soyez les plus rapides à chasser sur les pages des sites de votre gouvernement !
Tuesday, 07 September 2010
Euro 2012 : les qualifications continuent !
Les résultats du troisième jour des qualifications de l’Euro 2012 est arrivé ! Guido a publié des résultats très précis pour les 27 matchs du jour.
- Alors que certains matchs du 3 Septembre ont montré que certains pays réalisent les mêmes performances au football que dans les logiciels libres (notamment les matchs Russie – Andorre et San Marin – Pays-Bas), la France continue à se démarquer comme une bien faible équipe de foot mais une administration très favorable aux logiciels libres. C’est cette fois au tour de la Bosnie-Herzégovine de s’incliner 3-1 face à l’équipe francaise.
- L’Autriche, qui s’est imposée 4-0 face au Kasachstan grâce à une politique pro- logiciels libres très active dans l’éducation et une migration claire de la ville de Vienne et la région de Linz.
- La Belgique maintient son niveau en gagnant 4-1 contre la Turquie qui marque sur un bel effort dans l’enseignement des logiciels libres à l’école.
- La Suède fait une percée remarquable en marquant 4 points contre la Principauté de San Marin, points bien mérités surtout depuis la déclaration officielle du format ODF (Open Document Format) comme standard national.
Une nouvelle vague de qualification aura lieu le 8 Octobre. Comme pour les matches de Septembre, vous pouvez influencer les résultats de votre équipe favorite en ajoutant des informations sur le wiki jusau’à la veille du match. Si vous n’avez pas encore de droits d’écriture, vous pouvez tout simplement créer un compte invité ou envoyer un message via identi.ca à Guido en mettant le tag “euro4fs”.
Sunday, 05 September 2010
Euro 2012 logiciels libres : premiers résultats…
Comme annoncé dans mon précédent post, les résultats des 22 premiers matchs de l’Euro 2012 des logiciels libres ont étés mis en ligne.
Les deux grands affrontements de cette première grande série de qualifications ont été
- Allemagne – Belgique : deux pays au très fort potentiel, qui ont déjà introduit les logiciels libres dans plusieurs de leurs administrations et où plusieurs vilels ont d’ores et déjà migré vers le logiciel libre. Le match a été très serré et Guido n’a pu départager les deux équipes que par quelques publications belges montrant que le concept des logiciels libres était mieux maitrisé là-bas.
- Estonie-Italie : Deux pays très forts dans des domaines différents : l’éducation pour l’Italie, le combat pour l’interoperabilité pour l’Estonie.
La France s’est quant à elle s’est imposée 3-0 face à un bien faible adversaire, la Biélorussie. Ce n’est cependant pas une victoire vaine, selon le bon proverbe de “à vaincre sans péril, on triomphe sans gloire”. De fait, la France a montré son engagement dans les logiciels libres dans l’éducation par plusieurs projets de distributions à des écoliers et collégiens, mais aussi a installé Linux à l‘Assemblée Nationale, plusieurs ministères (culture, agriculture…) ont entamé une migration vers les logiciels libres, la gendarmerie même s’y est mise dès 2005.
Une nouvelle vague de qualification aura lieu le 7 Septembre. Jusqu’à cette date, vous pouvez influencer les résultats de votre équipe favorite en ajoutant des informations sur le wiki. Si vous n’avez pas encore de droits d’écriture, vouspouvez tout simplement créer un compte invité ou envoyer un message via identi.ca à Guido en mettant le tag “euro4fs”.
Thursday, 26 August 2010
Coupe de l’UEFA 2012 : Ce que cela donne du côté des logiciels libres…
Le 11 août dernier, Guido a lancé une compétition parallèle au matchs qualificatifs de l’UEFA 2012. Le concept en est simple : On prend, l’ordre des matchs officiels, et on compare les performances des pays dans une toute autre discipline : l’utilisation de logiciels libres par les institutions publiques.
Au cours du match inaugural, l’Estonie s’est déjà qualifiée haut la main devant les Iles Féroes.
Le 3 Septembre auront eu lieu 22 matchs, ce qui met 44 pays en compétition. Une première évaluation est en cours, nous verrons alors ce que les équipes europénnes donnent quand on met leurs choix logiciels à l’épreuve…
Si vous voulez contribuer à la notation des équipes, aidez nous à rassembler des informations sur les différents pays, soit en me laissant un commentaire soit en les rajoutant directement au wiki.
Thursday, 19 August 2010
Les lycéens réunionnais passent sous GNU/Linux !

C’est en tout cas ce qu’a annoncé Didier Robert le président du conseil général de la Réunion. Dès octobre, les 18 000 premiers ordinateurs portables sous GNU/linux devraient être distribués aux lycéens de seconde. La volonté politique est claire: faire découvrir les systèmes alternatifs au plus grand nombre.
On ne peut que saluer cette initiative qui développera à coup sur la curiosité des adolescents pour les nouvelles technologies ainsi que pour le libre. Cependant, l’objectif de cette action doit être avant tout d’accompagner les enseignants vers un enseignement qui mêle intelligemment technologie et cours en classe. Il ne suffit pas de distribuer des ordinateurs pour améliorer l’éducation. Il faut aussi éduquer à de nouveaux usages. A quoi bon distribuer un ordinateur si personne n’en fait rien ?
J’espère qu’un projet éducatif accompagnera cette distribution d’ordinateur, sans quoi le risque d’inefficacité est grand.
Sources: chezeric.biz
Tuesday, 17 August 2010
L’Amateur versus le Professionnel

Je me suis souvent senti assez mal à l’aise dans des débats ou discussions où il est communément admis que le sens premier du mot « amateur » qualifie la piètre qualité d’une production. Ceci est d’autant plus vrai lorsque les partisans du « professionnalisme » se complaisent à dézinguer du logiciel libre.
Le professionnel est motivé par l’argent. Son objectif n’est pas de faire du travail de qualité, ce n’est pas non plus d’aimer ce qu’il fait. Le professionnel a pour but ultime de faire de l’argent.
Plutôt que de prendre le mot amateur dans son sens commun, je vous invite à retourner à ses sources latines pour en comprendre le sens original et mener une réflexion sur les valeurs profondes qui animent l’amateur.
Ama-teur signifie avant tout « celui qui aime »
Quand on construit ou produit quelque chose que l’on aime, alors on est un amateur. Souvent les contributeurs de projets libres sont des passionnés. Le moteur de la motivation qui pousse à s’activer est la passion, le jeu et la sociabilité.
Contribuer de manière amateur c’est aller à la rencontre de contributeurs qui partagent la même passion que vous. Il est stimulant de faire la rencontre de gens avec qui on a des affinités. Lorsque des amateurs ont une activité commune, les pairs poussent à faire des efforts. L’amateur ne cherche pas à reconduire son contrat comme le professionnel mais la reconnaissance de ses pairs.
Souvent on entend dire quand un travail est mal fait ou qu’un logiciel ne répond à des attentes « c’est un travail d’amateur ». Cette expression est employée de manière péjorative pour exprimer la médiocrité de la prestation du producteur. Or le travail d’amateur est-il toujours de mauvaise qualité ? A l’évidence, c’est faux. Et de nombreux exemples peuvent le démontrer: le projet wikipedia est composé à 99% amateur. Pareil pour GNU/Linux, les contributions viennent très souvent d’amateurs. Si l’amateur n’a pas de service « contrôle qualité », il a des pairs pour mettre à l’épreuve sa production et la critiquer.
L’amateur aime profondément ce qu’il construit. Les développeurs de logiciels libre sont très souvent des passionnés qui jouent avec le code. C’est grisant. On retrouve cette passion dans bien d’autres domaines comme la musique, l’art et j’en passe…
 Le professionnel fournit toujours des logiciels de qualité: un mythe ?
Le professionnel fournit toujours des logiciels de qualité: un mythe ?

Combien de fois ai-je pu être déçu par des services fournit par des professionnels ? Un téléphone qui ne fait pas deux ans, un service client pourri, un logiciel ou un jeu de mauvaise qualité… C’est fréquent, on n’y prête même plus garde. Quand un logiciel propriétaire est mauvais entend-t-on souvent « c’est normal, c’est un logiciel propriétaire ! ». Je ne l’entends jamais, à part de la bouche d’amis libriste bien sur Par contre, combien de fois ai-je entendu qu’un logiciel était de mauvaise qualité parce qu’il était libre… Je ne compte plus !
Si les projets de logiciels libres sont parfois de moins bonne qualité que leur équivalents propriétaires, ce n’est pas en raison de l’amateurisme de leur acteur. Le temps d’activité du professionnel est supérieur à celui du temps de l’amateur. Combien de contributeurs peuvent passer 80% de leur temps à avoir une activité de loisir ? Très peu à l’évidence. Il est indispensable d’avoir une activité professionnelle importante pour vivre ou survivre. Pour qu’un travail soit de qualité, il n’y a pas de secret, il faut y passer du temps. C’est a principale raison pour laquelle il n’est pas rare que la sphère professionnelle ait des productions de meilleures qualités.
Quelles solutions pour passer plus de temps à développer du logiciel libre ?
C’est une vaste question qui mériterait une série d’article à elle seule. Je me contenterais d’inviter les utilisateurs de logiciels à être généreux quand ils le peuvent en faisant des dons réguliers aux communautés qui développent les logiciels libres ou rendent des services amateurs.Même si l’amateur n’est pas rémunéré pour le travail qu’il fournit, rien ne vous empêche de lui faire des dons pour qu’il puisse accorder plus de temps aux services qu’il vous rend.
Saturday, 14 August 2010
Crab Grass: un logiciel libre d’organisation et de transformation social
 Depuis quelques semaines, je teste le logiciel libre Crab Grass une boite à outil militante de premier ordre sur les serveurs de Rise Up. Rise Up est une organisation qui a pour mission de proposer gratuitement des outils sécurisés aux collectifs et organisations solidaires. Rise Up propose le service we.riseup.net qui nous invite à utiliser Crab Grass. Ce logiciel libre est en plein développement, encore en beta mais déjà très intéressant et je vais vous le présenter en détail.
Depuis quelques semaines, je teste le logiciel libre Crab Grass une boite à outil militante de premier ordre sur les serveurs de Rise Up. Rise Up est une organisation qui a pour mission de proposer gratuitement des outils sécurisés aux collectifs et organisations solidaires. Rise Up propose le service we.riseup.net qui nous invite à utiliser Crab Grass. Ce logiciel libre est en plein développement, encore en beta mais déjà très intéressant et je vais vous le présenter en détail.
Crab Grass, une boite à outil de l’auto-organisation des acteurs
Bien que ne proposant pas d’outils de décentralisation comme MOVIM, Crab Grass est un logiciel extrêmement intéressant pour les citoyens engagés de tous bord. La dernière version a été rendu public le 14 juin dernier, il s’agit de la 0.5.2.1.
Crab Grass a selonrise up trois objets:
Un logiciel de réseaux sociaux, il a pour but de donner la capacité aux utilisateurs d’établir des liens entre eux au travers de leur contribution en ligne.
Un logiciel de travail collaboratif, il donne la capacité à de petits groupes de partager des fichiers, suivre des tâches et des projets, prendre des décisions et construire une base de connaissance.
Un logiciel d’organisation de réseau car il permet à de multiples groupes de travailler ensemble sur des projets dans un esprit démocratique.
Une organisation des discussions originale mais discutable
Les interactions sont organisées de manière assez originale et peu bordélique. On a l’impression que certaines fonctionnalités sont redondantes mais elles correspondent à des formats différents.
La première page quand on arrive sur le réseau est composé d’une barre de navigation, d’un tableau de bord et des pages récentes.
La barre de navigation

« la boite de réception » est une zone de notification nous prévenant de l’activité sur les pages discussions auxquelles nous participons.
« My messages » semble faire l’historique des mini-messages privés et publics. Je n’en ai eu que peu l’utilité jusqu’à maintenant mais il semble que cela corresponde aux status de twitter ou identi.ca.
« Tâches » recense l’ensemble des tâches que je me suis assigné ou que l’on m’a assigné. Très pratique pour savoir comment être utile et efficace !
« Les requêtes » Nous permet de visualiser les demande de mises en contact qui nous sont faites.
« Rechercher » est un moteur de recherche qui nous permet de trouver par mot clé.
« La poubelle » est l’espace où sont jetées les pages supprimées.
Juste en dessous du menu ce trouve la rubrique « Univers » où sont iconifiés les différents groupes de travail que vous avez rejoins et vos ami-e-s.
Ce menu est aussi décliné à l’horizontal dans l’entête quand vous passez votre souris sur « moi ».
Le tableau de bord est votre tour de contrôle et vous permet de visualiser l’activité des membres de votre groupe sur le groupe.

En dessous du tableau de bord, on visualise les pages récentes. Les petites étoiles marques celle qui sont importantes. Nous reviendrons sur leur nature un peu plus tard.

Des fonctionnalités intéressantes
On peut distinguer trois grandes fonctionnalités: les pages (la plus importante), les mini-messages et le t’chat.
Les pages peuvent correspondre à différents éléments.
Cela peut être une page…
« Wiki », page que tout le monde peut modifier. Utile pour travailler en collaboration sur des textes ou stocker des bases de connaissances communes pouvant être enrichies.
« discussions de groupes », cela prend la forme d’un topic de forum. Il s’agit de discussions asynchrones.
« Multimedia », vous aurez le choix entre fichiers, images et videos.
« votes et enquêtes », là il s’agit d’une panoplie d’outil dont l’objet est de sonder le groupe. Très utile pour prendre des décisions.
« Listes de tâches », la fameuse liste des tâches va permettre au groupe d’avoir une visibilité permanente sur les actions qui doivent être accomplie pour faire avancer le shmilblik.
Il y a de quoi faire.
Les mini-messages permettent d’envoyer rapidement et un publiquement une information à un autre membre ou au réseau en général. Cela peut faire office d’outil de veille même si je doute que l’on ai tout le temps les yeux rivés sur cette fonctionnalité.
Outil aussi très pratique: le t’chat. Il permettra au groupe de se réunir pour discuter en directe !
Les réseaux, les groupes et les comités
Maintenant que l’on a vu comment s’organisent les discussions et leur nature, on sait où cliquer pour accéder à quoi. Crab Grass permet une auto-organisation sur trois niveaux.
Généralement, on débute au niveau intermédiaire, c’est à dire le groupe. Quand on arrive sur Crab Grass, la première chose que l’on fait, c’est d’inviter les membres de son organisation ou de son collectif à rejoindre le groupe.
A l’intérieur du groupe il est possible de créer des commissions. Les commissions sont des sous-groupes à proprement parler avec toutes les fonctionnalités du groupe mais sur un espace séparé et hiérarchiquement dépendant du groupe. En cas de conflit, il est ainsi très facile de subdiviser un groupe pour partir sur des pistes différentes.
Les réseaux sont des mises en réseaux de groupes. Votre groupe aura l’occasion de côtoyer d’autre groupe et il arrivera peut être un moment donné où vous déciderez de travailler ensemble. Le réseau vous permettra de « connecter » vos groupes et de collaborer plus facilement.
Avis critique
Crab Grass est un logiciel libre épatant. L’idée est exceptionnelle, sa mise en place est loin d’être médiocre. Son organisation sur trois niveaux est d’un grand intérêt. Les fonctionnalités disponibles sont puissantes même s’il manque à mon avis un outil de veille et de partage de l’information efficace.
L’interface de navigation reste un poil complexe et demande une certaine capacité d’adaptation. Il est sans doute possible de la rendre plus ergonomique.
Je me dois de rappeler tout de même que le logiciel est encore en bêta malgré sa maturité importante. Il est d’ailleurs possible de contribuer par vos idées ou bien en aidant à son développement.
Je tire mon chapeau à l’équipe de Rise Up !
On se retrouve sur le réseau donc ?
- Le Service we.riseup.net
- Crab Grass
Wednesday, 14 July 2010
Début de stage …
Bonjour !
Je travaille à la FSFE depuis 2 semaines exactement aujourd’hui (et comme les bureaux sont à Berlin, on s’applique même le 14 Juillet  ) et j’inaugure aujourd’hui mon blog …
) et j’inaugure aujourd’hui mon blog …
A suivre mes pensées et lectures sur les logiciels libres, les standards ouverts et plus généralement des réflexions tournées vers la nouvelle économie institutionnelle et le knowledge managment …
Saturday, 26 June 2010
L’utilisation et le développement du logiciel libre menacé par l’ACTA

L’APRIL et La Quadrature ont rencontré les 8 fonctionnaires français chargés des négociations de l’ACTA. Pour rappel, l’ACTA est une négociation mondiale organisé de manière totalement opaque qui vise à lutter contre la contre-façon à tout prix.
Voici un extrait concernant directement le développement et l’utilisation du logiciel libre:
Aucun droit à l’interopérabilité des « mesures techniques de protection » (DRM). Les DRM sont un frein au développement et à l’utilisation des logiciels libres. Pour les utilisateurs de logiciels libres, la seule solution pour accéder légitimement à des œuvres prisonnières de ces « menottes numériques » est le contournement. Cette solution n’a pas été garantie par les négociateurs français : les utilisateurs et les développeurs de logiciels libres pourraient donc être, lors de la transposition de l’ACTA, de nouveau soumis à une pression juridique inacceptable.
Ce débat avait déjà été mis sur la table à plusieurs reprises en France. Il semble que la connerie française s’exporte vraiment bien.
Rappelons tout d’abord ce qu’est un DRM ou en GDN (Gestion des Droits Numériques), selon wikipedia:
La gestion des droits numériques ou GDN[1] (en anglais : Digital Rights Management – DRM) a pour objectif de contrôler l’utilisation qui est faite des œuvres numériques, par des mesures techniques de protection. Ces dispositifs peuvent s’appliquer à tous types de supports numériques physiques (disques, DVD, Blu-ray, logiciels…) ou de transmission (télédiffusion, services Internet…) grâce à un système d’accès conditionnel.
Comment est-t-il possible de soutenir la volonté d’imposer à tous un standard de fichier de protection qui, primo, restreint les libertés d’utilisation du fichier malgré son achat par l’utilisateur, deuxio, dont la technologie soit fermée et propriétaire et donc appartenant à une industrie susceptible de faire payer des royalties pour son intégration dans les divers logiciels. Les utilisateurs et développeurs de logiciel libre qui mettraient en place des systèmes de contournement pour assurer l’interopérabilité se verraient mis en cause juridiquement. Cette mesure est totalement disproportionnée et porterait une atteinte grave à la liberté logicielle des utilisateurs.
Si ce paragraphe du communiqué de l’APRIL et de La Quadrature était le seul point noir, nous pourrions être heureux… Malheureusement, le reste n’est pas mieux…
Wednesday, 16 June 2010
Entrez sur le planet de MOVIM
Si vous cherchiez un fil d’information pour tout savoir sur MOVIM, les réseaux sociaux libres et la confidentialité des données personnelles sur internet, arrêtez vous !
J’ai exactement ce qu’il vous faut:
![]()
Si vous bloguez sur ces sujets, vous êtes les bienvenus !
Information flash: Ce soir, à 20h00, réunion technique sur le salon jabber MOVIM.
A tout à l’heure.
Thursday, 10 June 2010
Movim, l’alternative facebook, émission « symbiose »
Voici l’émission « Symbiose » diffusée sur radio Libertaire. Au nom du projet et de la communauté MOVIM, Jérémie et moi sommes intervenus sur différents sujets. Tout d’abord les problèmes de confidentialité des données personnelles, la censure exercée par facebook, puis le projet MOVIM réseau social libre et décentralisé, ses caractéristiques, son avancement…
Téléchargez l’émission
L’émission est disponible sous licence creative commons 3.0 sauf les chansons d’Andrea Rocolini sous creative commons 2.0.
Retrouvezles podcasts des anciennes émissions « Symbiose ».
Mise à jour 30/12/2011
Monday, 22 March 2010
L’ACTA et la Société de l’Information, lutte de pouvoir et défi pour notre génération
Mise à jour 23/03 : Une version consolidée de l’ACTA datant du 18 janvier vient d’être révélée par la Quadrature du Net. Retrouvez le document complet en téléchargement (pdf) ici.
J’aime penser que parmi les éléments qui forgent une génération, les luttes politiques sont au premier plan. Chaque génération a ses luttes politiques, ses nouveaux enjeux, de même que chaque jeunesse a ses différends avec les générations précédentes, et ces différends ont également beaucoup à voir avec la façon dont chacun s’exprime. Ainsi, certains problèmes, formulés de façons totalement différentes, peuvent apparaître sous des angles inédits, et parfois même être surpassés.
Or, parmi les éléments qui aident à surpasser les problèmes politiques, les contextes économiques et socioculturels jouent un rôle déterminant. Mais au-delà, l’élément technologique est indéniablement primordial. D’ailleurs, le sens du mot “technologie” est lui-même vecteur de cette idée de génération. Ainsi, Alan Kay définit la technologie comme tout ce qui a été inventé après votre naissance ou bien tout ce qui ne fonctionne pas encore.
Évidemment, je ne dis rien d’extraordinaire ici… et je pense que c’est un truisme de dire que, sans le bond technologique que représente l’invention de l’imprimerie, la société de la Renaissance aurait peiné à voir le jour ; ou bien que sans les révolutions industrielles, les sociétés des XIXème et XXème siècles n’auraient pas été les mêmes, ou enfin dire que sans la télévision et la radio, nous vivrons dans un monde méconnaissable de celui qu’est le notre.
Si la technologie est tellement un vecteur de changement, c’est principalement par sa portée politique, plus précisément par les nouveaux rapports (de force) qu’elle permet d’instaurer (parfois de façon assez endogène). C’est bien pour cette raison qu’Internet, le Web et l’informatique, représentent un enjeu politique important, et amènent une ère numérique pour une société nouvelle, qu’on a tendance à nommer la société de l’information. On parle d’information, parce que ce terme représente bien ce que le numérique a de volatile et d’insaisissable.
Mais plus précisément, le bouleversement apporté par les TIC est double :
- elles changent notre façon de nous exprimer, de créer et d’échanger (exemples : twitter, ou les blogs, qui permettent à chacun de s’exprimer et de publier à destination du monde entier et de façon persistante)
- elles créent de l’information, partout. Tout objet est porteur d’une information, d’un élément immatériel, qu’on va traduire par des
0et des1. Tout est fichier disait Ken Thompson (exemples : le génome humain, qui n’est pas un code binaire mais quaternaire, l’ADN :A, C, T, G— ou encore la réalité augmentée).
La Société de l’Information, qui reste encore à venir, mais que nous construisons maintenant, est donc cette société où tout sera numérique. Le mouvement a déjà commencé avec les logiciels par exemple, alors mêmes que ceux-ci existaient bien avant l’avènement de l’informatique sur les ordinateurs (ainsi, le premier programme informatique a été écrit en 1843 par une femme, Ada Lovelace). Mais on voit déjà que cela s’étend à l’édition, la presse, la musique, la politique (voir l’initiative Regards Citoyens).

Or, il y a là un véritable enjeu de pouvoir, une lutte et un défi pour notre génération, celle qui doit construire une société de l’information qui soit aussi vecteur d’un meilleur-être. Le numérique créée un pan entier du savoir et de l’économie, sur lequel plusieurs acteurs prétendent à décider.
L’ACTA, l’accord commercial anti-contrefaçon, est un de ces textes politiques internationaux qui changent le monde, celui d’une génération contre une autre.
Ce mois-ci, Le Monde Diplomatique posait cette question en première page : La propriété intellectuelle est-elle le pétrole du XXIe siècle ?
J’aime beaucoup cette analogie. Comme le pétrole, la propriété intellectuelle est vouée à disparaître. Comme le pétrole, ses effets néfastes sur notre écologie (intellectuelle) sont décriés chaque jour, et comme le pétrole, la propriété intellectuelle créée des guerres nouvelles, parce qu’il est moteur d’activité économique et de profits pour certains.
Si la guerre économique est en place depuis des décennies, par exemple sur les logiciels où elle prend la forme du combat entres les logiciels libres et les logiciels privateurs – la guerre politique est elle en train de se mettre en place avec l’ACTA au niveau mondial.
L’ACTA est un traité commercial négocié secrètement depuis Octobre 2007 par les États-Unis, l’Union Européenne, le Japon, le Canada, la Nouvelle-Zélande, l’Australie, la Corée, le Mexique, le Maroc, Singapour et la Suisse, des pays riches majoritairement de l’hémisphère nord. Il vise à instaurer au niveau mondial un régime commercial tyrannique, où la matraque est la propriété intellectuelle. Or justement, qu’est-ce que la propriété intellectuelle ? C’est un mirage, une construction idéologique qui vise à imputer l’humanité d’une partie essentielle de son savoir aux profits d’intérêts privés. Et cette idéologie prend parfois les plus beaux habits pour s’ériger en protectrice des inventeurs, des auteurs ou garante de démocratie. Comme avec toute idéologie, la bataille des mots est primordiale.
Si j’utilise moi-même le mot de guerre ici, c’est bien parce que celle-ci est la continuation de la politique par d’autres moyens. Or il est établi aujourd’hui dans notre société que le lieu de la politique doit être celui du débat républicain et démocratique. En bafouant tous les principes démocratiques nationaux, les traités comme l’ACTA sont donc des guerres, avec des victimes réelles et des crimes, des morts mêmes. Car en effet, l’ACTA veut couvrir tous les “droits” de la propriété intellectuelle, y compris les brevets sur les médicaments donc. Mais les brevets aujourd’hui, nous les trouvons aussi sur le génome humain, ou bien dans l’agriculture avec les OGM. Nous les trouvons dans les logiciels (aux États-Unis), et certains veulent étendre leur spectre en Europe aux logiciels, aux business methods et aux biotechnologies.

Comme le note Philippe Rivière, [I]l est à craindre que le cas, constaté à plusieurs reprises, de containers de médicaments génériques fabriqués en Inde, exportés à destination de pays pauvres, et que la douane avait interceptés au cours de leurs transit via des ports européens, ne devienne la norme. ACTA : chapitre deux, Le Monde Diplomatique
Ainsi, les pages de ce projet de traité international confirment les craintes soulevées par le manque de transparence de son élaboration.
Négocié par une coalition ad hoc des pays les plus riches de la planète, le texte est une sorte de coup d’État contre l’Organisation mondiale de la propriété intellectuelle (OMPI), suspectée de ne plus être assez “dure” (lire l’article de Florent Latrive dans Le Monde diplomatique de mars, encore en kiosques). Le texte, par ses “arrangements institutionnels”, prévoit de fait d’établir une institution anticontrefaçon parallèle, faite à la main des promoteurs de l’accord [3].
L’ACTA adopte une position maximaliste en matière de “protection” de la propriété intellectuelle, sans tenir compte des arbitrages sur lesquels reposent toutes les lois en la matière, et qui doivent traditionnellement concilier protection des créateurs et droits du public. Le texte vise ainsi à annuler de nombreux acquis, juridiques et politiques, que les grands comptes de l’économie dite “immatérielle” (musique, cinéma, logiciels, industrie pharmarceutique, luxe…) perçoivent comme des obstacles à leur puissance.
En ce qui concerne l’Internet, l’ACTA exigerait de chacun de ses signataires l’adoption de mesures de type “Hadopi”, où un foyer dont l’adresse IP est détectée comme “pirate” verrait son accès restreint après trois avertissements. Il demande aussi à ses signataires de prévoir des charges pénales pour l’”incitation, l’assistance et la complicité” de contrefaçon, “au moins dans les cas de contrefaçon volontaire de marque et de droit d’auteur ou des droits connexes, et du piratage à l’échelle commerciale”. Ce qui permettrait, de fait, de criminaliser tout système ou plate-forme permettant la copie numérique, de la même manière que, dans les années 1980, les lobbies de Hollywood avaient tenté d’interdire… les magnétoscopes. Avec l’extension qu’a prise depuis lors la sphère numérique, toute l’informatique domestique serait dans le collimateur, avec au premier rang les logiciels libres, par définition incontrôlables. Comme le note James Love sur le blog de Knowledge Ecology International, « “l’échelle commerciale” est définie comme s’étendant à tout système de grande ampleur, indépendamment de la “motivation directe ou indirecte au gain financier” [4] ». Un moteur de recherche qui permettrait de localiser des fichiers illicites serait donc directement visé. C’est ce qu’on appelle le modèle de l’internet chinois [5].
Mais toutes ces manœuvres, entre diplomates, entre négociateurs officiels, avec ses accords de non-divulgation qui met aussi autour de la table les grandes industries, c’est oublier que cette manière de faire de la politique est en train d’être dépassée. La politique, tout comme la politique internationale, ne se fait plus seulement entre États. Elle se fait aussi avec les entreprises multinationales, ça ils l’ont bien compris. Mais elle se fait aussi avec les citoyens, avec les ONG, avec des outils nouveaux et inédits. Souvenons-nous ô combien nos hommes/femmes politiques se sont tous félicités des mouvements de protestation en Iran, propagés largement par le Web, par ces vidéos, par Twitter. Ça c’est l’exemple médiatique.
Mais n’oublions pas qu’à l’ONU, les ONG sont de plus en plus souvent prises en compte. Un traité récemment entré en vigueur (même si resté non signé par les États-Unis) qui interdit l’utilisation des bombes à sous-munitions, est une initiative émanant d’Handicap International. Enfin, pensez-vous que le fiasco qu’a été le sommet de Copenhague aurait été perçu de la même manière sans l’influence de nouvelles formes de communications et de nouveaux médias, notamment sur le Web ? Je ne le pense pas. Mais si on compare l’organisation de ce sommet, ouverte aux ONG et plutôt démocratique, avec l’organisation des G20 ou des G8 par exemple, ne trouvez-vous pas que l’impression générale qui est donnée à l’opinion publique est intrigante et plutôt éloigné de la réalité (on a changé le système capitaliste financier, on a mis fin aux paradis fiscaux… lol) ?
À l’OMPI, la main-mise des grands groupes industriels est terminée. Celle-ci est depuis quelques années en profonde rénovation, sous l’influence de pays comme le Brésil et l’Argentine, mais aussi depuis son ouverture aux ONG, comme à Knowledge Ecology International ou à la Free Software Foundation Europe. Cette volonté avec l’ACTA de contourner cette assemblée, pourtant déjà peu démocratique, c’est faire violence à toute cette évolution, ce progrès.
Et justement, il faut que cette tentative soit vaine. On l’a dit, l’ACTA est négocié en secret depuis 2007 (au moment où la directive européenne IPRED2, Criminalisation des infractions à la propriété intellectuelle s’enlise). Heureusement, cela n’a pas empêché des fuites à répétition des documents de négociation. Chaque mois, plusieurs documents parviennent au public et révèlent les intentions nauséabondes des négociateurs de l’ACTA. C’est là l’une des caractéristiques les plus intéressantes de cette lutte de génération. Les outils que nous utilisons en partie pour nous défendre, sont parmi les outils qui justement sont la cibles de ce traité. Or ces outils, nous les utilisons au quotidien, pour nous exprimer, partager des idées, des images, des vidéos. Nous travaillons avec. Nous allons innover avec et nous allons entrer en compétition avec d’autres.
Ma conviction est que nous n’avons en aucune manière le droit de nous laisser piétiner et traiter de criminels lorsque nous nous révolterons de ne pas être libres de partager, de créer, de nous soigner ou de nourrir la planète.
Informez-vous !
Lien
- La Quadrature du Net
- Knowledge Ecology International (en)
- Michael Geist on ACTA (en)
- Le Monde Diplomatique : Propriété intellectuelle
- Act Up
- We Rebuild : ACTA
- Mes documents sur l’ACTA
Vidéo
Télécharger (OGG) ou (MP4) à voir sur Save Jim.com
Friday, 11 September 2009
Weekly Digest 09/04 to 09/10
The thing that shocked me the most this week is without any doubt this article in Tech Crunch about a future device called “Life Recorder” (I already imagine the Apple iLife advertisement campaign). Inspired by a Microsoft Research product called Sensecam, the camera would be attached to our body and record everything we do, and synchronizing it online.
“Imagine an entire lifetime recorded and searchable. Imagine if you could scroll and search through the lives of your ancestors.�
I have to admit, I first thought it was a hoax. My surprise was that it was real… and that actually, people would like it! Comments were far more frightening…
“It would be boring as I spend a great deal of my life on the computer, but regardless I would see no problem in its ‘invasion of privacy’. I rarely do anything I need to keep secret and as such dont care. However, I do forget things very often and would love such a device for that reason. I am also a social networking addict and update my status/location all the time along with pictures if I am able.�
See the discussion going on… and certainly a blog post about that where I’ll give you my point of view about that!
Day-by-day…
2009-09-04
-
ceux qu’ont pas GnuNet http://www.gnunet.org/download.php3?xlang=French, je transmets Finkielkraut http://ur1.ca/b4os ogg:http://ur1.ca/b4p2
-
Finkielkraut aime le P2P (GnuNet : http://ur1.ca/b4or )
-
@manhack L’internet et les ‘pédo-nazis’ : best of vidéo des JT qui parlaient du Net dans les 90’s http://ur1.ca/b44o (in context)
2009-09-05
![]()
-
Il va encore falloir leur expliquer. http://ur1.ca/b7an
-
le navigateur le plus rapide du monde
http://www.uzbl.org/ !fs philosophie UNIX -
2 juges Cour suprême “l’exécution d’un homme ayant prouvé son innocence restait valable [si] procès juste et équitable.â€� http://ur1.ca/b77n
-
Is there any difference between firefox and gnu icecat apart from addons and trademark issues? http://gnuzilla.gnu.org !freesoftware
-
quelles licences pour le Saas (software as a service) ? http://ur1.ca/b715 http://ur1.ca/b716
2009-09-07
-
allez les développeurs, au boulot
faites mieux que juick.com / identi.ca réunis http://ur1.ca/b9pa -
RD: @taziden http://identi.ca/user/47293: To follow Telecoms Package Seminar LIVE NOW : http://tr.im/y5aX SPREAD THE LINK !!
2009-09-08
-
la vidéosurveillance, c’est aussi “l’institutionnalisation, et la technologisation, du délit de faciès“ http://ur1.ca/bbhf
-
Ending the War on Sharing — Richard Stallman http://ur1.ca/bbfb (en français http://ur1.ca/bbfc)
-
RT @bayartb L’enregistrement de mon intervention de dimanche sur radio libertaire dispo en ligne: http://x.fdn.fr/rl1 #hadopi #FDN fdn.fr
-
@manhack Le plus effrayant ce sont les commentaires ! Mais ils sont tous tarés/débiles/aveugles ou quoi? http://ur1.ca/bb80 (in context)
-
@manhack euh… c’est un canular ? (in context)
2009-09-09
-
“être anti-hadopi c’est un totalitarisme de voleurs planqués derrière leurs écrans” http://ur1.ca/be4o
-
Tday is 9/9/9 – the Day of the no-Beast
#ironmaiden -
@manhack non le PPH et le PP ont fusionné. Et le “PPF” n’est pas vraiment un parti, mais une parodie de parti politique.
2009-09-10
-
@fcouchet Merci pour ces commentaires en direct, c’est comme si on était offusqué avec toi
(in context) -
première lettre d’information de l’année envoyée! @libnum !freesoftware (Association Libertés Numériques)